用户画像系统数据流向
-
用户画像数仓架构
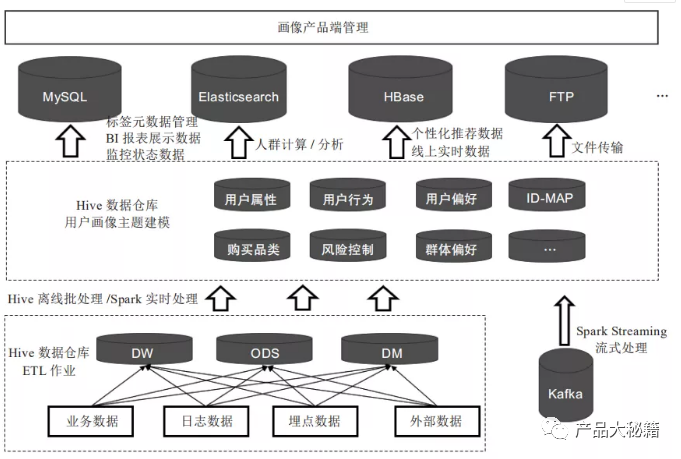
- 用户画像系统数仓 ETL 加工流程,是将业务数据、日志数据、埋点数据等经过 ETL 过程,加工到数据仓库对应的 ODS 层、DW 层、DM 层中;
- 中间的虚线框即为用户画像建模的主要环节,是对基于数据仓库 ODS 层、DW 层、DM 层中与用户相关数据的二次建模加工;
- 在 ETL 过程中将用户标签计算结果写入 Hive,由于不同数据库有不同的应用场景,后续需要进一步将数据同步到MySQL、HBase、Elasticsearch 等数据库中;
从 Hive 同步标签数据到 HBase
- 用户画像系统中,Hive 作为数仓、在 ADS 层存储用户标签计算结果;
- 用户标签数据在 Hive 中加工完成后:
- 一部分标签通过 Sqoop 同步到 MySQL 数据库,提供用于 BI 报表展示的数据、多维透视分析数据、圈人服务数据;
- 另一部分标签同步到HBase数据库用于产品的线上个性化推荐。
HBase 标签同步应用场景
-
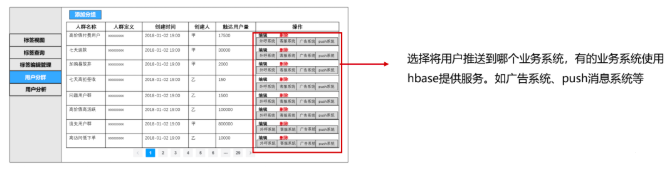
例如:圈人服务
- 人群圈选,即通过组合标签查询对应的用户人群;
- 首先,通过组合标签的条件,在 Elasticsearch 中查询对应的索引数据;
-
然后,通过索引数据去 HBase 中批量获取 row key 对应的数据。
-
业务方根据规则圈定人群后,进一步通过分析、明确该人群是其要运营的人群后,将该人群推送到相应的业务系统中;
-
工程调度流程

HBase 标签同步方案
- 注意
- 创建 hbase 表,需要创建好预分区
- 映射表
- 方案
- hive 和 hbase 的表建立映射关系;
- 读取的是同一份 HDFS 文件,只是在上层建立 hbase 到 hive 表的映射。
- 优点
- 一份数据存储,两种查询模式,数据存储最低;
- 缺点
- 底层还是格式化的 HDFS 文件,查询需要进行映射转换,效率较低;
- 方案
- bulkload 导入
- 方案
- 将 hive 的数据生成 hfile;
- 通过 bulkload 导入到 hbase
- 这样底层数据的格式会转变成 Hfile,存储在 hbase中;
- 将 hbase 完全作为一个数据库去查询;
- 优点
- 查询效率高;
- 缺点
- 同一份数据,两份存储格式,空间换取时间;
- 方案
HBase 同步需校验数据
- 因为灌入到 HBase 中的数据一般直接应用到线上,反馈到用户那里;
- 所以,在hive数据同步 HBase 数据的时候,需要做一些校验机制来保障结果的准确性,防止在同步数据的过程中出现问题;
- 比如:hive 中数据 5000 万条,同步到 HBase 后才 1000 万条;
HBase 标签同步数据校验方案
- temp 临时表
- hive 到 HBase 同步数据后,先 HBase 中建立一个 temp 临时表;
- 然后校验 HBase 的这个临时表和对应 hive 表的数量差异;
- 如果在可接受范围内,则将 hbase 的该临时表进行重命名为正式表;
- 状态表
- hive 到 hbase 同步数据后,直接将数据写入正式表,同时在 hbase 中建立一张状态表,用于标志状态位;
- 当校验 hbase 的这张正式表和 hive 的数量差异在可接受范围内时,写入对应的状态表中;
- 接口请求时,只读取状态位这张表中,最近日期的那张表
- 如果 hbase 的数据同步异常,不会写入状态表中,也不会影响线上数据的读取;