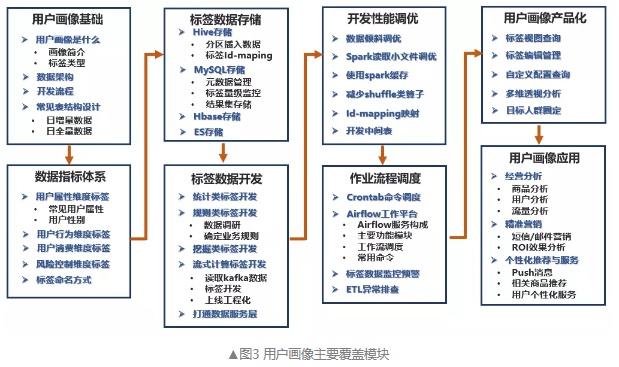
1. 用户画像系统开发流程图
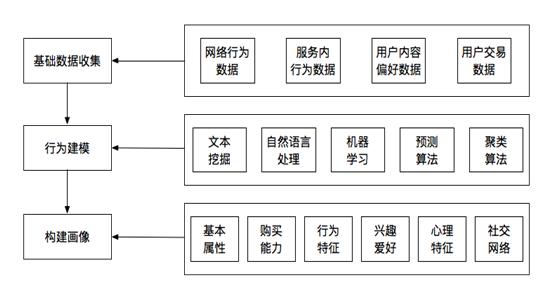
2. 系统框架设计
- 用户画像系统包括三层结构,分别是:
- 基础数据收集
- 行为建模
- 构建画像
- 其中:
- 基础数据收集的对象包含了业务数据和用户行为数据;
- 行为建模,指的是在基础数据上对用户数据进行多维度的挖掘分析;
- 构建画像,则是要给用户打上标签,并进行落表存储或提服务;
- 在系统设计阶段
- 需要明确用户画像系统包含哪些模块,数据仓库架构是什么样子,开发流程是什么样,表结构如何设计,ETL如何设计等。
- 只有明确了上面的方向,后续才能做好项目的排期和人员投入预算,这对于评估每个开发阶段重要指标和关键产出非常重要。
3. 数据指标体系
-
根据业务线梳理,包括用户属性、用户行为、用户消费、风险控制等维度的指标体系。
-
关于本节,详细内容参见:《 用户画像:常见的用户标签体系 》。
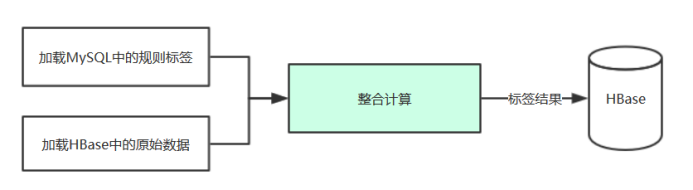
4. 标签数据存储
- 标签相关数据可存储在 Hive、MySQL、HBase、Elasticsearch 等数据库中,不同存储方式适用于不同的应用场景。
4.1. Hive
- 在 hive 中做主题建模
- 存储用户画像标签
4.2. Hbase / Redis
- 个性化推荐
- 线上实时数据
4.3. MySQL
- 用户画像标签-元数据管理
- BI 报表展示
4.4. Elasticsearch
- 圈人服务 & 用户列表
- ES 中快速获取标签对应的用户列表,进而定向推送营销信息
- ES 方便复杂查询
5. 标签数据开发
- 标签开发
- 标签开发,是用户画像工程化的重点模块,包含统计类、规则类、挖掘类、流式计算类标签的开发,以及人群计算功能的开发,打通画像数据和各业务系统之间的通路,提供接口服务等开发内容。
- 离线标签
- 画像系统的标签,分为离线标签和实时标签。
- 离线标签又分为基于统计类型的标签和基于算法性标签,大部分或者 90% 的标签都是统计类型标签;
- 机器学习的算法标签很少:
- 一方面是因为开发周期很长,
- 另一方面效果也有限。
- 但是基于某些场景,还是得需要使用机器学习,只是机器学习标签的比重会很小。
- 有时我们做实时数据支持,会通过实时数据流给用户做刻画或者做特征标记,可做线上服务接口调用查询。
- 用户维表
- 用户维表是一张大宽表,大宽表基于筛选用户的属性或分析师分析用户的时候用。除了标签跑批、用户维表,还有人群计算、行为数据等的数据开发。
5.1. 标签开发
-
每个标签,一个应用程序,需要一个标签,就开发一 Spark 套程序,如果不再使用标签,则直接停止该程序;
- 标签表示例:
CREATE TABLE `tbl_basic_tag` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '标签ID', `name` varchar(50) DEFAULT NULL COMMENT '标签名称', `industry` varchar(30) DEFAULT NULL COMMENT '行业、子行业、业务类型、标签、属性', `rule` varchar(300) DEFAULT NULL COMMENT '标签规则', `business` varchar(100) DEFAULT NULL COMMENT '业务描述', `level` int(11) DEFAULT NULL COMMENT '标签等级', `pid` bigint(20) DEFAULT NULL COMMENT '父标签ID', `ctime` datetime DEFAULT NULL COMMENT '创建时间', `utime` datetime DEFAULT NULL COMMENT '修改时间', `state` int(11) DEFAULT NULL COMMENT '状态:1申请中、2开发中、3开发完成、4已上线、5已下线、6已禁用', `remark` varchar(100) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=233 DEFAULT CHARSET=utf8 COMMENT='基础标签表'; - 模型表示例:
- 详细记录标签模型 application 的位置;
CREATE TABLE `tbl_model` ( `id` bigint(20) DEFAULT NULL, `tag_id` bigint(20) DEFAULT NULL COMMENT '标签ID', `type` int(11) DEFAULT NULL COMMENT '算法类型:统计-Statistics、规则匹配-Match、挖掘-具体算法-DecisionTree', `model_name` varchar(200) DEFAULT NULL COMMENT '模型名称', `model_main` varchar(200) DEFAULT NULL COMMENT '模型运行主类名称', `model_path` varchar(200) DEFAULT NULL COMMENT '模型JAR包HDFS路径', `sche_time` varchar(200) DEFAULT NULL COMMENT '模型调度时间', `ctime` datetime DEFAULT NULL COMMENT '创建模型时间戳', `utime` datetime DEFAULT NULL COMMENT '更新模型时间戳', `state` int(11) DEFAULT NULL COMMENT '模型状态,1:运行;0:停止', `remark` varchar(100) DEFAULT NULL, `operator` varchar(100) DEFAULT NULL, `operation` varchar(100) DEFAULT NULL, `args` varchar(100) DEFAULT NULL COMMENT '模型运行应用配置参数,如资源配置参数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 详细记录标签模型 application 的位置;
-
标签表上的每条记录,与模型表中的记录,是一一对应的。
-
标签开发流程图:
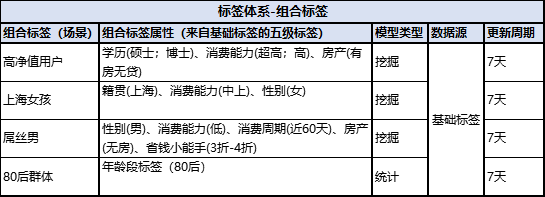
-
组合标签开发
5.2. 相似性拓展
- 通过匹配标签的方式获取
- 识别种子人群的特征标签,基于识别的典型特征,进行人群的扩展。
- 例如:
- 种子人群有【高消费】、【偏好奢侈品】、【小镇中产】等标签;
- 那么可以将包含这些特征的人群都先圈出来(交集或者并集),这样就完成了相似人群的扩展。
- 通过标签的方式,比较容易理解。
- 通过相似度的方式直接计算
- 将人群的特征进行向量化,然后计算向量之间的距离。
- 例如:
- 某人群总共有 100 个标签、400 个特征(所谓特征可以理解成标签取值),那么每个用户都可以用 400 维的向量进行标识。
- 基于每个用户的向量,计算种子人群的向量均值,然后用其余待匹配人群的特征向量,与种子人群的向量均值求距离。
- 最后,按照距离进行排序,获得距离最近的top取值即可。
- 用距离的方法,比较容易计算。
- 通过机器学习的方式训练
- 算法的具体实现,其实就是一个典型的分类问题,即判断一个人属不属于种子人群,而种子人群作为机器学习训练集。
6. 系统性能调优
- 标签加工、人群计算等脚本上线调度后,为了缩短调度时间、保障数据的稳定性等,需要对开发的脚本进行迭代重构、调优。
6.1. 数据倾斜调优
- 解决数据倾斜的几个思路:
- 业务上:避免热点key的设计或者打散热点key,例如可以把北京和上海分成地区,然后单独汇总。
- 技术上:在热点出现时,需要调整方案避免直接进行聚合,可以借助框架本身的能力,例如进行mapside-join。
- 参数上:无论是Hadoop、Spark还是Flink都提供了大量的参数可以调整。
- 调优方法:
- 当少量key重复次数特别多,如果这种key不是业务需要的key,可以直接过滤掉。
- 事前对连接 key 进行预处理
- map join
- 特殊值分开处理
- 随机数分配法
- 解决小表过大无法 map join 问题
- 处理连接 key 为 NULL 空值
- 处理连接 key 为不同数据类型
- 提高 Reduce 任务的并行度
6.2. 合并小文件
- Spark 执行
insert overwrite table语句时,由于多线程并行向 HDFS 写入且 RDD 默认分区为 200 个,因此默认情况下会产生200个小文件。 - Spark 中可以使用 reparation 或 coalesce 对 RDD 的分区重新进行划分,reparation 是 coalesce 接口中 shuffle 为true的实现。
- 在 Spark 内部会对每一个分区分配一个 task 执行,如果 task 过多,那么每个 task 处理的数据量很小,这就会造成线程频繁在 task 之间切换,导致集群工作效率低下。
- 为解决这个问题,常采用 RDD 重分区函数来减少分区数量,将小分区合并为大分区,从而提高集群工作效率。
6.3. 缓存中间数据
- Spark 的一个重要的能力就是将数据持久化缓存,这样在多个操作期间都可以访问这些持久化的数据。
- 当持久化一个 RDD 时,每个节点的其他分区都可以使用 RDD 在内存中进行计算,在该数据上的其他 action 操作将直接使用内存中的数据,这样会使其操作计算速度加快。对 RDD 的复杂操作如果没有持久化,那么一切的操作都会从源头开始,一步步往后计算,不会复用原始数据。
- 在画像标签每天 ETL 的时候,对于一些中间计算结果可以不落磁盘,只需把数据缓存在内存中。而使用 Hive 进行 ETL 时需要将一些中间计算结果落在临时表中,使用完临时表后再将其删除。
- RDD 可以使用 persist 或 cache 方法进行持久化,使用 StorageLevel 对象给 persist 方法设置存储级别时,常用的存储级别如下所示:
- MEMORY_ONLY:只存储在内存中
- MEMORY_ONLY_2:只存储在内存中,每个分区在集群中两个节点上建立副本;
- DISK_ONLY:只存储在磁盘中;
- MEMORY_AND_DISK:先存储在内存中,内存不够的话存储在磁盘中
- 其中 cache 方法等同于调用 persist()的 MEMORY_ONLY方法
- 在画像标签开发中,一般从 Hive 中读取数据,然后将需要做中间处理的 DataFrame 注册成缓存表。
- 也可以将读取的用户数据缓存在内存中并注册为一张视图,后续直接从视图中读取对应用户数据。在该 Spark 任务执行完成后,释放内存,不需要清除该缓存数据。
6.4. 开发中间表
- 在用户画像迭代开发的过程中,初期开发完标签后,通过对标签加工作业的血缘图整理,可以找到使用相同数据源的标签,对这部分标签,可以通过加工中间表缩减每日画像调度作业时间。
- 做中间层设计前需要明确几个重要的点:
- 这个中间层对应的业务场景、业务目标是什么?
- 业务方有了这份中间层数据以后可以进行哪些维度的分析,ETL时有了这份中间层数据可以减少对哪些数据的重复开发计算?
- 这个业务场景分析中包含哪些分析维度和指标?
- 同时面向很多业务场景的中间层不一定是好的中间层。
- ETL 调度时间过长是一个较难解决的“瓶颈”,每天的调度在跑完计算标签、标签校验预警、计算人群、人群校验预警、同步到服务层等环节后往往需要几个小时,最后提供到服务层数据时也比较晚了。
7. 作业流程调度
- 标签加工、人群计算、同步数据到业务系统、数据监控预警等脚本开发完成后,需要调度工具把整套流程调度起来。
- ETL 调度模型,包括标签的加工计算、数据标签的校验、人群计算、跑一些分析宽表。
- 跑完数据模型后,
- 推荐到线上服务层,比如:Redis、Clickhouse、ES;
- 服务调用,包括站内的服务调用以及TOC的客户端服务调用。
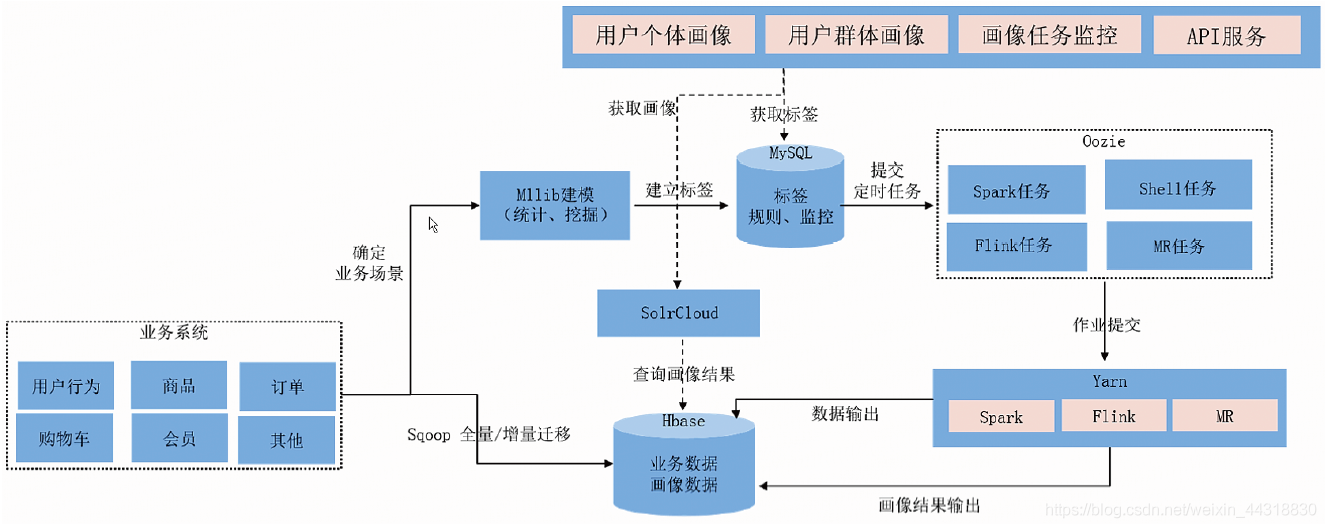
8. 用户画像产品化
- 为了能让用户数据更好地服务于业务方,需要以产品化的形态应用在业务上。产品化的模块主要包括标签视图、用户标签查询、用户分群、透视分析等。
8.1. 单用户画像
- 基于用户 ID 查询用户标签
- 用户信息
- 词云
- 营销提醒
- 用户转化率分析
- 用户漏斗分析
- 用户路径分析
- 用户兴趣偏好
8.2. 群体用户画像
- 群体用户信息
- 群体用户词云
- 群体用户营销提醒
- 群体用户转化率分析
- 群体用户漏斗分析
- 群体用户路径分析
- 群体用户兴趣偏好
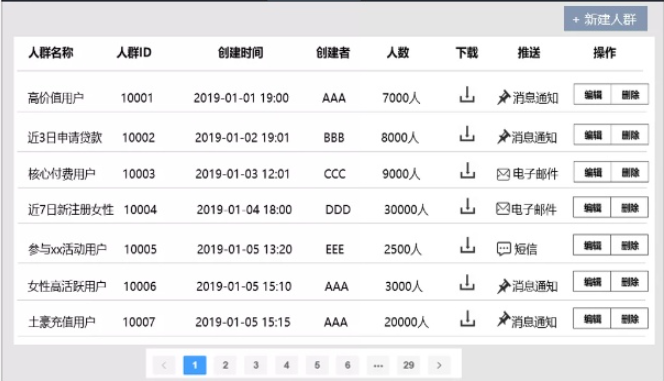
8.3. 人群圈选
- 创建、编辑、删除人群
-
基于不同规则筛选目标人群;
8.4. 多标签圈选
- 组合查询多个标签,获取人群;
- 例如:组合“近30日购买次数”大于3次和“高活跃”“女性”用户这三个标签进行定义目标人群,查看该类人群覆盖的用户量,以及该部分人群的各维度特征。
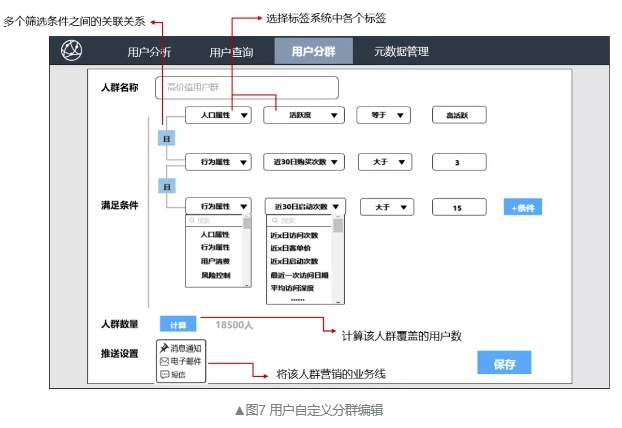
- 在自定义编辑用户分群时,对于有统计值类型的标签,可以自定义筛选该标签的取值范围,如上图中“近30日购买次数”标签,业务人员可筛选该标签的数值。
- 例如:组合“近30日购买次数”大于3次和“高活跃”“女性”用户这三个标签进行定义目标人群,查看该类人群覆盖的用户量,以及该部分人群的各维度特征。
8.5. 人群洞察
- 作用:
- 在选定人群后,对人群进行各个维度的透视分析;
- 例如:
- 选定年龄为“30-35岁”、居住在“一线城市”且有“汽车”资产的“男性”;
- 对该人群进行透视分析后发现,这部分用户的“价格敏感度”较低、对于“自驾游”的兴趣比较高;
8.6. 相似性拓展
- 作用:
- 基于种子人群进行相似人群的匹配。
- 种子人群圈选
- 用户自己通过标签系统圈选人群;
- 扩展倍数设置
- 即要将种子人群扩大的倍数;
- 通常作为配置项让用户进行选择。
- 扩展人群洞察
- 将种子人群按照扩展倍数扩充后,获得扩展的相似人群;
- 该人群的特征规律应该和种子人群的特征规律比较一致或者相近。
- 扩展人群管理
- 扩展人群上架;
- 扩展人群下架;
- 扩展人群修改;
9. 用户画像应用
-
画像的应用场景包括用户特征分析、短信、邮件、站内信、Push消息的精准推送、客服针对用户的不同话术、针对高价值用户的极速退货退款等VIP服务应用。
-
关于本节,详细内容参见:《 用户画像:常见的用户标签体系 》