1. 范式建模的概念
1.1. 三范式 & 四范式 & 五范式:
- 第一范式:
- 保证数据的原子性,没有重复列,列不可再分,也没有重复行;
- 数据规整成二维表;
- 确保每一列表达同一含义;
- 比如成绩中,分数和评价,要拆分成两列;
- 去掉多值属性;
- 比如:地址信息,拆分成省、市、区、详细地址;
- 拆成多列;
- 比如:一个人有多个电话号码,应拆分成电话_1、电话_2;
- 去掉重复组,挪到新表里面;
- 不好拆分的列,可以单独建表;
- 比如:每个人都有多个电话,就可以单独建一个电话号码表,新表中每一行、写入一组人员ID+电话号码;
- 确定主键;
- 确保每一行都是唯一的;
- 第二范式:
- 确保表中的每列都和主键相关;
- 也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中;
- 如果不遵守第二范式:
- 会比存在数据冗余;
- 同时存在数据不一致的风险;
- 另外,关系也会被隐藏在表中,不能很直观的展示出来;
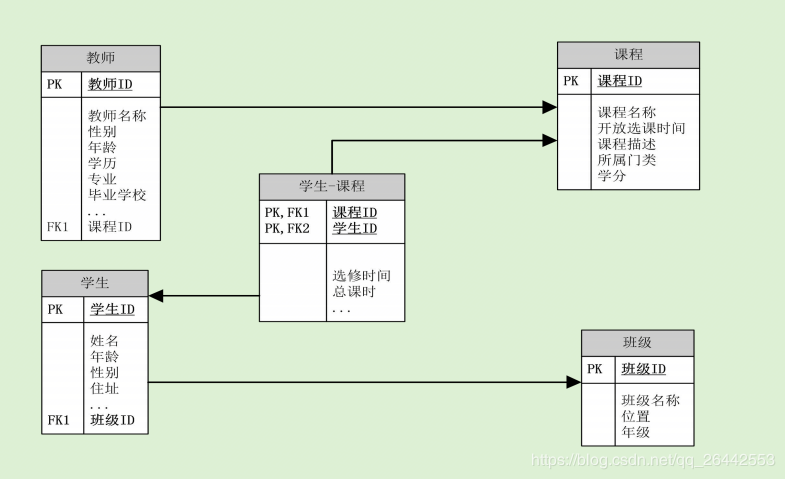
- 比如:下方学生成绩表中,学生姓名、学生课程,各自都只与主键学号有关,这是就应该拆分成两个表;
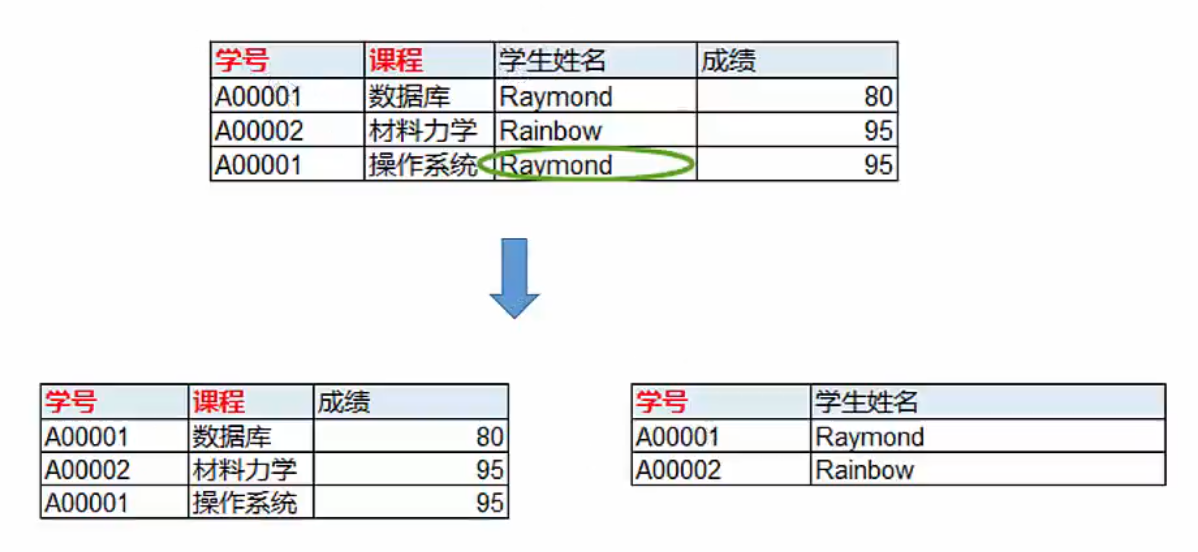
-
第三范式
- 非主键属性只能依赖于主键,不能依赖于其他非主键属性;
- 如果非主键属性、依赖于其他非主键属性,则需要移出去创建新表;
- 比如:下方学生班级成绩表中,班级名称依赖于班级编号,而不是主键学号,这是就应该分拆成两个表;

-
BCNF
- BCNF 中,任何属性(包括主属性和非主属性),都不能被非主属性所决定;
- BCNF 必须规避下面的问题:
- 存在联合主键;
- 存在多个可选键;
- 可选键存在重叠;
- 比如:下表中,班级+课程、班级+教师,都可以作为联合主键,就可以拆分成两个表;
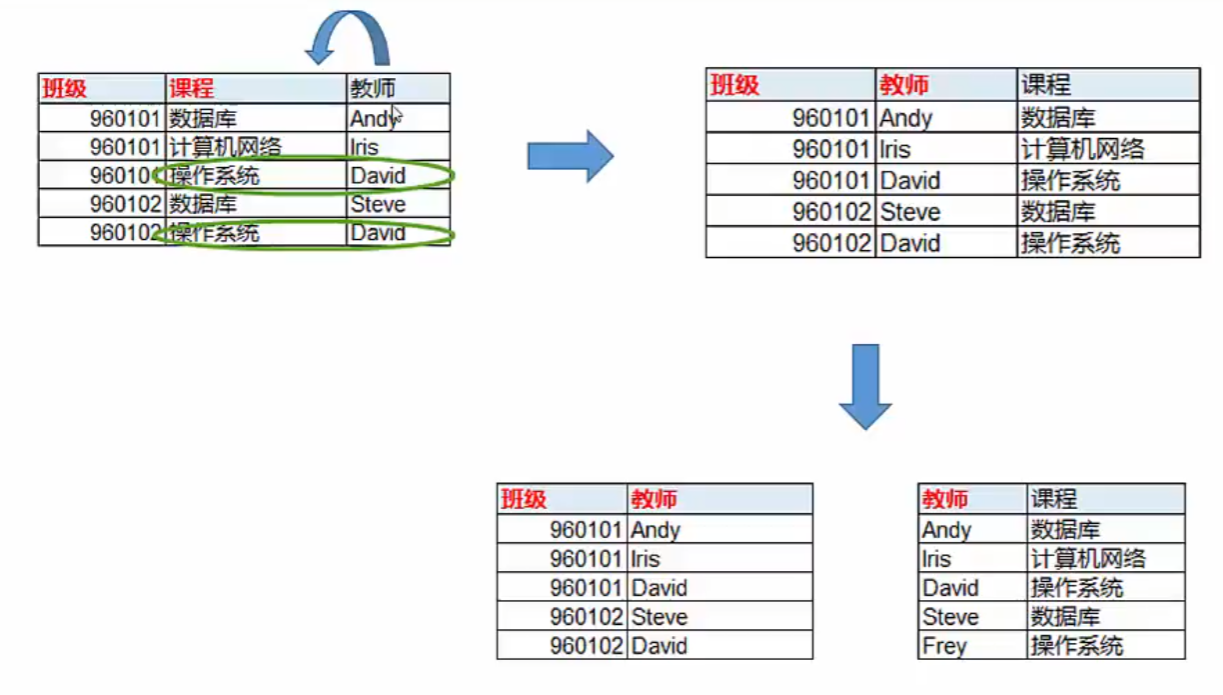
-
第四范式
- 多值依赖;
- 多值依赖:三个属性A、B、C在一起做联合主键,AB、AC都存在依赖关系,并且B和C之间没有依赖关系;
- 第四范式就是要消除多值依赖;
- 比如:下表中,学号、课程、语言做联合主键,学号+课程、学号+语言,是相互依赖的,但是课程和语言没有依赖关系,这时候就要拆分成两个表;
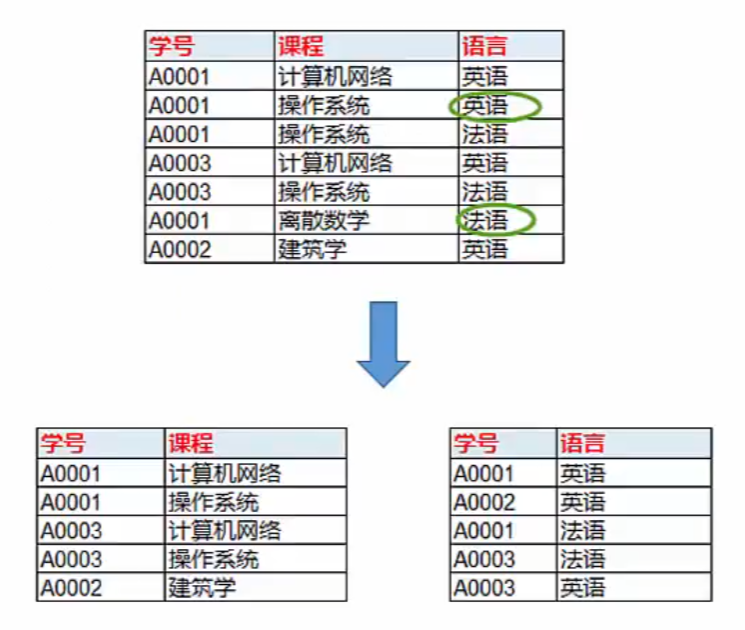
- 第四范式下:
- 数据冗余会减少;
- 数据关系会更清晰;
- 多值依赖;
-
第五范式
- 连接依赖:
- 连接依赖:三个属性A、B、C在一起做联合主键,AB、AC、BC都存在依赖关系;
- 第五范式就是要消除连接依赖;
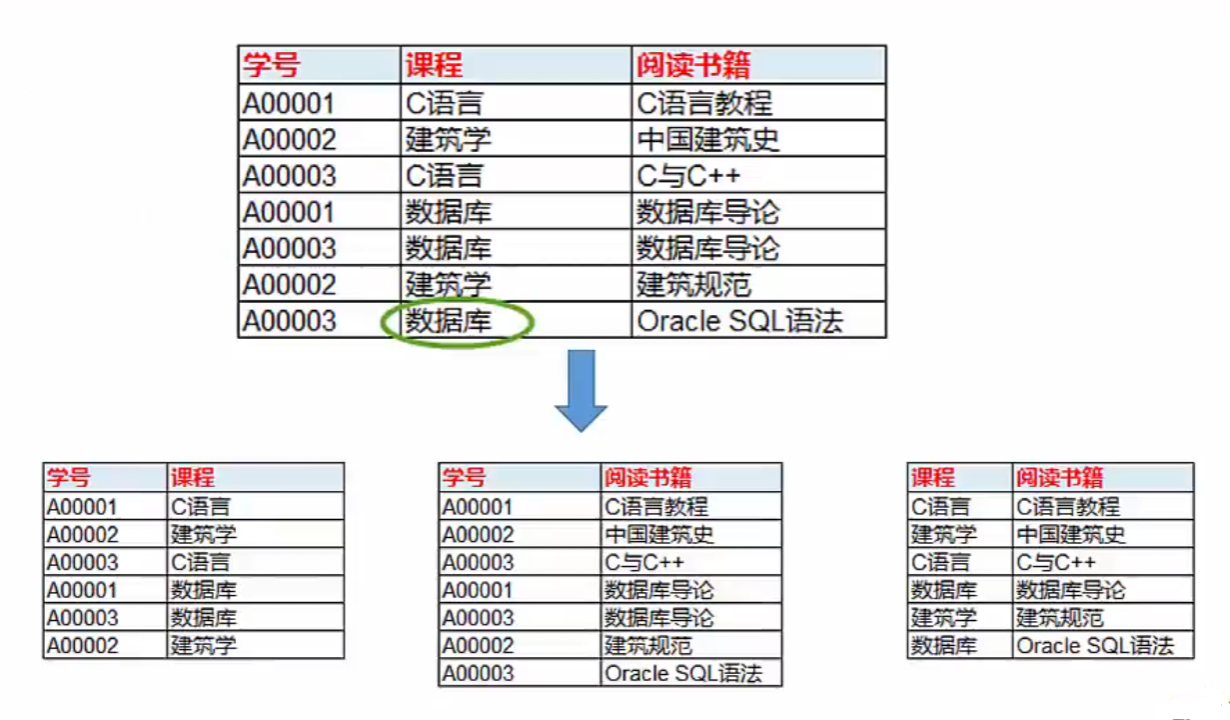
- 连接依赖:
- 范式模型常见表类型:
- 主数据表;
- 参照数据表;
- Xref 表;
- 事务表;
- 三范式的优点:
- 减少冗余,同一含义的数据只存一份;
1.2. E-R 模型
-
E-R 模型的组成是由实体,属性和联系。
- 实体 Entity
- 实体,是具体事物的抽象化描述,是数据库中存储的所有信息;
- 实体,对应数据库的表;
- 实体中的实例,指的就是一行行的数据;
- 每个实体(除非是弱实体)都必须有一个唯一标识属性的最小化集合。这个集合叫做实体的主键。
实体,通常指的是业务场景中【名词】,也指一个要处理的抽象的【对象】。
-
关系 Relationship
- 一对一
- 指实体之间的关系是一一对应的,比如个人与身份证信息之间的关系就是一对一的关系。
- 一对多
- 指一边的实体通过关系,可以对应多个另外一边的实体。相反,另外一边的实体通过这个关系,则只能对应唯一的一边的实体。
- 比如说,我们新建一个班级表,而每个班级都有多个学生,每个学生则对应一个班级,班级对学生就是一对多的关系。
- 多对一
- 与一对多情况相反。
- 多对多
- 指关系两边的实体都可以通过关系对应多个对方的实体。比如在进货模块中,供货商与超市之 间的关系就是多对多的关系,一个供货商可以给多个超市供货,一个超市也可以从多个供货商那里采购商品。
- 一对一
- ER图示例
2. 实体 Entity
2.1. 实体的定义
- 实体是一个数据的使用者,其代表软件系统中客观存在的生活中的实物,如人、动物,物体、列表、部门、项目等,而同一类实体就构成了一个实体集。
- 实体中的所有特性称为属性,如用户有姓名、性别、住址、电话等。
- “实体标识符”是在一个实体中,能够唯一表示实体的属性和属性集的标示符,但针对于一个实体只能使用一个”实体标识符”来标明。实体标识符也就是实体的主键。
- 实体不会是单独存在的,实体和其他的实体之间是有着千丝万缕的联系的。
2.2. 实体的分类

3. 属性 Attribute
3.1. 属性的定义
- 属性,对应的是表的列;
- 在关系型数据库中,属性通常都是单值的;
- 如果存在多值,则需要另外建属性表;
3.2. 属性的分类
- ID;
- 标识实体的唯一性,一般是唯一主键;
- 描述;
- 引用;
- 引用的其他实体的信息,比如订单表中会引入商品信息、客户信息,就需要加入商品ID、客户ID;
- 分类;
- 实体所属的分类,比如客户分为国内客户、国外客户;
- 注意:不同分类方法,会对应不同的属性值,需要注意对应关系和唯一性;
- 限制;
- 比如:最低价格;
- 数量;
- 比如:订单的采购数量、交易的金额等;
- 时间相关;
- 日期型;
- 时间戳性;
- 时间型;
- 人物相关;
- 比如:企业法人;
- 组织相关;
- 比如:销售门店;
- 地点相关;
- 比如:城市、国家、IP地址;
- 途径相关;
- 比如:销售途径平台电商、自建独立站、直播间、代理商;
- 站点相关;
- 比如:APP、web 站;
- 状态;
- 比如:员工在职、离职;
- 审计;
- 数仓中最常用的;
- 创建、修改间戳;
- 比如:add_time、update_time;
- 操作人;
- 订单录入人、系统自动生成等;
- 数据来源;
- 数据的来源;
- 比如:客户姓名、来自于客户信息系统,就要标注客户信息系统ID;
- 派生;
- 预计算数据;
- 数据内容的 MD5 校验码;
- ETL 数据对账中经常使用;
3.3. 属性的特性
- 强制 / 可选
- 属性值是否可以为空;
- 原子 / 组合
- 比如:姓、名都是原子的,二者在一起,组合构成姓名;
- 直接 / 派生
- 比如:国家 + 省 + 城市 + 街道 + 门牌号 = 详细地址;
- 单值 / 多值
- 关系型数据,不支持单实体、多属性,否则会违反 3NF,需要单独建子表;
- 可选键
- 某一属性、或多个属性,可以作为判断唯一性的标识,即唯一键;
- 数据类型
- INT、CHAR、DATE 等等;
- 默认值
- 如果没有值,则赋与其默认值;
- 比如:审计中的更新时间,为系统自动生成时间 current timestamp;
- 派生属性计算逻辑
- 比如:手机号前缀(如+86) + 手机号 = 完整手机号;
4. 值域 Domain
4.1. 值域的定义
- 值域,指的是属性所有取值范围的集合;
- 值域,可以理解为自定义的数据类型,同时可以加上约束条件;
- 值域范围,需要根据实际的业务场景决定取值范围;
4.2. 值域的类型
- 格式:
- varchar;
- currency;
- email;
- 正则表达式匹配 @ 符:
- 身份证号;
- 位数限制、校验码;
- 等等;
- 列表:
- 枚举;
- 比如:销售渠道包含淘宝店、京东店铺、抖音店铺,除此以外的值都是非法;
- 月份;
- 从 1月 到 12 月;
- 性别;
- Male、Female、Unknown;
- 名称:
- LongName:VARCHAR(255),容纳公司名称、其他名称;
- ShortName:VARCHAR(50),容纳人名、部门名称;
- 等等;
- 枚举;
- 范围:
- 年龄:0 ~ 100;
- 角度:-180 ~ +180;
4.3. 值域的作用
- 数据质量:
- 值域范围规范,可以大幅提高数据质量;
- 易懂易用:
- 数据模型会更加容易理解和使用;
- 数据标准化:
- 提高模型质量和建模效率;
4.4. 值域的应用
- PostgreSQL、Oracle;
注意:MySQL,不支持值域!!!
5. 关系
5.1. 一对一
指实体之间的关系是一一对应的,比如个人与身份证信息之间的关系就是一对一的关系。
5.2. 一对多
指一边的实体通过关系,可以对应多个另外一边的实体。相反,另外一边的实体通过这个关 系,则只能对应唯一的一边的实体。比如说,我们新建一个班级表,而每个班级都有多个学生,每个学生则对应一个班级,班级对学生就是一对多的关系。
5.3. 多对一
与一对多情况相反。
5.4. 多对多
指关系两边的实体都可以通过关系对应多个对方的实体。比如在进货模块中,供货商与超市之 间的关系就是多对多的关系,一个供货商可以给多个超市供货,一个超市也可以从多个供货商那里采购 商品。
5.5. E-R 关系图
6. 键 Key
6.1. 候选键
- 一个或多个属性的结合,可以确定唯一实体;
- 比如:
- 员工编号、员工邮箱,都是唯一的,可以作为候选键;
6.2. 主键
-
从候选键中,选中作为唯一标识的属性、或者属性组;
- 主键的特点:
- 唯一性:不可重复;
- 强制性:不可以为空;
- 永久性:不可以改变;
- 最小集合:不可以掺杂多余的属性;
如果两个字段可以作为联合主键确定唯一值,就没有必要再加上第三个字段;
- 设计主键要注意的问题:
- 尽量不要使用 SmartKey;
- SmartKey,指的是存在含义的编码 Key;
- 比如:身份证号码,对应位置的数值,是有特殊含义的,比如行政区域,这就存在超级辖区人口数量暴增,导致数值溢出的风险;
- 不要将 ID 编码植入程序,
- 否则一旦编码变化、程序会出现很大问题。
- 比如:部门编码,指定位置指定对应的部门,但是如果组织架构调整,就会出现问题;
- 不能随着环境变化而收到影响
- 设计之初,就要考虑未来可能遇到的场景;
- 键值应易管理、易维护;
- 不要有人工输入;
- 尽量不要使用 SmartKey;
6.3. 单键 & 复合键
- 单键:
- 主键只有一个属性,称为单键;
- 复合键:
- 主键是多个属性的组合,称为复合键;
6.4. 自然键 & 代理键
- 自然键:
- 已经真实存在的键,通常具有真实的商业含义;
- 可以使单键,也可以是复合键;
- 灵活性:
- 自然键做主键,实体主键的变化、会带来外键相关表的连锁反应;
- 一旦 update,只能删除重做;
- 代理键:
- 完全没有商业含义,通常由系统自动生成;
- 灵活性:
- 代理键本身无意义,可以修改原自然键内容;
- 代理键 update 会更加容易;
- 使用场景:
- 完全没有自然键做主键;
- 分布式结构数据库,多联合主键的事实表,为了分区方便,创建单独的代理键,以避免数据分区的偏移;
- 外键:
- 引用其他表的主键;
6.3. 可选键
- 候选键中,没有选中的其他键;
6.4. 键的命名规则
- 自然键
- 代理键
- xxx_SK
- Checksum key
- xxx_CK
7. 约束
7.1. 唯一标识
- unique key;
7.2. 非空约束
- not null;
7.3. 默认值
- default;
7.4. 检查
- 属性取值符合规则;
7.5. 实体完整性(Entity integrity)
- 主属性不能为空值(即任一候选码的属性不能为空);
- 在实际上,只要主键属性不为空就好;
7.6. 参照完整性(Referential integrity)
- 这是对外键的约束:
- 外键只能有两种取值情况:
- 这个外键在对应的表中是存在的;
- 空值;
8. 建模经验
8.1. ID 设计
- 8位 / 10位 / 15位 流水号;
- 如果从 1、2、3 开始,ID 长度都会不一致,
- 设计规则
- 前 2位(3位) 对应业务系统,后面为流水号;
- 注意流水号要考虑到数据增长情况;
- 项目整体规范化、标准化;
8.2. 表名称统一命名
- 统一的命名规则
- ods_业务系统简称_业务系统原始表名称
- dwd_业务系统简称_业务系统原始表名称
8.3. 有限可穷举字段,一般用代码表示
- 主要是为了统一标准格式;
- 比如:国家、民族,长度不一致,
- 可以通过关联对应的字典表获取,
- 国家有统一发布的规范标准。
8.4. 第一范式必须严格遵守
- 遵守第一范式,是范式建模的基础
8.5. 数据与数据的关系,用表关联的方式体现出来
- 数据与数据的关系,用表关联的方式体现出来,而不是用数据内容来体现
8.6. 尽可能的减少冗余
- 同一含义的数据,尽可能只存一分
8.7. 一般不用第四范式和第五范式
- 第四范式和第五范式,可以参考但实际不常用;
9. 建模工具
- Powerdesigner
- E-Rwin;
- Datablau;