1. 什么是用户画像
- 用户画像,也可称标签模型,是对用户信息的标签化过程;
- 收集用户的多维度数据,对用户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘数据潜在价值,从而抽象出用户的信息全貌。
- 标签化过程:
- 信息 > 文本 > 数据 > 标签
2. 用户标签包括那些内容
2.1. 按照维度划分
- 自然属性
- 社会属性
- 行为习惯
- 购买能力
- 消费习惯
- 偏好特征 / 兴趣爱好
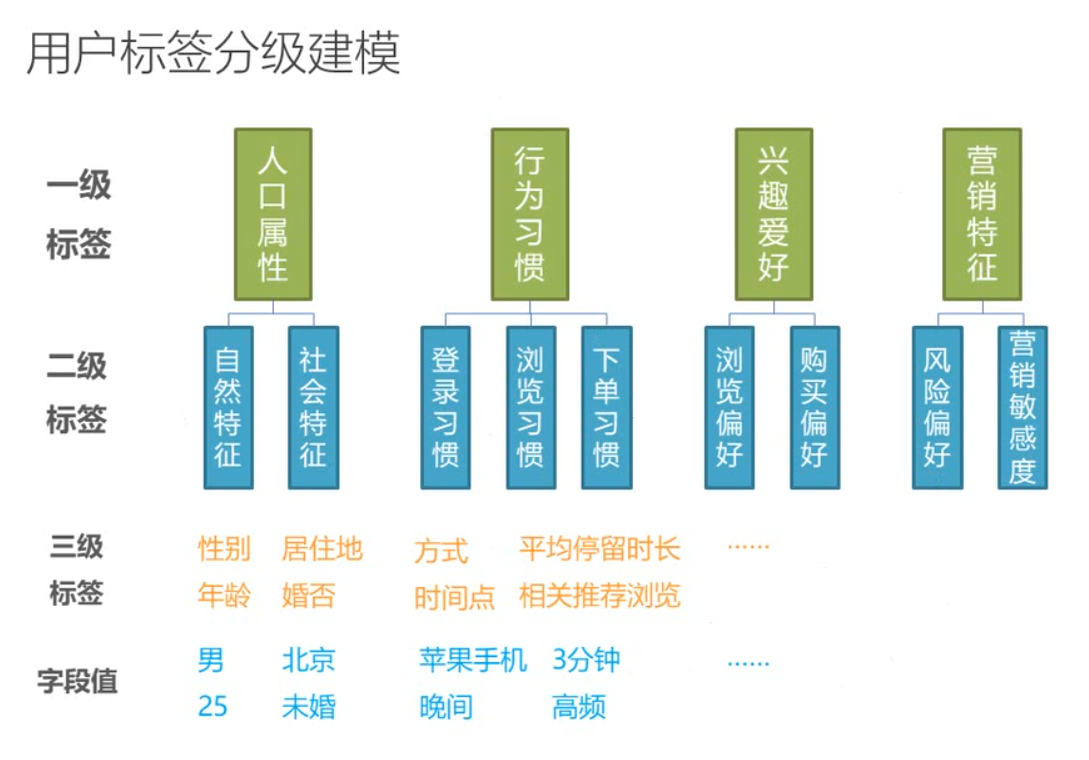
2.2. 按照层级划分
2.3. 按照生成方式划分
- 统计类指标
- 又叫:事实标签
- 可以直接提取
- 包括一些基本信息,比如:年龄、性别、城市、职业等
- 也可以从用户数据、行为数据、消费数据中统计得出
- 这些标签来自基于行为数据的统计信息,比如:1日登录次数、7日登录次数、7日下单次数等
- 这类标签,构成了用户画像的基础
- 规则类标签
- 又叫:建模标签
- 在统计指标基础上通过规则生成,是对统计类指标的有效补充
- 需要基于用户行为自定义规则
- 比如:
- 活跃用户,定义规则为每天登录一次以上的用户
- 高净值用户,消费总额在某个阈值以上
- 比如:
- 在开发过程中,运营人员对业务更熟悉,数据维护人员对数据结构、分布、特征更熟悉,所以多数时候由运营人员和数据人员共同搭建维护;
- 预测类标签
- 又叫:机器学习标签
- 是非确定性标签(前两项都属于确定性标签)
- 需要基于已有的信息“预测”用户特征,需要挖掘才能获得
- 实际开发过程中,这类项目开发周期长、成本高,属于探索性项目
- 有些公司使用外包人员、手动打标签,效果可能会更好、而且投入也很低
3. 用户画像的价值是什么
3.1. 业务决策
- 定位用户人群
- 聚焦目标用户
- 统计指标展示
- 排名统计
- 地域分析
- 特征分析
- 行业趋势
- 竞品分析
- 等等
3.2. 精准营销 / 圈人服务
- 定向推送
- 邮件、短信、APP
- 定点推送
- 站外广告
- 站内广告
3.3. 个性化服务
- 个性化推荐
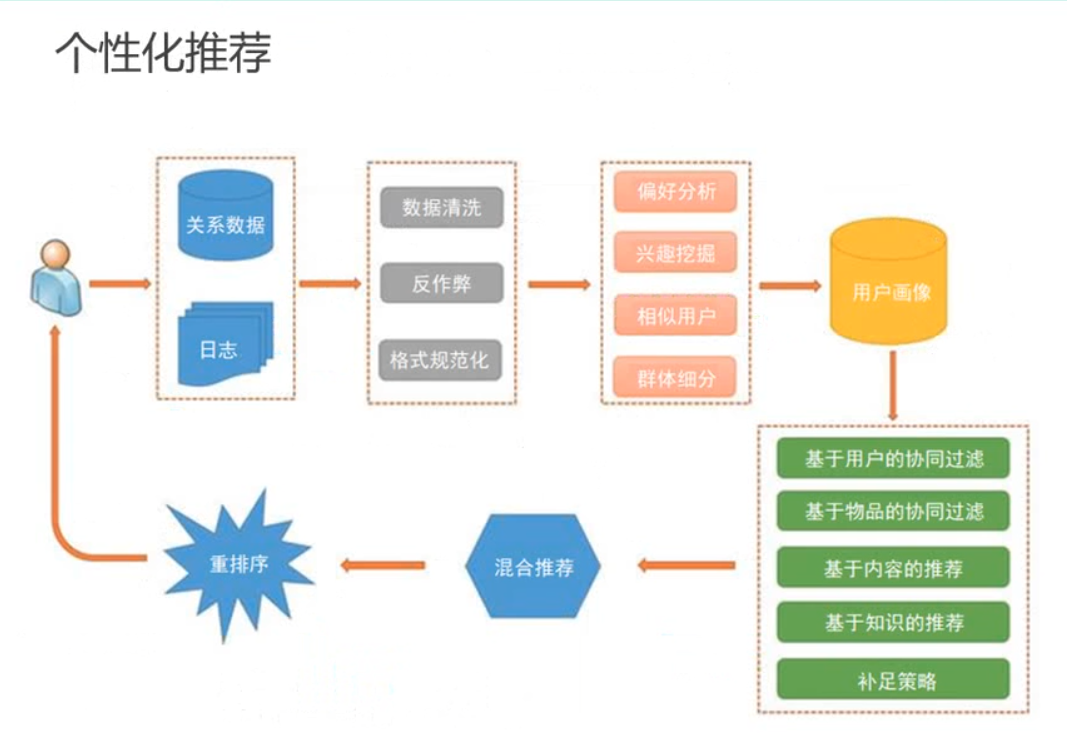
- 个性化搜索
3.4. 用户研究
- 挖掘用户特征
- 多维度用户分析
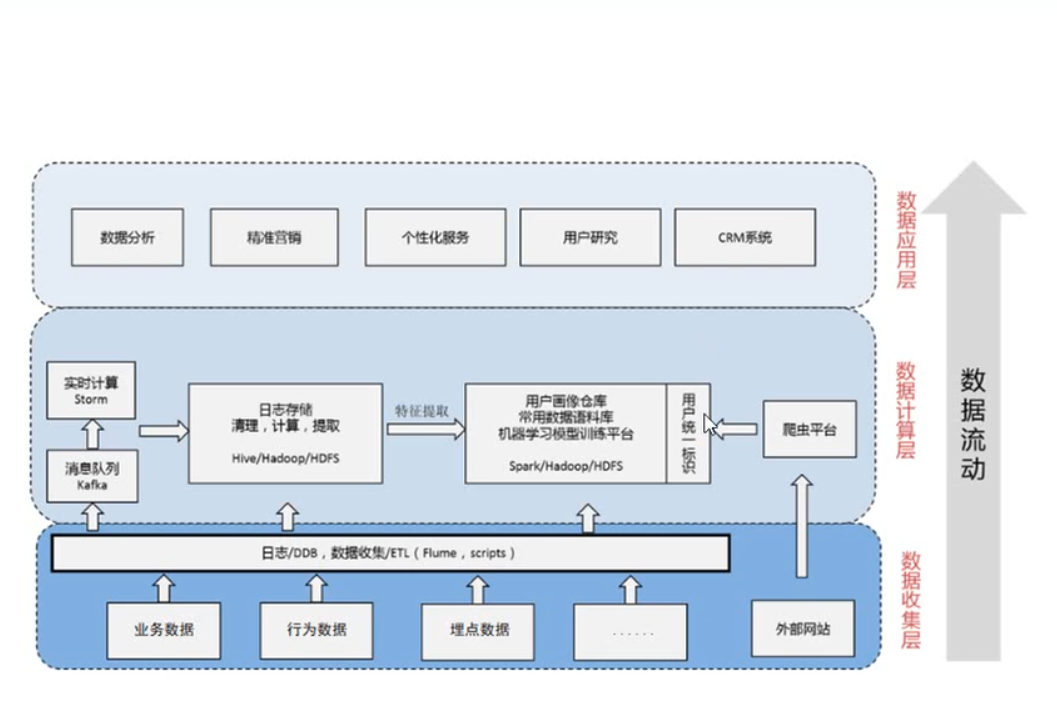
4. 用户画像系统的数据流向
5. 用户画像项目团队及协作
- 运营经理 / 业务产品经理
- 数据产品经理
- 数仓工程师
- 数仓模型搭建
- 算法工程师
- 算法模型建设
- 后端工程师
- 系统功能模块建设
- 测试人员
- 数据测试
- 功能测试
6. 用户画像项目技术栈
6.1. 数据开发
- Spark
- Flink
6.2. 数据存储 & 查询
- Hbase
- Hive
- MySQL
6.3. 流式计算
- Kafka
- Spark Streaming
6.4. 作业调度
- Crontab
- Airflow
6.5. 开发语言
- Scala
- 标签的复杂计算
- Spark Streaming
- Hive SQL
- Python
- 监控脚本
- 调度流
- Shell
7. 用户画像项目开发流程
7.1. 需求调研
- 业务需求分析
- 数据盘点
- 竞品调研
- 输出:《产品用户画像需求文档》,明确应用场景、标签内容、应用方式等;
7.2. 产品设计
- 业务架构
- 产品架构
- 标签体系设计
- 画像系统功能
- 产品版本计划
- 输出:《产品用户画像产品规划文档》,明确应用方式、标签模型、功能模块、UI/Demo等;
7.3. 技术规划
- 目标解读
- 任务分解
- 技术方案选型
- 标签数据落表
- 逻辑模型
- 数据字典
- 血缘关系
- 标签权重
- 数据采集体系规划
- One ID(主要在多平台场景)设计
- 项目计划 & 开发流程
- 输出:《产品用户画像技术规划文档》,明确技术选型、方案设计、开发计划、数据库表等;
7.4. 技术开发
- 用户建模
- 确定要提取的用户特征维度
- 数据采集
- 读取需要的数据,统计存放到数据仓库
- 数据清洗
- 通常直接在 hive 中进行,包括统计类标签的生成
- 模型训练
- 对于无法直接得到的标签,建立模型进行训练
- 属性预测
- 利用训练得到的模型,和用户的已知特征,预测未知特征,同时不断优化模型
- 标签落表
- 特征选取 & 标签数据落表
- 数据合并
- 把多数据源提取的特征进行合并
- 数据分发 / 接口封装
- 对于合并后的结果数据,分发到各个平台,为业务提供支撑
7.5. 灰度测试
- 线下模型数据测试
- 线上灰度测试
7.3. 运营反馈
- 线上模型发布
- A/B 测试
- 效果追踪
- 模型修正
7.6. 项目评审四个关键点
- 立项评审
- 需求评审
- 提测演示
- 产品发布验收