SELECT 语句执行顺序
- SELECT
- DISTINCT
- 数据除重
- FROM
- <表名> # 选取表,将多个表数据通过笛卡尔积变成一个表。
- ON
- <筛选条件> # 对笛卡尔积的虚表进行筛选
- JOIN <join, left join, right join…>
-
# 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中
-
- WHERE
-
# 对上述虚表进行筛选
-
- GROUP BY
- <分组条件> # 分组
<SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
- HAVING
- <分组筛选> # 对分组后的结果进行聚合筛选
- SELECT
- <返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外
- ORDER BY
- <排序条件> # 排序
- LIMIT
- <行数限制>
多表查询
表示例
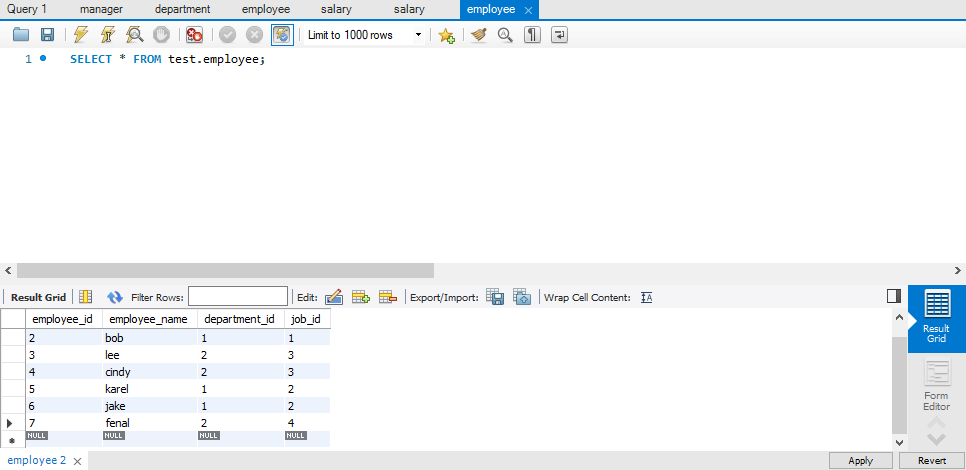
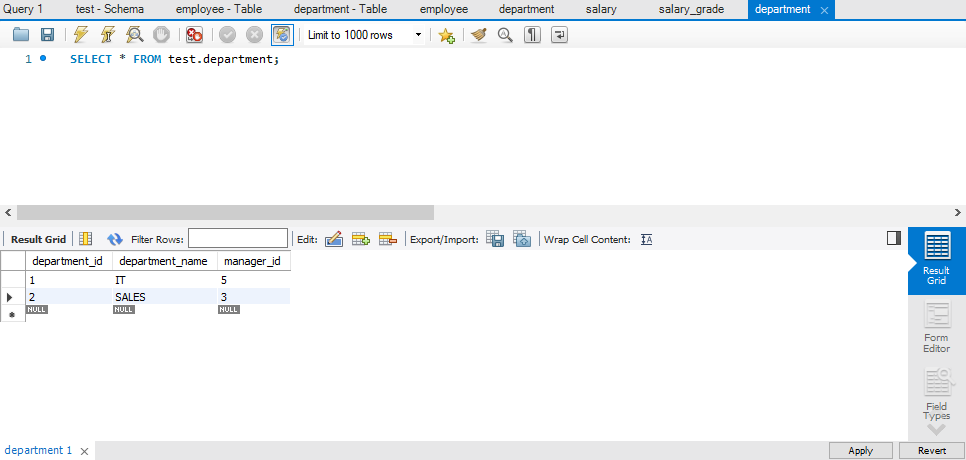
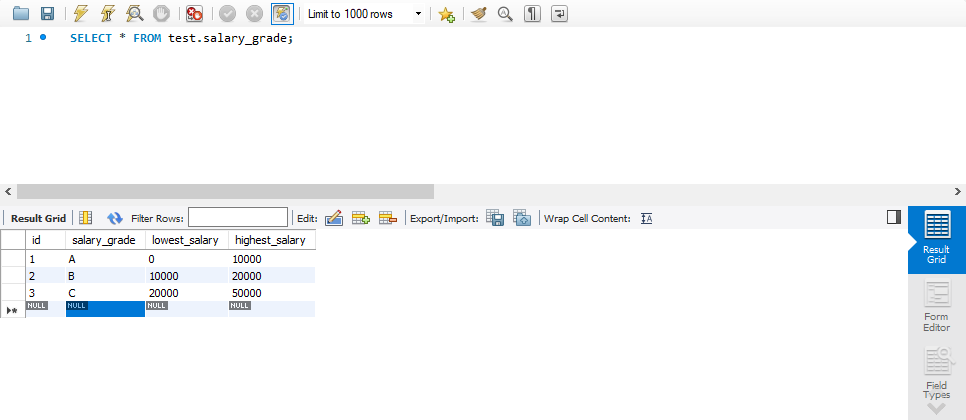
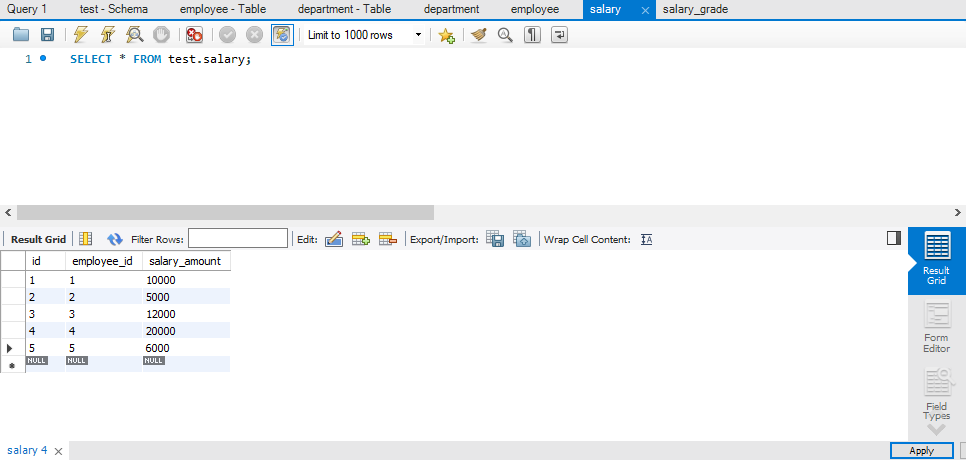
等值连接 & 非等值连接
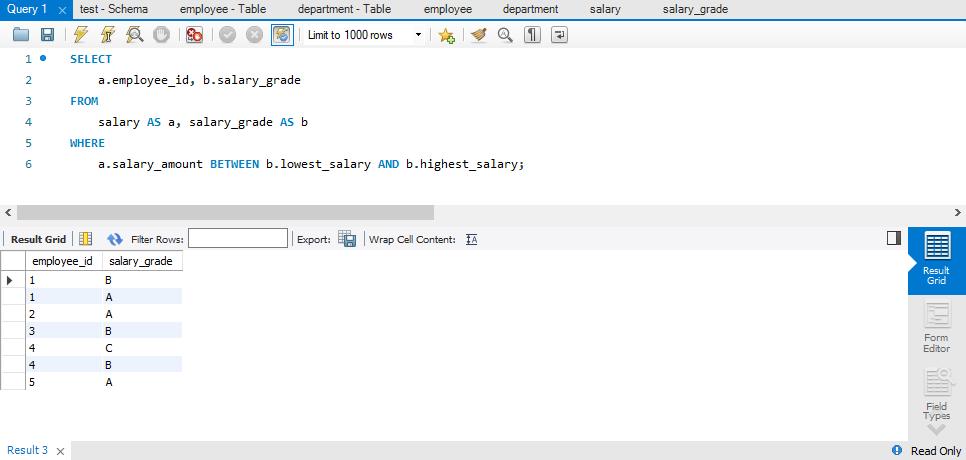
SELECT
a.employee_id, b.salary_grade
FROM
salary AS a, salary_grade AS b
WHERE
a.salary_amount BETWEEN b.lowest_salary AND b.highest_salary;
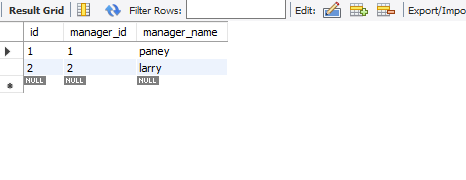
JOIN 使用
LEFT JOIN
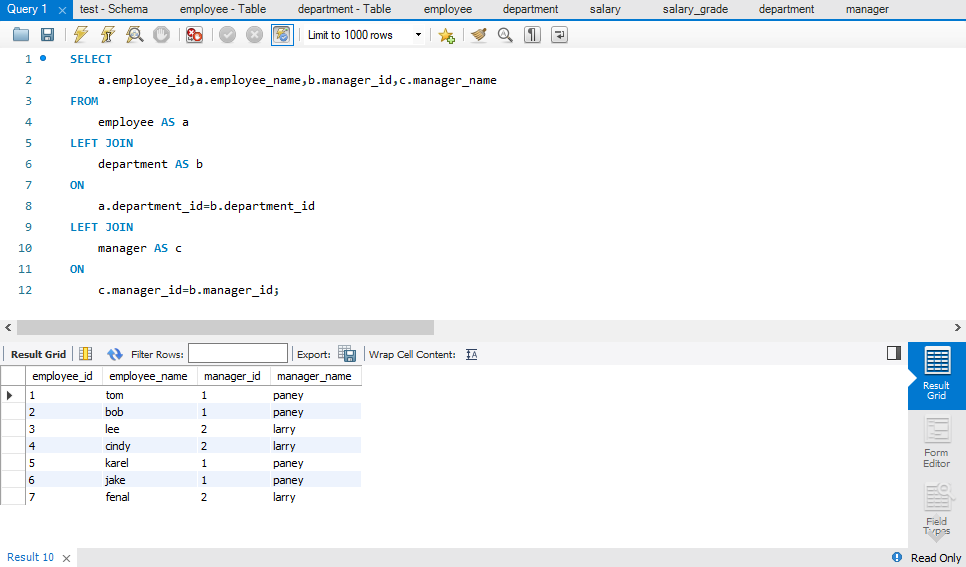
SELECT
a.employee_id,a.employee_name,b.manager_id,c.manager_name
FROM
employee AS a
LEFT JOIN
department AS b
ON
a.department_id=b.department_id
LEFT JOIN
manager AS c
ON
c.manager_id=b.manager_id;
UNION VS UNION ALL
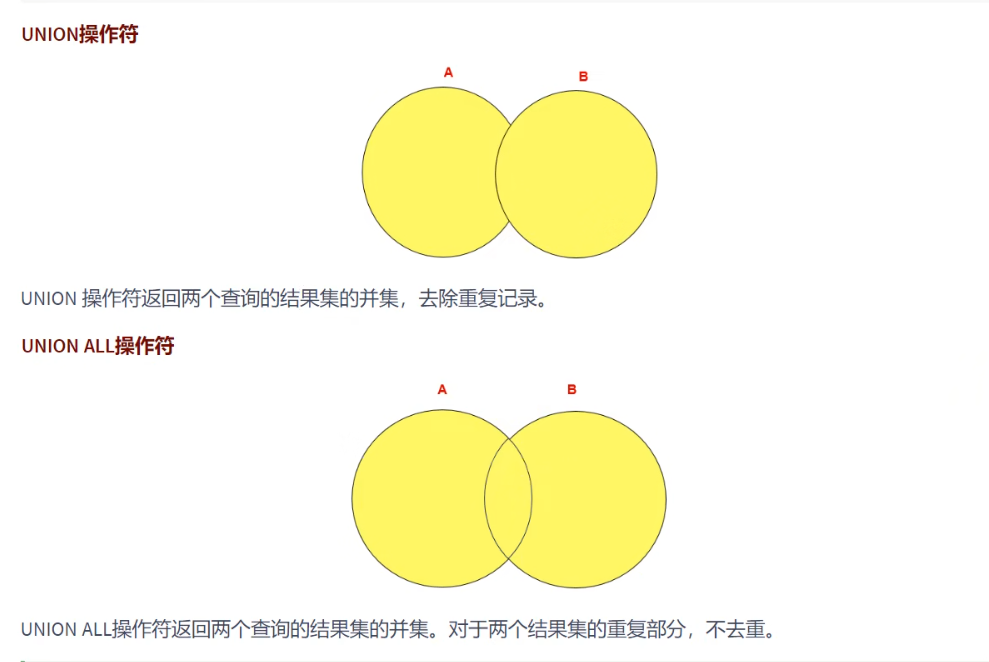
- UNION ALL 操作符返回两个查询的结果集的并集时,对于结果集的重复部分 不去重。
- UNION ALL 不需要执行去重操作,执行时所需要的资源比 UNION 少;
- 如果明知道合并后的数据结果不存在重复数据,或者不需要去重,则可以使用 UNION ALL,以提高查询的效率。
- 使用 UNION ALL 需要注意,是否存在重复数据!
流程控制函数
IF
IF(value,value1,value2)
- 如果 value 值为 True,则返回 value1,否则返回 value2;
IF NULL
IF NULL(value1,value2)
- 如果 value1 为 NULL 则返回 value2,否则返回 value1;
CASE WHEN
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
WHEN 条件4 THEN 结果4
...
ELSE 结果n
END
- 相当于 python 的
if ... elif ... else ...
CASE expr
WHEN 常量值1 THEN 值1
WHEN 常量值2 THEN 值2
WHEN 常量值3 THEN 值3
...
ELSE 值n
END
- 相当于 JAVA 的
swith ... case ...
聚合函数
AVG / SUM
MAX / MIN
COUNT
- COUNT 执行时不会计算 NULL;
- InnoDB 引擎下,COUNT(*) = COUNT(1) > COUNT(字段);
- MyISAM 引擎下,COUNT(*) = COUNT(1) = COUNT(字段);
GROUP BY
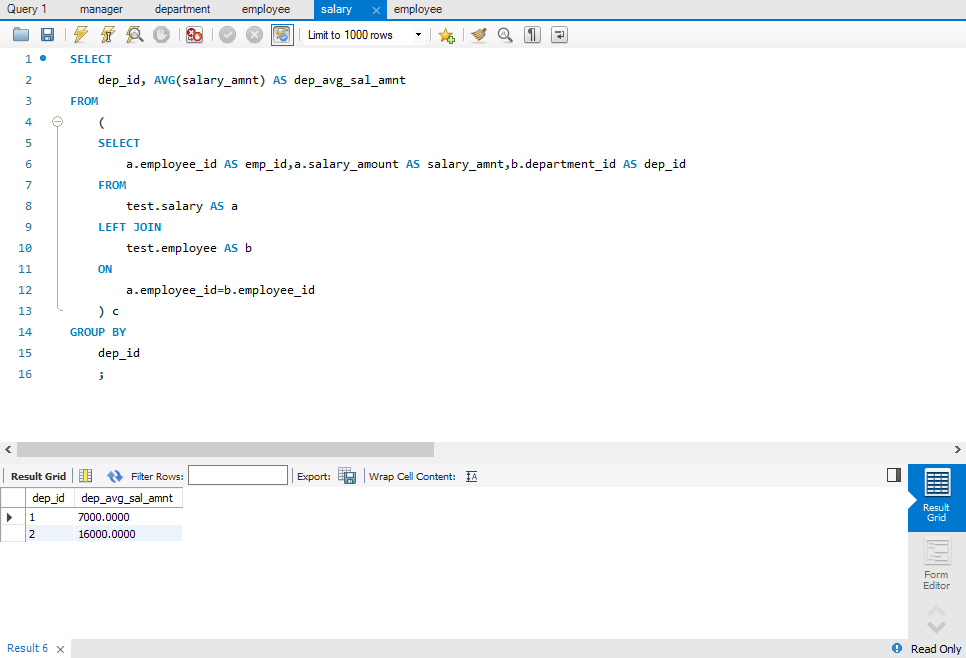
- 使用单个列分组:
SELECT dep_id, AVG(salary_amnt) AS dep_avg_sal_amnt FROM ( SELECT a.employee_id AS emp_id,a.salary_amount AS salary_amnt,b.department_id AS dep_id FROM test.salary AS a LEFT JOIN test.employee AS b ON a.employee_id=b.employee_id ) c GROUP BY dep_id ;
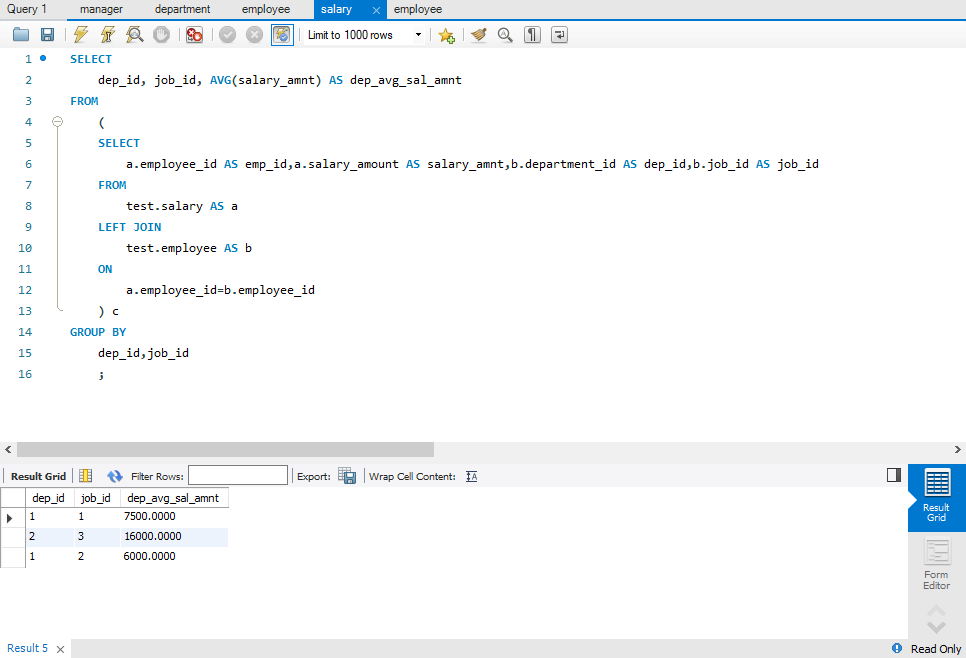
- 使用多个列分组:
SELECT
dep_id, job_id, AVG(salary_amnt) AS dep_avg_sal_amnt
FROM
(
SELECT
a.employee_id AS emp_id,a.salary_amount AS salary_amnt,b.department_id AS dep_id,b.job_id AS job_id
FROM
test.salary AS a
LEFT JOIN
test.employee AS b
ON
a.employee_id=b.employee_id
) c
GROUP BY
dep_id,job_id
;
HAVING
- 如果过滤条件中使用了聚合函数,则必须使用 HAVING 来替代;
- 如果过滤条件中没有使用聚合函数,则使用 WHERE 和 HAVING 都可以,但一般使用 WHERE,因为 WHERE 的执行效率更高;
- HAVING 必行声明在 GROUP BY 后面;
- 如果没有使用 GROUP BY,则没有必要使用 HAVING;
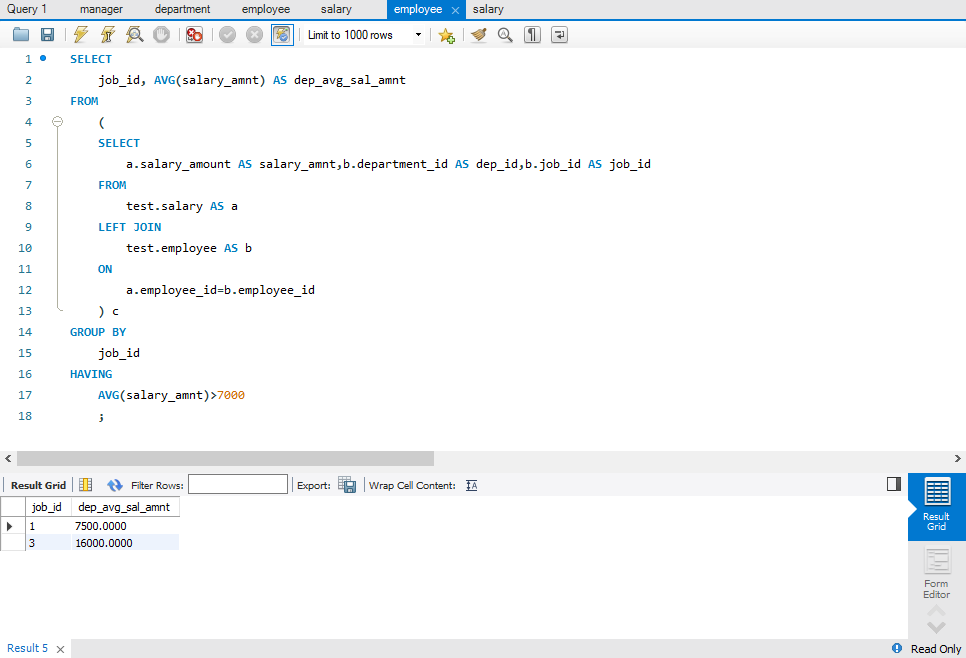
SELECT
job_id, AVG(salary_amnt) AS dep_avg_sal_amnt
FROM
(
SELECT
a.salary_amount AS salary_amnt,b.department_id AS dep_id,b.job_id AS job_id
FROM
test.salary AS a
LEFT JOIN
test.employee AS b
ON
a.employee_id=b.employee_id
) c
GROUP BY
job_id
HAVING
AVG(salary_amnt)>7000
;
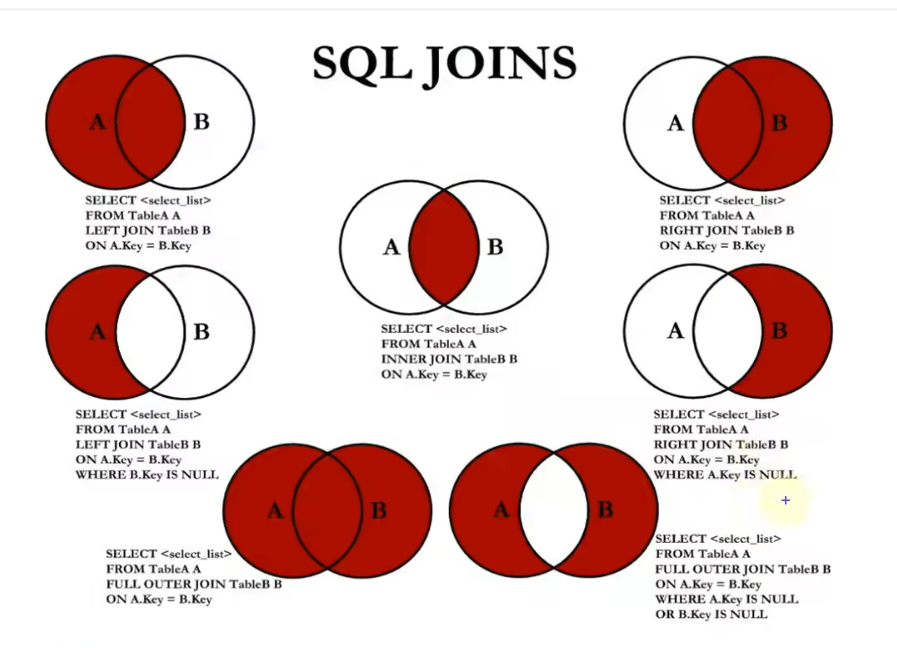
JOIN
创建表
- 需求:
- 需要根据 employee、attendance、calendar 三张表,统计员工的出勤情况;
-
创建日历表 calendar
CREATE TABLE calendar( id INTEGER NOT NULL PRIMARY KEY, -- 日历编号 calendar_date DATE NOT NULL UNIQUE, -- 日历日期 calendar_year INTEGER NOT NULL, -- 日历年 calendar_month INTEGER NOT NULL, -- 日历月 calendar_day INTEGER NOT NULL, -- 日历日 is_work_day VARCHAR(1) DEFAULT 'Y' NOT NULL -- 是否工作日 ); - 创建考勤记录表 attendance
CREATE TABLE attendance( id INTEGER NOT NULL PRIMARY KEY, -- 考勤记录编号 check_date DATE NOT NULL, -- 考勤日期 emp_id INTEGER NOT NULL, -- 员工编号 clock_in TIMESTAMP, -- 上班打卡时间 clock_out TIMESTAMP, -- 下班打卡时间 CONSTRAINT uk_attendance UNIQUE (check_date, emp_id) ); - 创建员工表 employee
CREATE TABLE `employee` ( `employee_id` int NOT NULL AUTO_INCREMENT, `employee_name` varchar(45) DEFAULT NULL, `department_id` int DEFAULT NULL, `job_id` int DEFAULT NULL, PRIMARY KEY (`employee_id`), UNIQUE KEY `employee_id_UNIQUE` (`employee_id`) ) ENGINE=InnoDB AUTO_INCREMENT=26 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
笛卡尔积(交叉连接)CROSS JOIN
- 交叉连接不带 WHERE 子句,它返回被连接的两个表所有数据行的笛卡尔积;
-
CROSS JOIN 返回结果集合中的数据行数,等于第一个表中的数据行数乘以第二个表中的数据行数;
- 应用实例:
- 如本文所示,在统计之前,需要将每个员工的 calendar 数据先行 JOIN,然后才能对比出勤情况,这里就会用到 CROSS JOIN;
SELECT c.*, e.* FROM calendar c CROSS JOIN employee e LIMIT 1000000;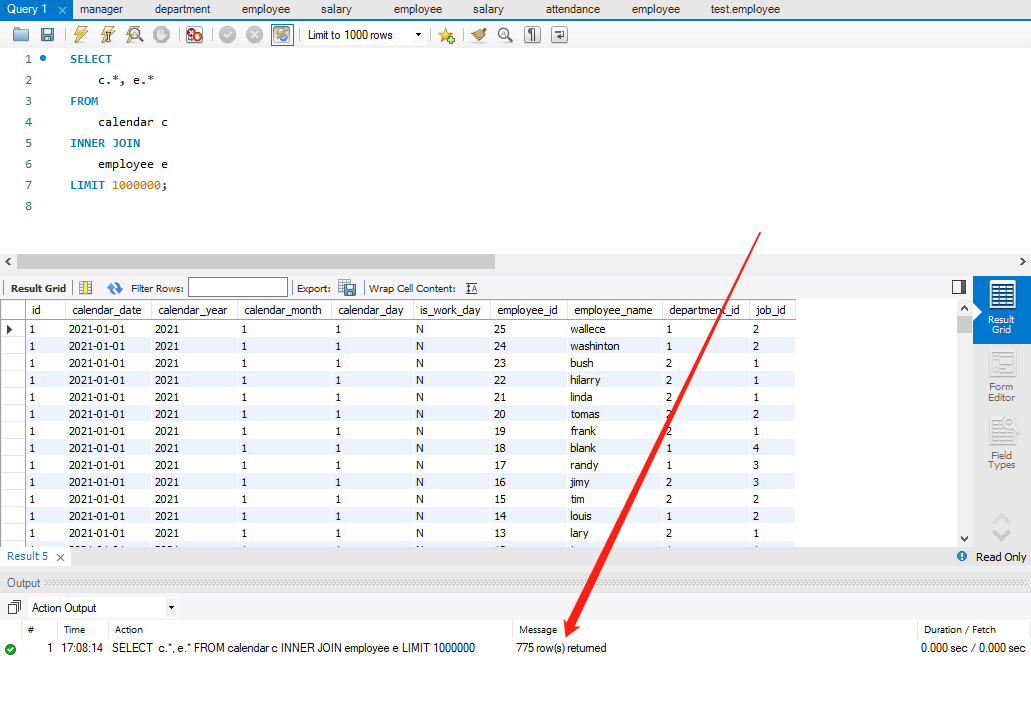
- 这个时候,CROSS JOIN 其实也可以写成如下样式:
SELECT * FROM calendar,employee LIMIT 1000000;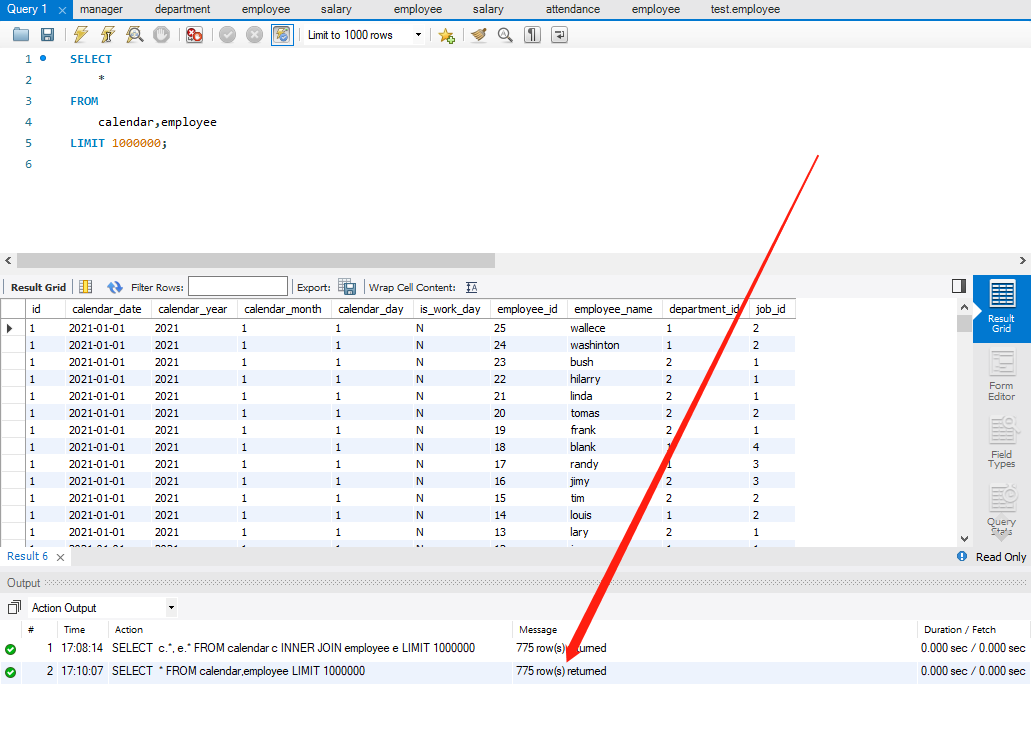
- 如本文所示,在统计之前,需要将每个员工的 calendar 数据先行 JOIN,然后才能对比出勤情况,这里就会用到 CROSS JOIN;
内连接 INNER JOIN … ON
- 主要指带 ON 的内连接,内连接按照 ON 条件合并两个表,返回满足条件的记录;
- 应用实例:
-
在本文示例中,如果我们想查看全部员工的考勤记录,可以使用 INNER JOIN ON,得到全部员工的考勤记录;
SELECT a.*, e.* FROM attendance a INNER JOIN employee e ON a.emp_id=e.employee_id LIMIT 1000000;
-
- INNER JOIN … ON vs 等值连接 WHERE
- 使用 where 和 = 将表连接起来的查询,其查询结果中列出被连接表中的所有列;
-
上面的例子,用如下 SQL 也可以获取同样的结果;
SELECT a.*, e.* FROM attendance a,employee e WHERE a.emp_id=e.employee_id LIMIT 1000000;
- 注意:
- 从逻辑上来说,等值连接与内连接没什么不同;
- 但实际上等值连接和内连接的执行计划并不相同,当参与连接的两个表比较大时,使用内连接(inner join)的效率更高。
LEFT JOIN ON
- 左外连接会保留左表的全部记录,相当于在左表的基础上加上右表中满足 ON 条件的数据;
-
剩余的空位以 NULL 填充;
-
示例:
SELECT a.*, e.* FROM employee e LEFT JOIN attendance a ON a.emp_id=e.employee_id LIMIT 1000000;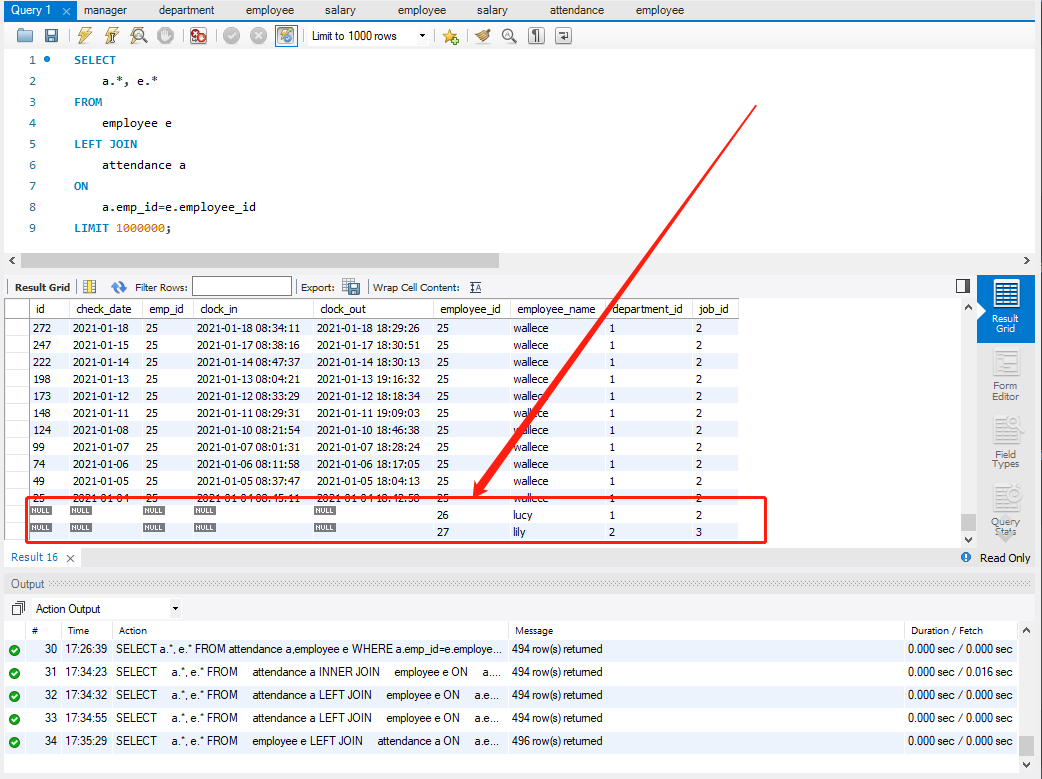
OUTER JOIN
- 左外连接会保留右表的全部记录,相当于在左表的基础上加上右表中满足 ON 条件的数据;
-
剩余的空位以 NULL 填充;
- 其情况与 LEFT JOIN 刚好相反,具体不再赘述。
常用经验
一旦给表起了别名,就必须使用这个别名、不能再使用原名。
SELECT
a.employee_name
FROM
employee AS a
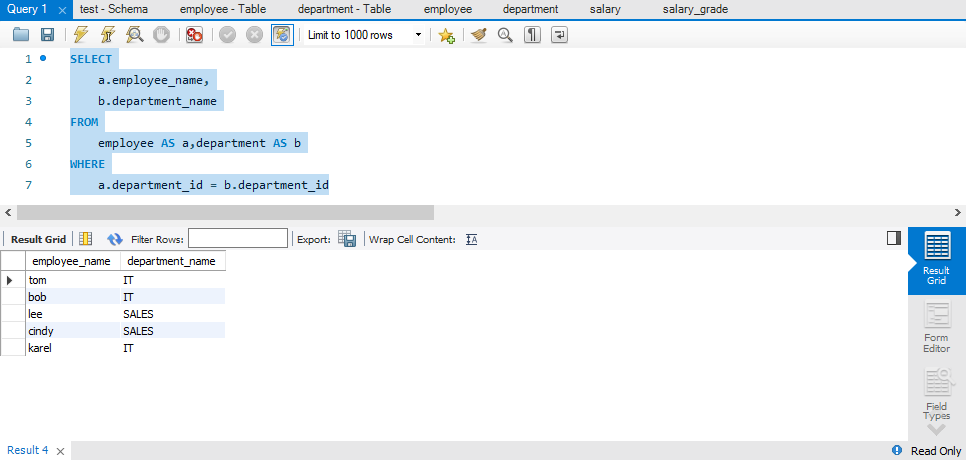
从 SQL 优化的角度考虑,多表查询时、每个字段前都应该指明字段所在的表;
SELECT
a.employee_name,
b.department_name
FROM
employee AS a,department AS b
WHERE
a.department_id = b.department_id