标签模型开发流程
- 标签开发,是用户画像工程化的重点模块,包含统计类、规则类、挖掘类、流式计算类标签的开发,以及人群计算功能的开发,打通画像数据和各业务系统之间的通路,提供接口服务等开发内容。
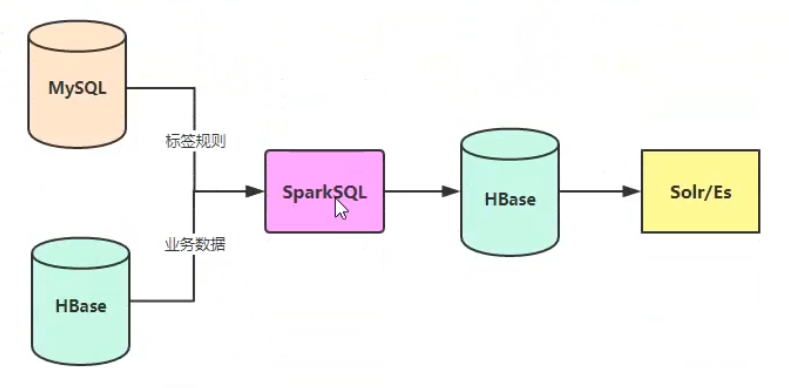
- 标签建模
- 所有的离线标签系统,都需要两个核心模型:
- 离线标签
- 用户维表
- 所有的离线标签系统,都需要两个核心模型:
- 读取数据:
- 从 MySQL 数据库中读取标签规则数据;
- 从 HBase 表中获取原始数据;
- 在此之前,如果原始数据存储于 Hive,可以用 bulkload 将数据导入 HBase;
- 计算标签:
- 基于 SparkSQL 计算得到标签结果;
-
每个标签,对应一个应用程序。需要一个标签,就开发一套 Spark 程序。如果不再使用标签,则直接停止该程序;
- 数据落表:
- 标签结果数据,存储到 HBase;
- 基于 ES 做二级索引以方便查找;
标签模型
标签建模
- 离线标签
- 画像系统的标签,分为离线标签和实时标签。
- 离线标签又分为基于统计类型的标签和基于算法性标签,大部分或者 90% 的标签都是统计类型标签;
- 机器学习的算法标签很少:
- 一方面是因为开发周期很长,
- 另一方面效果也有限。
- 但是基于某些场景,还是得需要使用机器学习,只是机器学习标签的比重会很小。
- 有时我们做实时数据支持,会通过实时数据流给用户做刻画或者做特征标记,可做线上服务接口调用查询。
- 用户维表
- 用户维表是一张大宽表,大宽表基于筛选用户的属性或分析师分析用户的时候用。除了标签跑批、用户维表,还有人群计算、行为数据等的数据开发。
模型示例
- 标签表上的每条记录,与模型表中的记录,是一一对应的。
- 标签表
CREATE TABLE `tbl_basic_tag` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '标签ID', `name` varchar(50) DEFAULT NULL COMMENT '标签名称', `industry` varchar(30) DEFAULT NULL COMMENT '行业、子行业、业务类型、标签、属性', `rule` varchar(300) DEFAULT NULL COMMENT '标签规则', `business` varchar(100) DEFAULT NULL COMMENT '业务描述', `level` int(11) DEFAULT NULL COMMENT '标签等级', `pid` bigint(20) DEFAULT NULL COMMENT '父标签ID', `ctime` datetime DEFAULT NULL COMMENT '创建时间', `utime` datetime DEFAULT NULL COMMENT '修改时间', `state` int(11) DEFAULT NULL COMMENT '状态:1申请中、2开发中、3开发完成、4已上线、5已下线、6已禁用', `remark` varchar(100) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=233 DEFAULT CHARSET=utf8 COMMENT='基础标签表'; - 模型表
- 详细记录标签模型 application 的位置;
CREATE TABLE `tbl_model` ( `id` bigint(20) DEFAULT NULL, `tag_id` bigint(20) DEFAULT NULL COMMENT '标签ID', `type` int(11) DEFAULT NULL COMMENT '算法类型:统计-Statistics、规则匹配-Match、挖掘-具体算法-DecisionTree', `model_name` varchar(200) DEFAULT NULL COMMENT '模型名称', `model_main` varchar(200) DEFAULT NULL COMMENT '模型运行主类名称', `model_path` varchar(200) DEFAULT NULL COMMENT '模型JAR包HDFS路径', `sche_time` varchar(200) DEFAULT NULL COMMENT '模型调度时间', `ctime` datetime DEFAULT NULL COMMENT '创建模型时间戳', `utime` datetime DEFAULT NULL COMMENT '更新模型时间戳', `state` int(11) DEFAULT NULL COMMENT '模型状态,1:运行;0:停止', `remark` varchar(100) DEFAULT NULL, `operator` varchar(100) DEFAULT NULL, `operation` varchar(100) DEFAULT NULL, `args` varchar(100) DEFAULT NULL COMMENT '模型运行应用配置参数,如资源配置参数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 详细记录标签模型 application 的位置;
Spark 计算引擎
Spark 计算标签数据的优势
- 计算速度比较快
- Spark 是内存计算,整个流程的处理时间相对Hadoop减少5~10倍。
-
Spark 支持多种数据源
- Spark 提供了非常丰富的数据处理操作:
- Map & reduce
- filter
- join
- cogroup,
- scala 语言简洁,使得代码量大为减少。
Spark 计算标签的不足
- 人群投影问题:
- 两个数据集 (RDD) A、B,其中:
- A 是全量数据,包括id和标签;
- B 数据集只包含 id;
- 需要知道 B 数据集中有多少 id 在 A 中存在,以及需要知道存在的 id 的标签统计结果,根据 id 对 A、B 俩数据集进行 join 来过滤出在 A、B 中同时存在的 id,然后再统计这些 id 各标签的数量;
- 两个数据集 (RDD) A、B,其中:
- Spark 原生的 join 会对两个 RDD 都进行一次 shuffle,每个 worker 将数据根据 hash 值重新分发到各 worker 上,由于 A 数据集是全量数据、量非常大,而且常驻内存、而且一天才更新一次,这样系统开销很大;
- 解决思路:
- 不需要每次计算时都要对它进行 shuffle,而是可以先对 A 数据集进行 Shuffle 并且在每个 partition 上按照 id 排好序;
- 这样 A 和 B 进行 join 时、A 不用 shuffle,只需要将 B 按照同样的 hash 算法 Shuffle 然后排序,再按序遍历 A 和 B 相同的 partition,就能过滤出 AB 中同时存在的 id。
- 类似于做好工作后,求两个有序数组的交集,只需 O(M+N) 的时间就够。
模型开发示例
需求描述
- 示例:开发一个统计型标签,计算用户的客单价。
- 客单价就是一个客户所有的订单金额/订单数量;
- 简单说就是需要统计每个用户每笔订单所花的钱。
创建 SparkSession
- 因为我们汇总计算需要使用到 SparkSQL,所以我们需要先创建 SparkSQL 的运行环境。
- 为了方便我们后期运行时查看控制台,我们可以设置一下日志级别。 ``` val spark: SparkSession = SparkSession.builder().appName(“AgeTag”).master(“local[*]”).getOrCreate()
// 设置日志级别 spark.sparkContext.setLogLevel(“WARN”)
#### JDBC 连接 MySQL
- 这里采用 Spark 通过 jdbc 的方式连接 MySQL。
```
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
// 连接MySQL
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
```
#### 读取 MySQL 数据库四级标签的数据
- 因为后续可能需要对读取的数据,做一些形式上的转换,所以这里先引入了隐式转换和 SparkSQL 的内置函数,然后根据 MySQL 的连接对象,读取了四级标签的数据,并对其做了一定的处理。
```
// 引入隐式转换
import spark.implicits._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
//读取MySQL数据库的四级标签
val fourTagsDS: Dataset[Row] = mysqlConn.select("rule").where("id=137")
// 对四级标签数据做处理
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule值
val RuleValue: String = row.getAs("rule").toString
// 使用"##"对数据进行切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
// 将Map 转换成HBaseMeta的样例类
val hbaseMeta: HBaseMeta = toHBaseMeta(KVMap)
```
- 因为涉及到了样例类的调用,这里提前写好了样例类。
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse(HBaseMeta.ZKHOSTS,""),
KVMap.getOrElse(HBaseMeta.ZKPORT,""),
KVMap.getOrElse(HBaseMeta.HBASETABLE,""),
KVMap.getOrElse(HBaseMeta.FAMILY,""),
KVMap.getOrElse(HBaseMeta.SELECTFIELDS,""),
KVMap.getOrElse(HBaseMeta.ROWKEY,"")
)
} ```
读取 MySQL 数据库五级标签的数据
- 上一步,已经读取完了四级标签,这一步需要读取 MySQL 中五级标签的数据,也就是标签值的数据。 同样,再读取完之后,需要对数据进行处理。
-
因为标签值是一个范围的数据,例如 1-999,需要将这个范围的开始和结束的数字获取到,然后将其添加为 DataFrame 的 Schema,方便后期对其与 Hbase 数据进行关联查询的时候获取到区间起始数据。
val fiveTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("pid=137") val fiveTagDF: DataFrame = fiveTagsDS.map(row => { // row 是一条数据 // 获取出id 和 rule val id: Int = row.getAs("id").toString.toInt val rule: String = row.getAs("rule").toString //133 1-999 //134 1000-2999 var start: String = "" var end: String = "" val arr: Array[String] = rule.split("-") if (arr != null && arr.length == 2) { start = arr(0) end = arr(1) } // 封装 (id, start, end) }).toDF("id", "start", "end") fiveTagDF.show() //+---+-----+----+ //| id|start| end| //+---+-----+----+ //|138| 1| 999| //|139| 1000|2999| //|140| 3000|4999| //|141| 5000|9999| //+---+-----+----+
读取 Hbase 中的标签值数据
- 到了这一步,开始逐渐显得与匹配型标签的操作不一样了,在读取完了Hbase中的数据之后,需要展开分析。
- 因为一个用户可能会有多条数据,也就会有多个支付金额,这里需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价。
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource") // hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法 .option("zkHosts",hbaseMeta.zkHosts) .option(HBaseMeta.ZKPORT, hbaseMeta.zkPort) .option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable) .option(HBaseMeta.FAMILY, hbaseMeta.family) .option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields) .load() hbaseDatas.show(5) //+--------+-----------+ //|memberId|orderAmount| //+--------+-----------+ //|13823431| 2479.45| //| 4035167| 2449.00| //| 4035291| 1099.42| //| 4035041| 1999.00| //|13823285| 2488.00| //+--------+-----------+ // 因为一个用户可能会有多条数据 ,也就会有多个支付金额 // 我们需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价 val userFirst: DataFrame = hbaseDatas.groupBy("memberId").agg(sum("orderAmount").cast("Int").as("sumAmount"),count("orderAmount").as("countAmount")) userFirst.show(5) //+---------+---------+-----------+ //| memberId|sumAmount|countAmount| //+---------+---------+-----------+ //| 4033473| 251930| 142| //| 13822725| 179298| 116| //| 13823681| 169746| 108| //|138230919| 240061| 125| //| 13823083| 233524| 132| //+---------+---------+-----------+ // val frame: DataFrame = userFirst.select($"sumAmount" / $"countAmount") val userAvgAmount: DataFrame = userFirst.select('memberId,('sumAmount / 'countAmount).cast("Int").as("AvgAmount")) userAvgAmount.show(5) //+---------+-------------------------+ //| memberId|(sumAmount / countAmount)| //+---------+-------------------------+ //| 4033473| 1774.1549295774648| //| 13822725| 1545.6724137931035| //| 13823681| 1571.7222222222222| //|138230919| 1920.488| //| 13823083| 1769.121212121212| //+---------+-------------------------+
数据关联 JOIN
- 在第四步和第五步中,分别对 MySQL 中的五级标签数据和 Hbase 中的标签值数据进行了处理。
- 在第六步中,应对其进行关联。
- 因为客单价的标签值是一个范围的数据,所以这里使用到了 Between;
- 想要获取到区间范围的起始值只需要用五级标签返回的 DataFrame 对象 fiveTagDF.col 的形式即可获取到。
// 将 Hbase的数据与 五级标签的数据进行 关联 val dataJoin: DataFrame = userAvgAmount.join(fiveTagDF, userAvgAmount.col("AvgAmount") .between(fiveTagDF.col("start"), fiveTagDF.col("end"))) dataJoin.show() // 选出我们最终需要的字段,返回需要和Hbase中旧数据合并的新数据 val AvgTransactionNewTags: DataFrame = dataJoin.select('memberId.as("userId"),'id.as("tagsId")) AvgTransactionNewTags.show(5)
解决数据覆盖的问题
- 在获取到了新数据之后,需要将 Hbase 结果表中的“旧数据”读取出来,然后与之进行合并,所以需要定义一个udf,用于解决标签值重复或者数据合并的问题。
/* 定义一个udf,用于处理旧数据和新数据中的数据合并的问题 */ val getAllTages: UserDefinedFunction = udf((genderOldDatas: String, jobNewTags: String) => { if (genderOldDatas == "") { jobNewTags } else if (jobNewTags == "") { genderOldDatas } else if (genderOldDatas == "" && jobNewTags == "") { "" } else { val alltages: String = genderOldDatas + "," + jobNewTags //可能会出现 83,94,94 // 对重复数据去重 alltages.split(",").distinct // 83 94 // 使用逗号分隔,返回字符串类型 .mkString(",") // 83,84 } }) // 读取hbase中的历史数据 val genderOldDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource") // hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法 .option("zkHosts","192.168.10.20") .option(HBaseMeta.ZKPORT, "2181") .option(HBaseMeta.HBASETABLE, "test") .option(HBaseMeta.FAMILY, "detail") .option(HBaseMeta.SELECTFIELDS, "userId,tagsId") .load() // 新表和旧表进行join val joinTags: DataFrame = genderOldDatas.join(AvgTransactionNewTags, genderOldDatas("userId") === AvgTransactionNewTags("userId")) joinTags.show() val allTags: DataFrame = joinTags.select( // 处理第一个字段 when((genderOldDatas.col("userId").isNotNull), (genderOldDatas.col("userId"))) .when((AvgTransactionNewTags.col("userId").isNotNull), (AvgTransactionNewTags.col("userId"))) .as("userId"), getAllTages(genderOldDatas.col("tagsId"), AvgTransactionNewTags.col("tagsId")).as("tagsId") ) // 新数据与旧数据汇总之后的数据 allTags.show(10)数据写入
- 在合并完了数据之后,最后将其写入到Hbase中即可。
// 将最终结果进行覆盖 allTags.write.format("com.czxy.tools.HBaseDataSource") .option("zkHosts", hbaseMeta.zkHosts) .option(HBaseMeta.ZKPORT, hbaseMeta.zkPort) .option(HBaseMeta.HBASETABLE,"test") .option(HBaseMeta.FAMILY, "detail") .option(HBaseMeta.SELECTFIELDS, "userId,tagsId") .option("repartition",1) .save()
完整代码
import java.util.Properties
import com.czxy.bean.HBaseMeta
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/*
* @Author: Alice菌
* @Date: 2020/6/12 21:10
* @Description:
*
* 基于用户的客单价统计标签分析
*/
object AvgTransactionTag {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("AgeTag").master("local[*]").getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
// 连接MySQL
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
// 引入隐式转换
import spark.implicits._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
// 读取MySQL数据库的四级标签
val fourTagsDS: Dataset[Row] = mysqlConn.select("rule").where("id=137")
val KVMap: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule值
val RuleValue: String = row.getAs("rule").toString
// 使用"##"对数据进行切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
println(KVMap)
// 将Map 转换成HBaseMeta的样例类
val hbaseMeta: HBaseMeta = toHBaseMeta(KVMap)
//4. 读取mysql数据库的五级标签
val fiveTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("pid=137")
val fiveTagDF: DataFrame = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
//133 1-999
//134 1000-2999
var start: String = ""
var end: String = ""
val arr: Array[String] = rule.split("-")
if (arr != null && arr.length == 2) {
start = arr(0)
end = arr(1)
}
// 封装
(id, start, end)
}).toDF("id", "start", "end")
fiveTagDF.show()
//+---+-----+----+
//| id|start| end|
//+---+-----+----+
//|138| 1| 999|
//|139| 1000|2999|
//|140| 3000|4999|
//|141| 5000|9999|
//+---+-----+----+
// 5. 读取hbase中的数据,这里将hbase作为数据源进行读取
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
hbaseDatas.show(5)
//+--------+-----------+
//|memberId|orderAmount|
//+--------+-----------+
//|13823431| 2479.45|
//| 4035167| 2449.00|
//| 4035291| 1099.42|
//| 4035041| 1999.00|
//|13823285| 2488.00|
//+--------+-----------+
// 因为一个用户可能会有多条数据 ,也就会有多个支付金额
// 我们需要将数据按照用户id进行分组,然后获取到金额总数和订单总数,求余就是客单价
val userFirst: DataFrame = hbaseDatas.groupBy("memberId").agg(sum("orderAmount").cast("Int").as("sumAmount"),count("orderAmount").as("countAmount"))
userFirst.show(5)
//+---------+---------+-----------+
//| memberId|sumAmount|countAmount|
//+---------+---------+-----------+
//| 4033473| 251930| 142|
//| 13822725| 179298| 116|
//| 13823681| 169746| 108|
//|138230919| 240061| 125|
//| 13823083| 233524| 132|
//+---------+---------+-----------+
// val frame: DataFrame = userFirst.select($"sumAmount" / $"countAmount")
val userAvgAmount: DataFrame = userFirst.select('memberId,('sumAmount / 'countAmount).cast("Int").as("AvgAmount"))
userAvgAmount.show(5)
//+---------+-------------------------+
//| memberId|(sumAmount / countAmount)|
//+---------+-------------------------+
//| 4033473| 1774.1549295774648|
//| 13822725| 1545.6724137931035|
//| 13823681| 1571.7222222222222|
//|138230919| 1920.488|
//| 13823083| 1769.121212121212|
//+---------+-------------------------+
// 将 Hbase的数据与 五级标签的数据进行 关联
val dataJoin: DataFrame = userAvgAmount.join(fiveTagDF, userAvgAmount.col("AvgAmount")
.between(fiveTagDF.col("start"), fiveTagDF.col("end")))
dataJoin.show()
println("---------------------------------------------")
// 选出我们最终需要的字段,返回需要和Hbase中旧数据合并的新数据
val AvgTransactionNewTags: DataFrame = dataJoin.select('memberId.as("userId"),'id.as("tagsId"))
AvgTransactionNewTags.show(5)
// 7、解决数据覆盖的问题
// 读取test,追加标签后覆盖写入
// 标签去重
/* 定义一个udf,用于处理旧数据和新数据中的数据合并的问题 */
val getAllTages: UserDefinedFunction = udf((genderOldDatas: String, jobNewTags: String) => {
if (genderOldDatas == "") {
jobNewTags
} else if (jobNewTags == "") {
genderOldDatas
} else if (genderOldDatas == "" && jobNewTags == "") {
""
} else {
val alltages: String = genderOldDatas + "," + jobNewTags //可能会出现 83,94,94
// 对重复数据去重
alltages.split(",").distinct // 83 94
// 使用逗号分隔,返回字符串类型
.mkString(",") // 83,84
}
})
// 读取hbase中的历史数据
val genderOldDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts","192.168.10.20")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.load()
// 新表和旧表进行join
val joinTags: DataFrame = genderOldDatas.join(AvgTransactionNewTags, genderOldDatas("userId") === AvgTransactionNewTags("userId"))
joinTags.show()
val allTags: DataFrame = joinTags.select(
// 处理第一个字段
when((genderOldDatas.col("userId").isNotNull), (genderOldDatas.col("userId")))
.when((AvgTransactionNewTags.col("userId").isNotNull), (AvgTransactionNewTags.col("userId")))
.as("userId"),
getAllTages(genderOldDatas.col("tagsId"), AvgTransactionNewTags.col("tagsId")).as("tagsId")
)
// 新数据与旧数据汇总之后的数据
allTags.show(10)
// 将最终结果进行覆盖
allTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.option("repartition",1)
.save()
}
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse(HBaseMeta.ZKHOSTS,""),
KVMap.getOrElse(HBaseMeta.ZKPORT,""),
KVMap.getOrElse(HBaseMeta.HBASETABLE,""),
KVMap.getOrElse(HBaseMeta.FAMILY,""),
KVMap.getOrElse(HBaseMeta.SELECTFIELDS,""),
KVMap.getOrElse(HBaseMeta.ROWKEY,"")
)
}
}