开发思路
- 小公司:
- 开源 SDK + 通用存储 + 通用 BI
- 大公司:
- 开源 SDK + OLAP 引擎 + 自研可视化
埋点系统搭建工作流程
- 梳理埋点需求(分析指标体系)
- 制定埋点规则
- 命名的规范化
- 埋点流程统一化
- 制定埋点数据的清洗规则
- 数据清洗规范化
- 维护埋点的测试、上线、下线
- 维护埋点元数据(埋点管理系统)
数据埋点上下游技术
-
数据采集
- 对行为数据采集部分我们一般封装为埋点采集的 SDK,然后嵌入到不同的客户端中。
- SDK 的作用在于封装好一些公共的参数信息、上报方式以及帮助各端开发简化数据上报的过程。
- 同时也在基础层面上支持类似可视化埋点、圈选埋点、全埋点等不同的埋点方式。
-
数据存储(含计算引擎)
- 在行为分析领域里面,现在最热门的是使用 Clickhouse 做存储及计算引擎,每日千亿级别的数据增量可以比较高效从容的进行行为数据分析。
- 对于数据并没有那么大的公司也可以根据自身情况选择诸如 Durid、Impala等计算引擎
-
数据可视化
- 分析的结果在大部分团队内部都希望能以可直观查看的方式进行展示,包括一些简单的图表、数据看板等。
- 如果选择完全自研的话成本比较高,一般的处理方式有两种,一种采用开源的图表组件进行二次开发,例如使用范围比较广的 Echarts、AntV 等进行定制化的图表开发。
- 另外也可以直接在上游的分计算引擎上直接接入传统意义上的 BI 可视化产品进行最终数据结果的展示。
数据埋点技术方案选择

- 采集
- 自主开发采集
- Nginx
- Logstash
- API
- 第三方 SDK
- 神策 SDK(鬼策 SDK)
- 易观 SDK
- 诸葛 SDK
- Mixpanel
- 阿里开源 SDK
- 自主开发采集
- 存储
- 通用存储
- TiDB
- Hive
- ES
- OLAP(性能更佳)
- Clickhouse(今日头条、B站)
- 查询并发比较小,只支持几百并发查询
- Impala(神策在用的引擎)
- Druid
- Kylin
- Presto
- Clickhouse(今日头条、B站)
- 通用存储
- 可视化
- 通用 BI产品
- PowerBI
- Tableau
- Metabase
- Superset
- 自研可视化
- 百度 Echarts
- 通用 BI产品
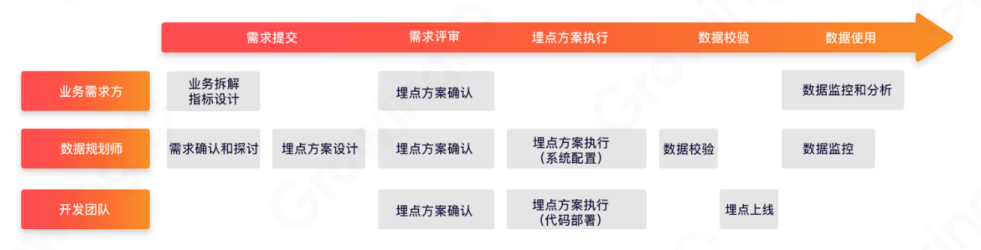
埋点项目开发流程示例