1. 哈希产生的背景
- 问题:
- 在开发过程中,我们经常需要判断一个元素是不是在一个集合里;
- 比如:我们现在有个爬虫,已经抓了 十亿 个 url,我们在接下来的抓取过程中,需要先判断 url 是否已经被爬过了,如果 url 已经下载过了那我们就不再爬取,那如何实现该逻辑呢?
- 思路:
- 一般的思路是将所有元素保存起来,然后将对象和所有元素的集合进行比对,链表、树等等数据结构都是这种思路;
- 但是这种思路有个问题,随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也会越来越慢,简言之:资源浪费、性能低下;
试想一下:
- 假设我们在 redis 中使用指纹完成去重过程,一个去重指纹我们按照 40Bytes 来计算, 8GB(8GB=8589934592Bytes)的内存大约可以存储 214,748,000(2亿)个指纹;
- 按照这样计算的话,如果我们的 url 数量达到十亿级的话,需要去重的指纹占用空间将达到 40GB,这对于服务器内存来说将是一场灾难;
- 针对上面的问题,我们不禁要问什么样的数据结构,可以解决 元素增加、存储空间增大、检索速度下降 这个问题呢?
- 这里,我们引入一种叫作哈希表(Hash table)的数据结构,它可以通过一个 Hash 函数将一个元素映射成一个位阵列(Bit Array)中的一个点,检索时我们只要看看这个点是不是 1 就知道可以集合中有没有它了;
- 具体来说:
- 之前的查找是这样一种思路:集合中拿出来一个元素,看看是否与我们要找的相等,如果不等就缩小范围继续查找,经典二叉树查、冒泡查找找其实都是为了尽可能缩小查找对象;
- 哈希表是完全另外一种思路:当我知道 key 值以后,我就可以直接计算出这个元素在集合中的位置,然后到这个位置里找到这个元素,不需要像上面那样把所有元素当做潜在查找对象;
- 哈希的核心作用:
- 哈希的核心作用,是使元素的存储位置与它的关键码之间能够建立一一映射的关系,在查找时通过该函数可以很快找到该元素;
- 举个例子:如果全部数据是由一个个房屋组成的居民区的话,哈希就像是一个 门牌号地址生成器,给每一栋房子生成一个独一无二的 门牌号地址,当想要找某栋房屋的时候,只需要通过它的 门牌号地址 就可以知道这栋房子在什么地方,然后就能快速的找到这栋房子。
2. 哈希函数
- 定义:
- 给定表 M 存在函数 f(key),对任意给定的关键字值 key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表 M 为哈希(Hash)表,函数 f(key) 为哈希(Hash)函数;
- 理解:
- 哈希表(Hash table),也叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构,也就是说它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
- 这个映射函数叫做 哈希函数(散列函数),存放记录的数组叫做 哈希表(散列表);
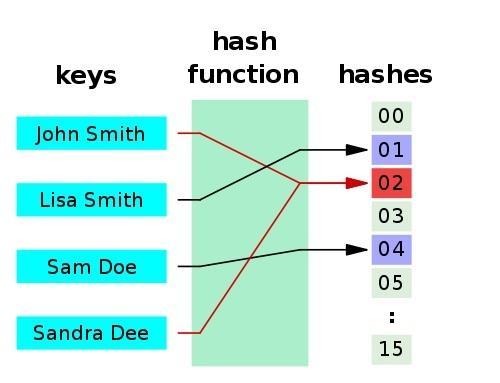
- 构造哈希函数的原则是:
- 函数本身便于计算;
- 计算出来的地址分布均匀,即对任意输入 k、f(k) 对应不同地址的概率相等,目的是尽可能减少冲突;
- 哈希函数构造方法:
- 数字分析法,如数值取模;
- 平方取中法;
- 分段叠加法;
- 除留余数法;
- 伪随机数法;
- 最典型的哈希函数是 取模法,即 H(key) = key % p,p <= m,(m 为所有元素的个数,另外 p 可以为小于等于 m 的最大素数);
如欲详细了解,请参阅《https://www.cnblogs.com/zzdbullet/p/10512670.html》文章中 哈希函数的构造方法 相关章节内容,此处不赘述。
3. 哈希的散列性
- 哈希表之所以又叫 散列表,是因为哈希函数具有散列性;
- 哈希函数的散列性,指的是不同输入会均匀分布在输出域上;
- 哈希函数的作用,就是努力的把比较大的数据指向相对较小的空间中;
举个栗子:
- 输入 0-99 的 100 个数字,用哈希函数除 3 取模那输出域就是 0、1、2;
- 当我们将这 100 个数字通过哈希函数进行映射后,0、1、2 的数量都会接近 33 个,也就是分布比较均匀;
- 哈希散列性的经典应用:
- 场景:如果现在有一个超级大的文件,需要统计其中重复的字符串 ,我们要怎么办?
- 已知:可以供给1000台计算机;
- 思路:可以使用哈希的散列性对这个超大文件分流;
- 具体操作:对大文件进行多行读取,每一行都计算哈希值,并取模 1000,则这些字符串均匀分布在 0-999 范围内;
- 给电脑编号 0-999,对应分布在一个范围内的一些字符串用同一台电脑进行处理,达到大数据分流的效果;
- 每台电脑只统计自己处理的重复字符串,最后将结果进行汇总。
| 电脑编号 | 文件行号 |
|---|---|
| 000 | 第 0 行、第 1000 行、第 2000 行、第 3000 行、第 4000 行、… |
| 001 | 第 1 行、第 1001 行、第 2001 行、第 3001 行、第 4001 行、… |
| 002 | 第 2 行、第 1002 行、第 2002 行、第 3002 行、第 4002 行、… |
| 003 | 第 3 行、第 1003 行、第 2003 行、第 3003 行、第 4003 行、… |
| 004 | 第 4 行、第 1004 行、第 2004 行、第 3004 行、第 4004 行、… |
| … | … |
| 995 | 第 995 行、第 1995 行、第 2995 行、第 3995 行、第 4995 行、… |
| 996 | 第 996 行、第 1996 行、第 2996 行、第 3996 行、第 4996 行、… |
| 997 | 第 997 行、第 1997 行、第 2997 行、第 3997 行、第 4997 行、… |
| 998 | 第 998 行、第 1998 行、第 2998 行、第 3998 行、第 4998 行、… |
| 999 | 第 999 行、第 1999 行、第 2999 行、第 3999 行、第 4999 行、… |
4. 哈希函数特点
- 输入的值范围可以无穷大,比如数据库记录;
- 输出的值范围却是有限的,比如上面的 0 到 999;
- 输入相同输出肯定相同;
- 输入不相同输出也可能相同(哈希冲突);
5. 哈希冲突
- 哈希冲突,简言之就是 输入不同,但有可能得到相同的输出;
- 哈希冲突是 Hash 最大的问题;
5.1. 哈希冲突产生的原因
- 为什么会有哈希冲突呢?其实就是因为哈希函数对输入值进行映射的时候,哈希表的位桶的数目远小于输入的关键字的个数,所以对于输入域的关键字来说,很可能会产生这样一种输入不同、输出却相同的情况;
- 用个形象一点的比喻来说,就是饭店来了 100 个客人,但店里却只有 10 个位置,那么每个作为上要安排 10 个人,这 10 个人在一个位子上怎么坐得下呢?这就是哈希冲突的原因。
5.2. 哈希冲突的解决方法
- 开放地址法:
- 用开放地址处理冲突就是当冲突发生时,形成一个地址序列,沿着这个序列逐个深测,直到找到一个“空”的开放地址,将发生冲突的关键字值存放到该地址中去;
- 链地址法:
- 把所有关键字为同义词的记录存储在一个线性链表中,这个链表成为同义词链表,即把具有相同哈希地址的关键字值存放在同义链表中;
- 再哈希法:
- 再哈希法其实很简单,就是再使用哈希函数去散列一个输入的时候,输出是同一个位置就再次哈希,直至不发生冲突位置,但这样有一个缺点,每次冲突都要重新哈希,计算时间可能会增加,而且增幅不可控;
- 公共溢出区法
- 公共溢出区法,将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表;
6 哈希的空间复杂度太高(内存溢出)
- 前面我们简单介绍哈希冲突以及冲突的解决方法,其实都是在为这个结论做铺垫;
- 哈希表的空间效率不够高,这是由哈希函数和哈希冲突处理的方法决定的,一般来说 哈希冲突越低,哈希的效率越高;
- 如何降低哈希冲突呢?在实际工作中,往往需要采用大于实际存储数据数量的哈希表,本质上来说其实就是 以空间换时间;
关于哈希空间复杂度,网上的解释并不是太多,也不够清晰准确,感兴趣的朋友可以参考《数据结构之——什么是哈希表?(哈希表是一个以空间换取时间的数据结构!!! 加快查找速度!!!)》一文,该文对用开放地址法解决哈希冲突做一个相对来说比较详细的解说。