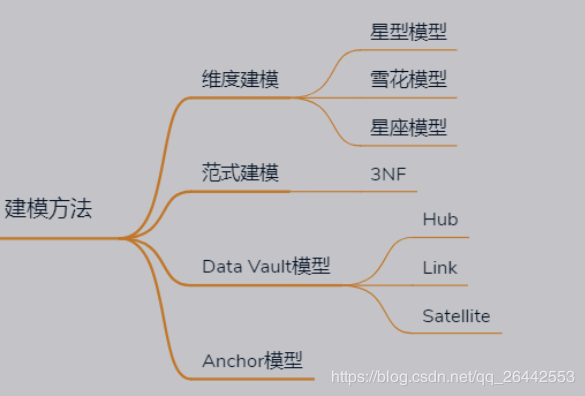
1. 常见的数据建模方法
- 数据仓库本质是从数据库衍生出来的,所以数据仓库的建模也是不断衍生发展的。
- 从最早的借鉴数据库的范式建模,到逐渐提出维度建模,Data Vault模型,Anchor模型等等,越往后建模的要求越高,越需满足3NF,4NF等。
-
对于数据仓库来说,目前主流还是维度建模,会夹杂着范式建模。
2. 维度表
2.1. 维度表概念
- 维度表,顾名思义就是一些维度信息,这种表数据,一般就直接存储维度信息,很多时候维度表都不会很大。
- 维度表,一定是被共享的、通用性的,
在数仓系统内,一项维度只会有一张维度表;
- 维度表,轻易不会做变更修改,
维度可以增加,但是不要轻易做修改和删除操作;
- 维度表,会与事实表的维度列做外键关联,使事实表可以生成更多的维度信息;
- 维度表的属性,是所有查询约束和报表标示的来源;
- 维度提供数据的入口点,提供所有 DW/BI 分析的最终标识和分组。
2.2. 维度表设计
- 一般会把维度信息单独存放,其他表要使用时,记录对应维度的id即可。这样,就算维度表中数据发生了变化,其他表数据因为只是记录了id,不会有影响。
- 维度信息放在一张表中存放,而不是每个表中存储一份,将来需要调整,只需要做一次工作即可,降低了数据冗余。
- 维度表用于描述环境,多使用单一主键;
2.3. 维度分类
- 退化维度(DegenerateDimension)
- 退化维度,指的是直接把一些简单的维度放在事实表中;
- 退化维度是维度建模领域中的一个非常重要的概念,它对理解维度建模有着非常重要的作用,退化维度一般在分析中可以用来做分组使用;
- 缓慢变化维(Slowly Changing Dimensions)
- 维度的属性并不是始终不变的,它会随着时间的流逝发生缓慢的变化,这种随时间发生变化的维度我们一般称之为缓慢变化维(SCD);
- 比如员工表中的部门维度,员工的所在部门有可能两年后调整一次。
如果按照范式建模规范,维度建模会存在大量冗余,但这些冗余在维度建模中是必要的的。
3. 事实表
3.1. 事实表概念
- 事实表,就是表述一些事实信息,如订单、收藏,添加购物车等信息,这种数据量较大;
- 事实表由维度和度量组成,事实表中存储的是维度信息(维度列)、以及可度量的值(属性列);
- 比如:区域销售表中,地区是维度,而销售额是度量;
- 事实表用于存储的是属性的度量;
3.2. 事实表设计
- 事实表中的维度,一定会对应一张维度表;
- 事实表一般会有两个或者多个外健,与维度表的主键进行关联;
- 事实表的主键一般是组合健,表达多对多的关系。
- 事实表中一般会使用一个代号、或者整数(如:ID)来代表维度成员,而不是描述性的名称;
- 比如:区域销售统计中,地区一般记录地区ID,而不是地区名称;
- 因为数据可能会变化,事实表一般存储维度主键,具体维度值在后续处理分析时再临时关联;
3.4. 事务事实表
- 事务事实表概念:
- 事务事实表,用于承载事务数据,通常粒度比较低;
- 事务事实表,是面向事务的,其粒度是每一行对应一个事务;
- 事务事实表,是最细粒度的事实表,例如产品交易事务事实、ATM交易事务事实;
- 事务事实表缺陷:
- 大表 join 大表,性能会比较低;
- 例如:
- 对下单事实表、和支付事实表,统计平均下单后支付时间,两个表都是大表,join 查询会很慢;
3.5. 周期快照事实表
- 周期快照事实表概念:
- 周期快照事实表,按照一定的时间周期间隔(每天,每月)来捕捉业务活动的执行情况,一旦装入事实表就不会再去更新,它是事务事实表的补充。
- 用来记录有规律的、固定时间间隔的业务累计数据,通常粒度比较高,
- 使用场景:
- 存量记录:
- 账户月余额;
- 商品库存;
- 状态记录:
- 空气温度;
- 汽车行驶速度;
- 状态是连续的,必须进行周期性采样,构建周期快照事实表;
- 存量记录:
- 周期快照事实表,与事务事实表,是互补关系,二者可以同时存在;
- 示例:
- 统计: 每日-仓库-商品-数量;
3.6. 累积快照事实表
- 累积快照事实表概念:
- 累积快照事实表,用来记录具有时间跨度的业务处理过程的整个过程的信息;
- 累积快照事实表,每个生命周期一行,通常这类事实表比较少见。
- 累积快照事实表示例:

4. 星型模型
-
星型模型主要是维表和事实表,以事实表为中心,所有维度直接关联在事实表上,呈星型分布。
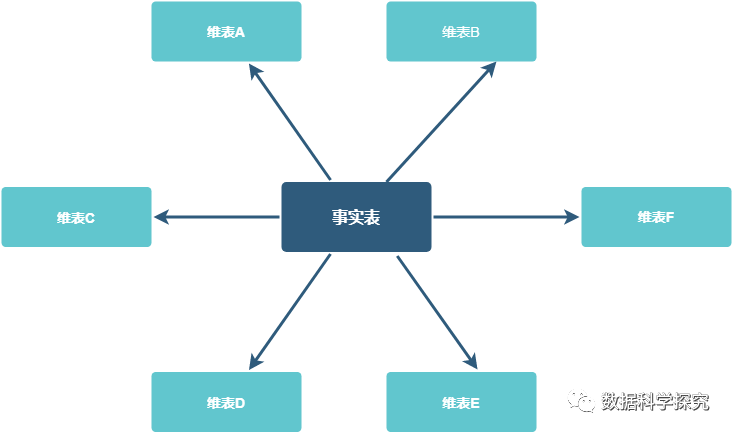
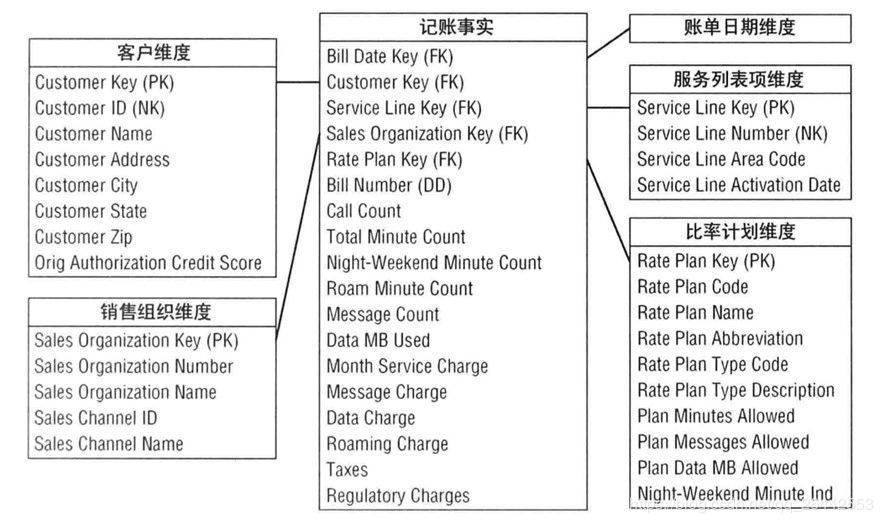
示例:
5. 雪花模型
- 雪花模型,维度表的涉及更加规范,一般符合3NF;
- 雪花模型,有效降低数据冗余,维度表之间不会相互关联;
-
相比星型模型,雪花模型的特点是贴近业务,数据冗余较少,但由于表连接的增加,导致了效率相对星型模型来的要低一些。
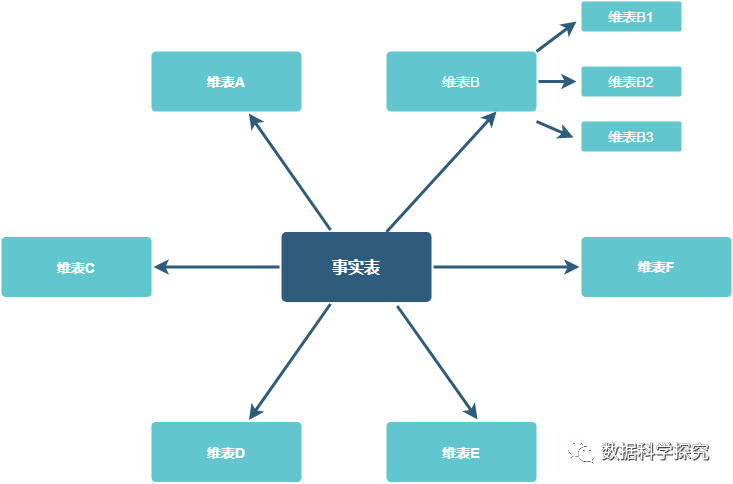
6. 星座模型
- 星座模型也是星型模型的扩展;
- 区别是星座模型中存在多张事实表,不同事实表之间共享维表信息,常用于数据关系更复杂的场景;
-
其经常被称为星系模型。
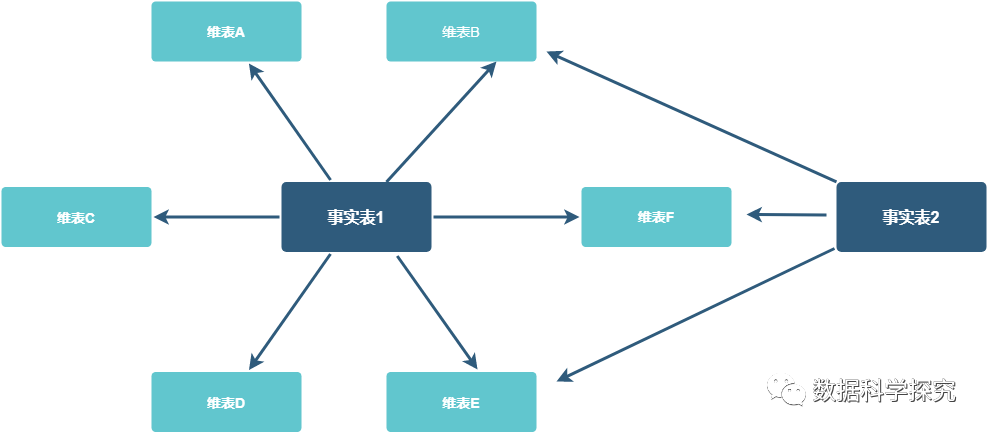
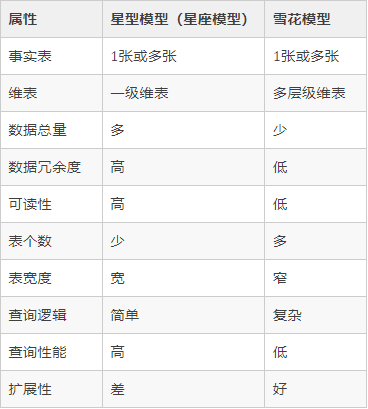
星型模型 VS 雪花模型
- 星型模型,一般采用降维的操作,反规范化、不符合3NF,利用冗余来避免模型过于复杂,查询时只需要做少量的表链接,以提高易用性和分析效率,星型模型效率相对较高;
雪花模型,维度表的涉及更加规范,一般符合三范式,有效降低数据冗余,维度表之间不会相互关联。雪花模型,可以看做是星型模型额变种。
- 星型模型和雪花模型的区别在于:维度表是直接连接到事实表还是其他维度表。
7. 维度建模的常规步骤
7.1. 选择业务过程
- 业务过程,通常表示的是业务执行的活动,与之相关的维度描述和每个业务过程事件关联的描述性环境;
- 通常由某个操作型系统支持,例如:订单系统;
- 业务过程建立或获取关键性能度量;
- 一系列过程产生一系列事实表;
7.2. 声明粒度
- 粒度传递的是与事实表度量有关的细节级别;
- 精确定义某个事实表的每一行表示什么;
- 对事实表的粒度要达成共识;
- 粒度是非常重要的,粒度用于确定事实表的行表示什么;
7.3. 确认维度
- 健壮的维度集合来粉饰事实表;
- 维度表示承担每个度量环境中所有可能的单值描述符;
7.4. 确认事实
- 不同粒度的事实必须放在不同的事实表中;
- 事实表的设计完全依赖物理活动,不受最终报表的影响;
- 事实表通过外健关联与之相关的维度;
- 查询操作主要是基于事实表开展计算和聚合。
8. 维度表的设计
8.1. 主键设计
- 维度表的唯一主键,应该是代理键,而不是来自系统的标示符,也就是所谓的自然健;
- 因为自然键通常具有一定的业务含义,但日久天长,这些信息是有可能发生变化的;
- 而代理健可以提高关联效率并将关系数据库设计和业务的解耦;
- 维度表和事实表关联的每个连接应该基于无含义的整数代理健;
8.2. 事实表粒度
- 建议从关注原子级别的粒度数据开始设计,因为原子粒度能够承受无法预估的用户查询;
- 注意可能的下钻需求,原子数据可以以各种可能的方式进行上卷,而一旦选择了高粒度,则无法满足用户下钻细节的需求;
8.3. 维度退化
- 固定深度层次在维度表中应该扁平化;
- 规范化的雪花模型不利于多属性浏览;
- 而且大量的表和连接操作会影响性能;
- 非完全独立的维度应该合并为一个维度,将同一层次的元素、标示为事实表中不同的维度是错误的,会增加查询和存储负担,最后变成蜈蚣表;
- 例如:日维度、周维度、月维度等可以合并为一个周期维度。
- 维度退化的目的:
- 方便浏览;
- 减少 join;
8.4. 维度表示例
- 售前流程的雪花模型:
- 事实表:客户创建信息表;
- 维度表:销售信息表、店铺信息表、跟进表/约见表/风控通过表/订单表的维度上卷。
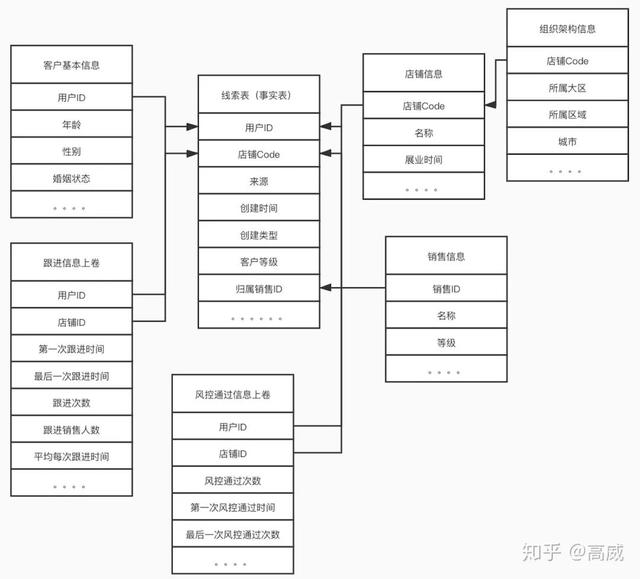
9. DataVault 模型
9.1. DataVault 模型三种基本结构
- 中心表-Hub
- 唯一业务键的列表,唯一标识企业实际业务,企业的业务主体集合
- 链接表-Link
- 表示中心表之间的关系,通过链接表串联整个企业的业务关联关系
- 卫星表-Satellite
- 历史的描述性数据,数据仓库中数据的真正载体
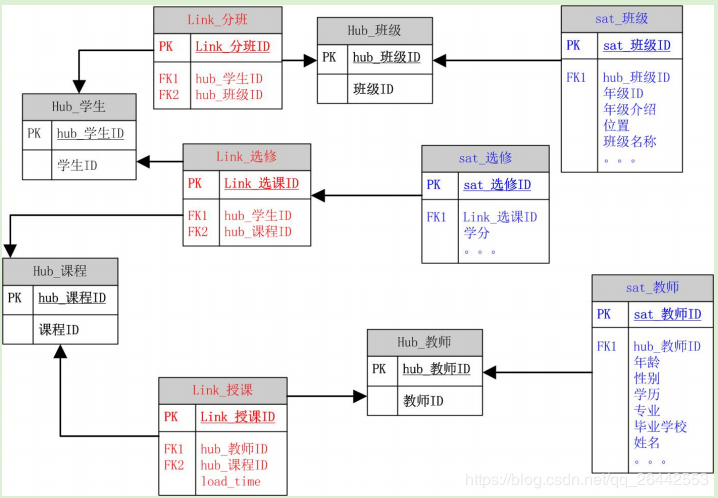
- Hub 像人体的骨架,Link 是连接骨架的韧带组织,而 satelite 就是骨架上的血肉;
- DataVault 是对 E-R模型 更近一步的规范化,由于对数据的拆解和更偏向于基础数据组织;
- DataVault 在处理分析类场景时相对复杂,适合数仓低层构建,目前实际应用场景较少。
9.2. DataVault 建模流程
- 梳理所有主要实体;
- 将有入边的实体定义为中心表;
- 将没有入边切仅有一个出边的表定义为中心表;
- 源苦衷没有入边且有两条或以上出边的表定义为连接表;
- 将外键关系定义为链接表;
10. Anchor 模型
Anchor 是对 DataVault 模型做了更近一步的规范会处理,初衷是为了设计高度可扩展的模型,核心思想是所有的扩张只添加而不修改,于是设计出的模型基本变成了 k-v 结构的模型,模型范式达到了6NF;
由于过度规范化,使用中牵涉到太多的 join 操作,因而开发效率和执行性能都是严重挑战。