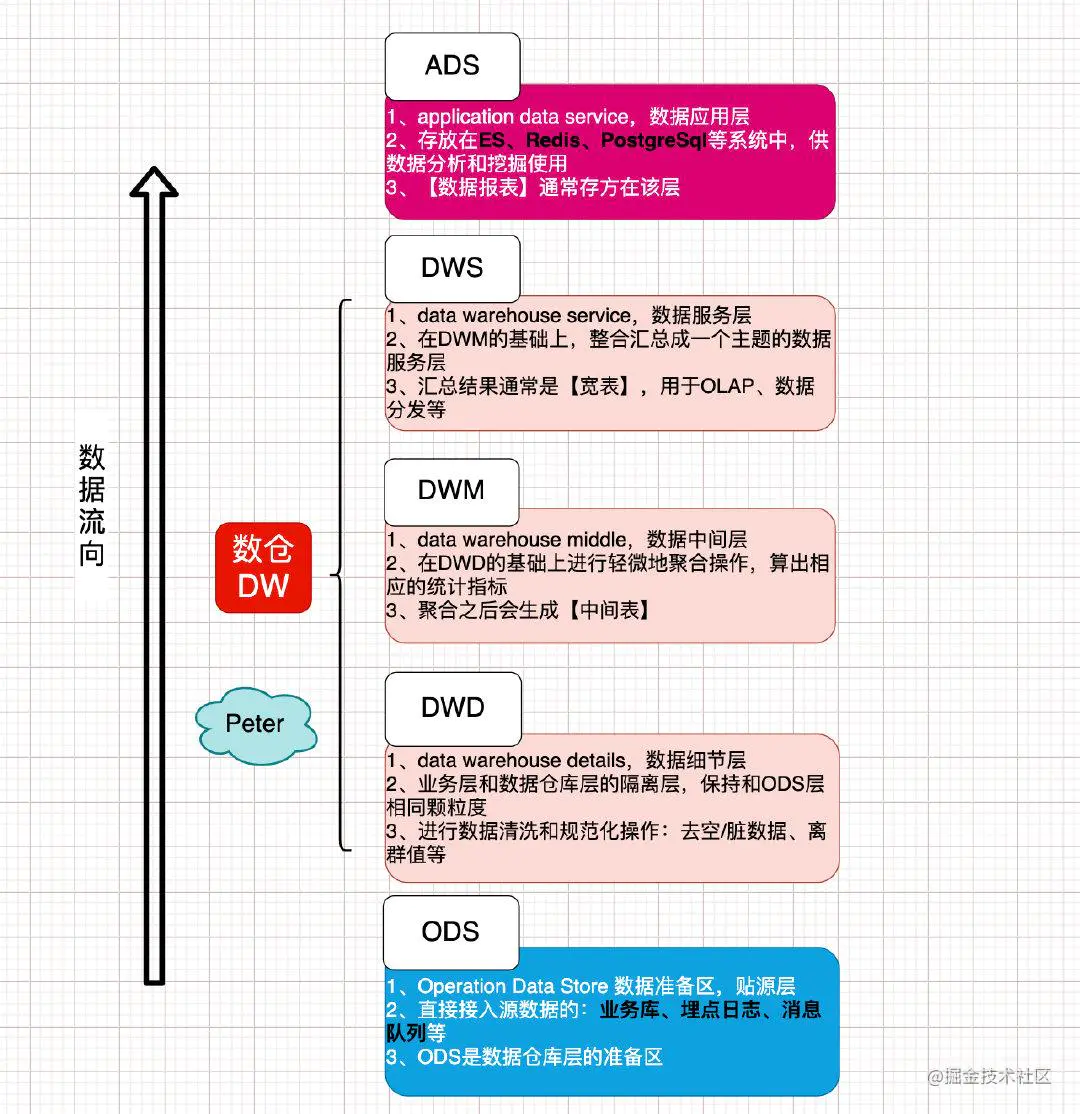
1. 数据流向
2. 数仓分层的价值
数据分层的好处:
- 清晰数据结构:
- 让每个数据层都有自己的作用和职责,在使用和维护的时候能够更方便和理解;
- 复杂问题简化:
- 将一个复杂的任务拆解成多个步骤来分步骤完成,每个层只解决特定的问题;
- 统一数据口径:
- 通过数据分层,提供统一的数据出口,统一输出口径;
- 复用中间数据结果,减少重复开发:
- 规范数据分层,开发通用的中间层,可以极大地减少重复计算的工作,更加灵活应对企业开发需求;
- 降低存储压力
- 降低企业使用成本
- 提升数据处理速度
- 不需要所有需求都从数据量最大的ODS层进行数据处理
3. ODS 源数据层
3.1. ODS 定义
ODS(Operation Data Store),也称为贴源层。数据源中的数据,经过抽取、洗净、传输,也就是ETL过程之后进入本层。
3.2. ODS 功能
ODS 层的数据,是后续数据仓库加工数据的来源:
- ODS是后面数据仓库层的准备区
- 为DWD层提供原始数据
- 减少对业务系统的影响
为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可。
3.3. ODS 数据来源
- 业务库:
- sqoop定时抽取数据;实时方面考虑使用canal监听mysql的binlog日志,实时接入即可
- 埋点日志:
- 日志一般是以文件的形式保存,可以选择使用flume来定时同步;可以使用spark streaming或者Flink、Kafka来实时接入
- 消息队列:
- 来自ActiveMQ、Kafka的数据等
3.4. ODS 层数据存在的问题
- 字段缺失
- 数据字段不统一
- 格式错误
- 关键信息丢失等等
- 数据来源混杂
- 数据类型不一
- 例如json,xml,text,csv的,
- 压缩了的,没有压缩的
3.5. ODS 层的数据存储
- 如果数据来自于日志文件,一般和原始日志文件格式一样;
- 如果数据来自于数据库,则看需要决定存储方式;
如果使用 hive 做 ODS 数据存储管理,遇到 JSON 时可以使用 JsonSerde 进行数据解析。
3.6. ODS 层数据分区
- 一般都是按照天进行分区,如使用hive、则partitioned by 一般都是按照天进行存放。
3.7. ODS 层存储容量设计
日志数据估算,如日活100万用户,每个用户访问1次,每次操作5min,每个用户平均3秒一条日志数据,一条数据1kb.最后体积是100w1560/31kb=100w*100kb=97656.25MB=95.36GB;
注意,数据估算最好结合公司实际情况,如果已经运行一段,可以让运维同事帮忙做估算
4. DWD 数据细节层
4.1. DWD 定义
DWD(data warehouse details),该层是业务层和数据仓库的隔离层,保持和ODS层一样的数据颗粒度。
4.2. DWD 功能
主要是对ODS数据层做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。
为了提高数据明细层的易用性,该层通常会才采用一些维度退化方法,将维度退化至事实表中,减少事实表和维表的关联。
4.3. ETL 数据清洗
ETL 数据清洗的数据,一般放到 DWD 层。具体的可以参考另一篇文章:《ETL方法论:数据清洗》。
4.4. 维度表
DWD 层,一般只存储维度表、事实表、实体表。
- 维度表,顾名思义就是一些维度信息,这种表数据,一般就直接存储维度信息,很多时候维度表都不会很大。
- 维度表,一定是被共享的、通用性的,在数仓系统内一项维度只会有一张维度表;
- 维度表,轻易不会做变更修改,可以增加、尤其是不要轻易做修改和删除操作;
-
维度表,会与事实表的维度列做外键关联,使事实表可以生成更多的维度信息;
- 维度表设计
- 一般会把维度信息单独存放,其他表要使用时,记录对应维度的id即可。这样,就算维度表中数据发生了变化,其他表数据因为只是记录了id,不会有影响。
- 维度信息放在一张表中存放,而不是每个表中存储一份,将来需要调整,只需要做一次工作即可,降低了数据冗余。
4.5. 事实表
- 事实表,就是表述一些事实信息,如订单、收藏,添加购物车等信息,这种数据量较大;
- 事实表由维度和度量组成,事实表中存储的是维度信息(维度列)、以及可度量的值(属性列);
- 比如:区域销售表中,地区是维度,而销售额是度量;
- 事实表中一般会使用一个代号、或者整数(如:ID)来代表维度成员,而不是描述性的名称;
- 比如:区域销售统计中,地区一般记录地区ID,而不是地区名称;
- 因为数据可能会变化,这种一般存储维度主键,具体维度值在后续处理分析时再临时关联;
- 事实表中的维度,一定会对应一张维度表;
4.6. 实体表
- 实体表,类似 javabean、用来描述信息的,如优惠券表、促销表,内部就是一些描述信息;
- 处理的频率,一般看数据量以及变化程度,大部分时候都是全量导入,导入周期则看具体而定。
4.7. 拉链表
5. DWM 数据中间层
5.1. DWM 定义
DWM(Data Warehouse Middle),该层是在DWD层的数据基础上,对数据做一些轻微的聚合操作。
5.2. DWM 功能
- DWM 通过聚合,生成一些列的中间结果表:
- 提升公共指标的复用性,减少重复加工的工作。
- 主要是对通用的核心维度进行聚合操作,算出相应的统计指标。
6. DWS 数据服务层
6.1. DWS 定义
DWS(Data Warehouse Service),是基于DWM上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表。
- 宽表,是维度表和统计后的事实表的整合;
- 宽表中,会包括详细的维度信息和度量值,需要 DWD 的表进行维度退化操作;
6.2. DWS 功能
DWS 用于提供后续的业务查询,OLAP分析,数据分发等。
一般来说,该层的数据表会相对较少;一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
7. ADS 数据应用层
7.1. ADS 定义
ADS(Application Data Service),数据应用层,通常是存放计算得出的数据结果值,统计报表直接从这一层获取数据,然后在 BI 进行展示。
7.2. ADS 功能
- DWS 主要是提供给数据产品和数据分析使用的数据:
- 一般会存放在ES、Redis、PostgreSql等系统中供线上系统使用;
- 也可能存放在hive或者Druid中,供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里的。
8. 层次调用规范
8.1. 不同需求阶段的规范
- 稳定业务,
- 按照标准的数据流向进行开发,即 ODS –> DWD –> DWS –> APP;
- 非稳定业务或探索性需求,
- 遵循 ODS -> DWD -> APP 或者 ODS -> DWD -> DWM -> APP 两个模型数据流。
8.2 分层引用原则
在保障了数据链路的合理性之后,也必须保证模型分层引用原则:
- 正常流向:
- ODS -> DWD -> DWM -> DWS -> APP;
- 当出现 ODS -> DWD -> DWS -> APP 这种关系时,说明主题域未覆盖全,应将 DWD 数据落到 DWM 中;
- 对于使用频度非常低的表允许 DWD -> DWS。
- 尽量避免:
- 避免出现 DWS 宽表中使用 DWD 又使用(该 DWD 所归属主题域)DWM 的表;
- 尽量避免同一主题域内,DWM 生成 DWM 的表,否则会影响 ETL 的效率。
- 禁止出现:
- DWM、DWS 和 APP 中禁止直接使用 ODS 的表, ODS 的表只能被 DWD 引用;
- 禁止出现反向依赖,例如 DWM 的表依赖 DWS 的表。
9. 数仓分层注意事项
- 分层是解决数据流向和快速支撑业务的目的;
- 必须按照主题域和业务域进行贯穿;
- 层级之间不可逆向依赖;
- 如果依赖ODS层数据可以完成数据支撑,那么业务方直接使用落地层这也有利于快速、低成本地进行一些数据方面的探索和尝试。
- 确定分层规范后,后续最好都遵循这个架构,约定成俗即可;
- 血缘关系、数据依赖、数据字典、数据命名规范等配套先行;