1. 数据模型
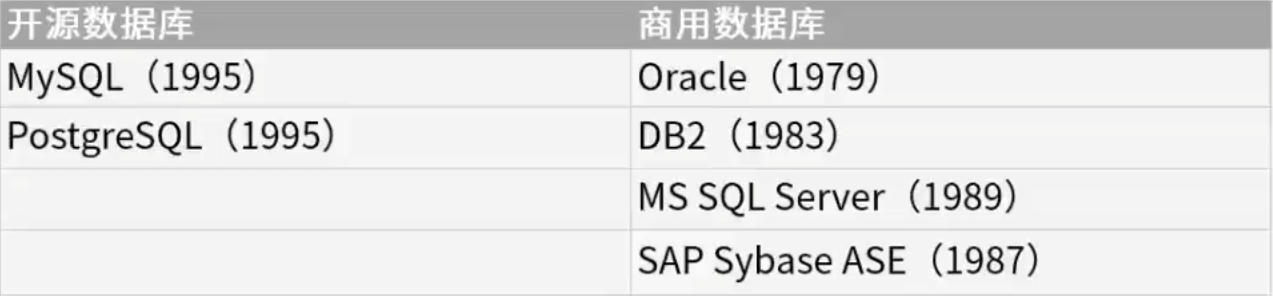
1.1. 数据库类型
- 关系型数据库
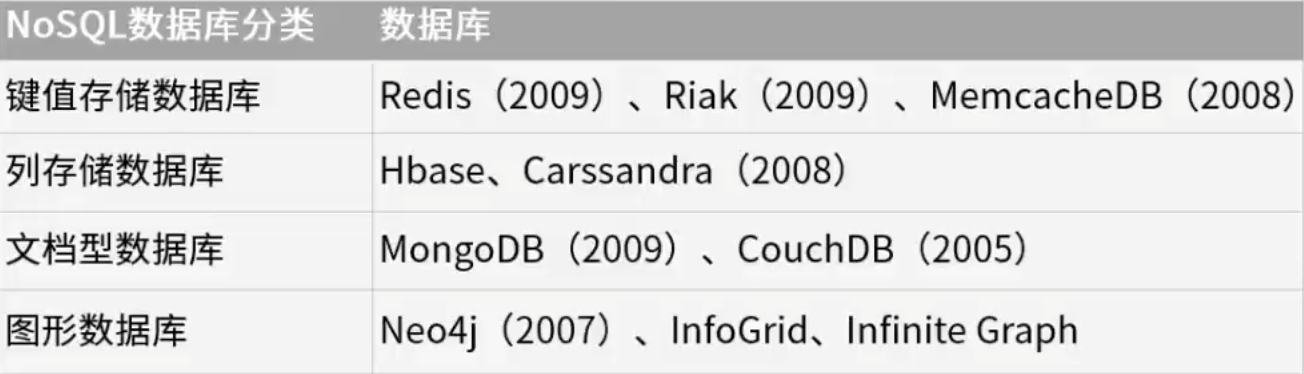
- 非关系型数据库
1.2. 数据模型的概念
信息 = 元数据 + 数据
数据模型,是将数据元素以标准化的模式组织起来,用来模拟现实世界的信息框架。
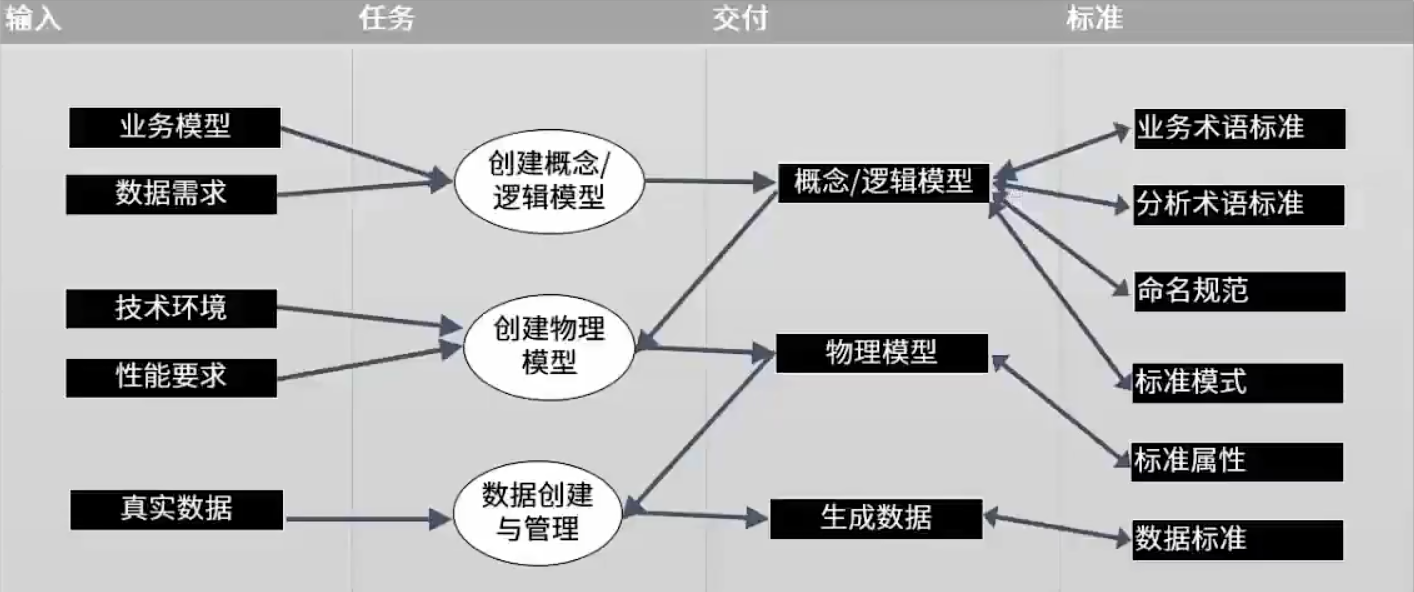
1.3. 数据建模流程图
1.4. 主题域划分方法
- 按照业务域划分
- 业务
- 指业务模块、业务线。
- 业务过程
- 指企业的业务活动事件,如下单、支付、退款都是业务过程,通俗的讲业务过程就是企业活动中的事件。
- 业务
- 按照数据域划分
- 数据域,是指面向业务分析,将业务过程或者维度进行抽象的集合。
- 其中,业务过程可以概括为一个个不可拆分的行为事件,在业务过程下,可以定义指标,维度是指度量的环境,如买家下单事件,买家是维度。
- 为保障整个体系的生命力,数据域是需要抽象提炼,并且长期维护和更新的,但不轻易变动;
- 在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时便于被包含进已有的数据域中、扩展新的数据域。
- 数据域,是指面向业务分析,将业务过程或者维度进行抽象的集合。
1.5. 数仓模型设计原则
- 高内聚、低耦合
- 即主题内部高内聚、 不同主题间低耦合;
- 明细层按照业务过程划分主题,汇总层按照“实体+ 活动”划分不同分析主题,应用层根据应用需求划分不同应用主题。
- 核心模型和扩展模型要分离
- 核心模型包括的字段支持常用的核心业务,扩展模型包括的字段支持个性化或少量应用的需要;
- 不能让扩展模型的字段过度侵入核心模型,以免破坏核心模型的架构简洁性与可维护性。
- 公共处理逻辑下沉及单一
- 越是底层公用的处理逻辑,越应该在数据调度依赖的底层进行封装与实现;
- 不要让公用的处理逻辑暴露给应用实现,不要让公共逻辑多处同时存在。
- 成本与性能平衡
- 适当的数据冗余可换取查询和刷新性能;
- 同时不宜过度冗余与数据复制。
- 模型可扩展性
- 不能新增业务、就建新表,应在模型设计之初就考虑未来如何扩展;
- 数据可回滚
- 处理逻辑不变,在不同时间多次运行数据结果确定不变。
2. 低质量的数据模型
2.1. 数据模型的常见问题
- 没有准确捕获需求
- 主要是需求调研不够、沟通不充分、需求理解不准确、测试不详尽导致的;
- 会导致系统上线后,许多功能无法满足,进而出现表结构的大量的调整;
- 比如:子公司 HR 系统中员工编号不统一,导致数仓中员工编号重复。
- 数据模型不完整
- 主要指的是元数据不完整;
- 常见的问题是,业务系统表设计的时候没有数据字典,数仓建设时无法理解表结构;
- 各层模型与其角色不匹配
- TODO
- 数据结构不合理
- 主要指表结构设计不合理
- 比如:
- 主键设计失误导致主键数据为空;
- 同一字段在不同表含义、属性、长度不一致;
- 抽象化不够,模型不灵活
- TODO
- 没有遵循命名规范
- 主要是表、字段命名太随意
- 汉语拼音、汉字做字段
- 缺少数据模型的定义和描述
- 常见的问题,如:
- 表、字段缺少注释;
- 表、字段命名不符合见名知意原则;
- 常见的问题,如:
- 模型可读性差
- 主要集中在缺少标准化的管理工具和管理文档,比如:
- 直接使用 DDL、Word、Excel 管理模型;
- 没有 ER 图;
- 缺少数据字典;
- 主要集中在缺少标准化的管理工具和管理文档,比如:
- 元数据与数据不匹配
- 常见的问题,比如:
- 在客户表中,为图方便存储了供应商、代理商信息,导致维护表时无所适从;
- 常见的问题,比如:
- 数据模型与企业标准不一致
- 业务系统在建设的时候,实施单位只考虑项目需要,没有统一的企业级规范。
2.2. 低质量模型的危害
- 大量修改和重做;
- 重复建设;
- 每做一个新需求,都需要重新建库、建表;
- 知识丢失;
- 主要指的是缺乏文档;
三个月内 DBA 知道,三个月后鬼才知道。
- 主要指的是缺乏文档;
- 下游开发困难;
- DATA Market 不理解表含义;
- 高成本;
- 沟通成本、时间成本、培训成本;
- 数据质量低;
- 阻碍新业务展开。
3. 高质量的数据模型
3.1. 理想的数据模型
数据模型的要求:
- 直观模拟真实世界;
- 容易被人理解;
- 便于被计算机实现;
- 框架稳定、灵活;
- 能满足当下和未来的需求;
- 全局视角;
- 高性能;
- 低冗余;
- 易访问;
- 易接入;
- 易开发;
- 易维护。
3.2. 高质量数据模型的价值
- 高效率;
- 灵活应对变动;
- 方便系统集成;
- 简化接口;
- 低冗余;
- 低风险;
- 灵活容纳新数据;
- 低成本。
数据模型牵一发而动全身,一旦搭建好以后,就不要轻易作出改动,否则不仅会影响下游的数据库、表,还有会影响与之关联的代码程序。
4. 概念模型
概念模型环节,需要确定系统的核心,划清系统范围和边界。
4.1. 概念模型包括的内容
- 实体关系图(关联关系);
- 核心业务流程;
- 组织架构(角色权限);
- 业务内容:
- 行业术语;
- 特殊流程;
- 专有术语;
- 用户群体;
4.2. 概念模型要注意的问题
- 注重全局、而非关注细节;
- 开始考虑整体架构、物理模型的实现;
- 如:
- 是否要上云计算、
- 分布式还是集中式系统、
- 容量及并发情况、
- 选择开源产品还是商业产品、
- 是否有特殊需求如 nosql、
- 用 3NF 建模还是维度建模
- 如:
- 概念模型通常是自上而下模式,需要与基层反复沟通确认需求;
- 粗略估算项目时间
- 给出项目计划草案
- 估算项目费用预算
- 包括硬件设备、软件、人员等;
- 数据工程师应该与业务部门之间建立良好的关系;
- 应划定系统边界、避免方向性错误;
- 最核心的,是确定那些东西不做;
- 需要业务部门支撑;
4.3. 概念模型交付品的特点
- 与客户一致的商业语言;
- 一页纸描述清楚;
5. 逻辑模型
逻辑模型环节,着重梳理业务规则,了解底层的数据细节。这个环节占据数据建模时间的 80% 以上。
5.1. 逻辑模型包括的内容
- 主题:
- 有多少个主题;
- 每个主题包含的实体,比如:
- 客户;
- 商品;
- 店铺;
- 订单;
- 金额;
- 等。
- 实体的属性
- 比如:
- 客户属性包括:客户编号、客户姓名、电话、住址、性别、年龄……
- 比如:
- 实体间关系
- 比如:
- 客户编码,来自客户实体(客户信息维度表);
- 商品编号,来自商品实体(商品信息维度表);
- 比如:
- 关系约束
- 即不同实体间的关系约束;
- 比如:
- 订单与客户之间为关系约束;
- 客户编码唯一;
- 一个订单,只能对应一个客户;
- 一个客户,可以对应多个订单;
5.2. 逻辑模型要注意的问题
- 实体数量超过 100 时,需要定义术语表;
- 先试用 3NF 规范化建模,再逆规范化、进一步优化;
- 使用 CASE 工具做逻辑建模工具;
- 如:PowerDesigner
使用 CASE 工具,可以直接将逻辑模型、转换为物理模型。
- 如:PowerDesigner
- 需要定期做同级评审,不能闭门造车;
- 在使用外部数据前,需要先检验数据质量是否合格;
- 关键属性,要用真实数据做验证,不要上来就用;
- 参考成熟的建模模式
- 如:Pattern
- 需要对数据做一定的抽象化处理;
- 需要做高质量的模型定义;
- 重要的关联关系,需要强制建立主外键;
- 逻辑模型,需要与关系模型保持一致;
- 注意模型的版本管理;
- 需要数据库专家 DBA 借入;
- 注意细节;
- 不要忽略属性的长度定义和约束定义;
- 不要忽略属性的默认值;
- 使用控制数据范围的域;
- 逆规范化在这一层完成。
5.3. 逻辑模型交付品的特点
- 所有的实体,都需要添加属性;
- 实体间的关系,需要描述清楚;
- 使用术语表;
- 严格遵循命名规则;
- 使用 case 工具创建项目文件;
6. 物理模型
6.1. 物理模型包括的内容
- 字段类型、长度
- 是否可为空
- 默认值
- 所属的域
- 字段值定义
- 比如字段为枚举类型,每个枚举值对应的具体含义是什么;
- 约束
- 唯一主键
- 唯一值
- 强关系约束
- 术语表
- 缩写规范
6.2. 物理模型要注意的问题
- 不直接生成,使用 CASE 工具由逻辑模型自动生成;
- 使用术语表,自动转换生成字段名称;
- 对表空间、索引、试图、物化视图、主键、外键等,都有命名规则;
- 逆规范化不在物理层完成,而是在逻辑层完成;
- DBA 深度介入,需要 DBA 的评审;
- 物理层模型,需要和数据库的 DDL 保持一致;
- 注意版本管理,开发、测试、生产一定要分开管理;
- 需要注意性能;
- 估算数据规模;
- 考虑数据归档;
- 应充分考虑未来使用数据库的优缺点,选择合适的数据库;
6.3. 物理模型交付品的特点
- 自动生成基础库表结构;
- 必须选择合适的数据库;
- 需要生成并发布数据字典;
- 可以直接生成 DDL;
- DDL 中需要注意注释文本;