1. 什么是拉链表
1.1. 拉链表定义
- 所谓拉链,顾名思义,就是记录历史,记录一个事物从开始,一直到当前状态的所有变化的信息。
- 拉链表,是针对数据仓库设计中表存储数据的方式而定义的。拉链表的核心思想,像个拉链,支持开链,支持闭链,支持退链。我们通常将最新的数据称为开链数据,历史数据称为闭链数据。
- 拉链表在一个时间维度中,同一个用户只保存一条用户状态。
- 拉链表通常会增加三个技术字段:开始日期
start_time、结束日期endtime、状态标识mark。 - 通过主键(PK)与历史数据进行对比,判断当前数据与历史数据是否发生变化,如果发生变化或者新增则进行相应的开链、闭链操作。
- 拉链表支持历史数据查询,且空间占用较小,但是数据加工处理较为繁琐,属于时间换空间的设计方式。
1.2. 拉链表示例
-
下面是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期,通过这张表可以获取到最新的当天数据以及之前的历史数据。
-
拉链表示例:
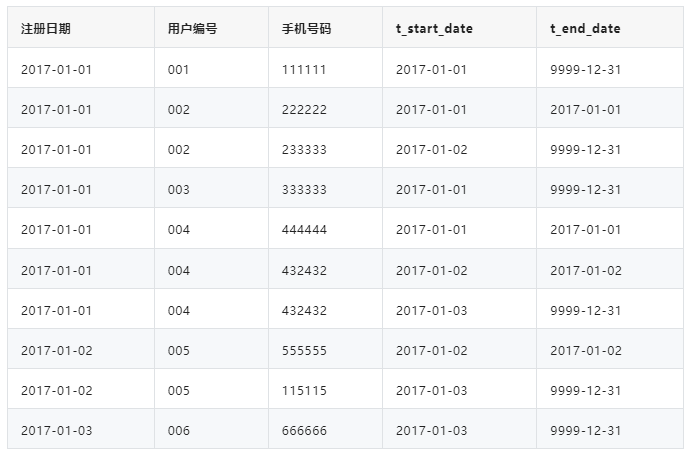
t_start_date,表示该条记录的生命周期开始时间;t_end_date,表示该条记录的生命周期结束时间;t_end_date='9999-12-31',表示该条记录目前处于有效状态;- 如果查询当前所有有效的记录,则使用
select * from user where t_end_date = '9999-12-31'即可以获取; - 如果查询
2017-01-01当天的历史快照,则select * from user where t_start_date <= '2017-01-01' and end_date >= '2017-01-01'。
2. 缓慢变化维
2.1. 缓慢变化维(SCD,Slowly Changing Dimensions)
- 缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流逝发生缓慢的变化。
- 这种随时间发生变化的维度我们一般称之为缓慢变化维,并且把处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,有时也简称为处理SCD的问题。
2.2. 缓慢变化维处理的方式
- 重写覆盖
- 与业务系统保持一致,直接更新为最新的状态数据即可;适用于:数据必须正确,比如客户的身份证;不需要考虑历史变化维度,没有意义没有价值的维度;优点是直接更新即可,缺点无法恢复,不能查看历史变化;
- 增加新行
- 更新历史数据时间戳,新增新行记录新值;适用于仅需保持历史数据的业务场景,相应的事实表的的关联需要更新为最新的 id;
- 增加新列
- 如果某个维度发生多次变化,会产生列爆炸
- 拉链表
- 拉链表的具体使用
3. 为什么需要拉链表
3.1. 海量数据更新问题
- 在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
- 数据量比较大;
- 表中的部分字段会被 update,如:
- 用户联系方式;
- 客户收件地址;
- 产品的描述信息;
- 订单的状态;
- 等等。
- 需要查看某一个时间点或者时间段的历史快照信息,比如:
- 查看某一个订单在历史某一个时间点的状态;
- 查看某一个用户在过去某一段时间内更新过几次;
- 等等。
- 变化的比例和频率不是很大,比如:
- 总共有
1000万的会员信息记录,每天新增和发生变化的记录有10万左右;
- 总共有
- 对于上面的需求,如果对表每天都保留一份全量数据,那么每次全量中会保存很多不变的信息,这对存储是极大的浪费;
- 针对上面的需求,该如何设计表,有三种方案可以选择:
- 方案一:每天只留一份最新的数据。
- 方案二:保留一份全量的切片数据。
- 方案三:使用拉链表。
3.2. 方案一:每天只留一份最新的数据
- 这种方案实现起来很简单,每天
drop掉前一天的数据,重新抽取一份最新的数据。 - 优点:
- 很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
- 缺点:
- 也很明显,没有历史数据,想翻翻旧账只能通过其他方式,比如从流水表里面抽。
3.3. 方案二:每天保留一份全量的切片数据
- 每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
- 缺点:
- 存储空间占用的量太大了,如果对这个表每天都保留一份全量,那么每次全量的数据中会有很多不变的数据,对存储是极大的浪费。
- 当然我们也可以做一些取舍,比如只保留最近一个月的数据。但是,数据的生命周期就会被严重制约,历史数据大量丢失不符合大数据的建设理念。
3.4. 方案三:每天同步一次更新数据
- 每天只更新有变化的数据;
- 缺点:
- 无法反应数据的变化情况;
- 无法得到某一个历史时间点(时间切片,如某一天)的切片数据;
3.5. 方案四:使用拉链表
- 拉链表可以看做是对前两种方案的一种折中处理。
- 首先,拉链表在空间上做了一个取舍,虽然不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一,所以空间占用问题也在可接受范围内。
- 其次,它也能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件、以获取历史的数据。
4. 拉链表的实现
4.1. 基于 MySQL 实现拉链表
- 数据源
- ODS 层用户全量表,需要用它来做初始化。
- 每日的用户更新表,即每日增量表。
- 时间粒度
- 确定拉链表的时间粒度,比如说每天拉链表只取一个状态,那即使一天有多次变化,也只取最后一次状态;
- 这种具体到天粒度的表,其实已经能解决大部分问题了。
- 获取更新变化
- 每日的用户更新表,有三种方式拿到每日的用户增量:
- 方法一:监听 MYSQL 数据的变化,比如说用 Canal,最后合并每日的变化,获取到最后一个状态;
- 假设我们每天都会获得一份切片数据,我们可以通过两天切片数据的不同来作为每日更新表的依据;
- 这种情况下我们对所有的字段先进性 concat、再去MD5,就能实现更新了。
- 方法二:流水表,有每日变更的流水表
- 方法三:同步 ODS 用户全量表,对
modify_time为当日时间的数据进行增量同步。
- 方法一:监听 MYSQL 数据的变化,比如说用 Canal,最后合并每日的变化,获取到最后一个状态;
- 每日的用户更新表,有三种方式拿到每日的用户增量:
- 查询性能
- 随着数据量的增长,链表也会遇到查询性能的问题,比如:
- 存放了 5年 的用户信息数据,表记录数量势必会比较大,查询的时候性能就比较低;
- 随着数据量的增长,链表也会遇到查询性能的问题,比如:
- 解决思路
- 在一些查询引擎中,对 start_date 和 end_date 做索引;
- 设计两张拉链表:
- 一张表存放全量的拉链表数据;
- 另一张表对外暴露,只提供近3个月数据的拉链表。
4.2. 基于 Hive 实现拉链表
注意:
在现在的大数据场景下,大部分公司都会选择以 HDFS 和 HIVE 为主的数据仓库架构。目前的 HDFS 版本来讲,其文件系统中的文件是不可做改变的,也就是说 HIVE 的表只能进行删除和添加操作,而不能
update操作,基于这个因素我们需要采用 中间表 的方式实现。
- 中间表设计
- TODO
- 参考:https://mp.weixin.qq.com/s/VGZbHLjd1-7Qx6WG4_N4ew