1. Hive 简介
- Hive 是一款建立在 Hadoop 之上的开源数据仓库系统,可以将存储在 Hadoop 文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似 SQL 的查询模型,称为 Hive 查询语言(HQL),用于访问和分析存储在 Hadoop 文件中的大型数据集。
1.1. Hive & Hadoop
Hive 利用 HDFS 存储数据,利用 MapReduce 计算引擎查询分析数据。
- Hive 核心是将 HQL 转换为 MapReduce 程序,然后将程序提交到 Hadoop 群集执行。
1.2. Hive & MapReduce
- 使用 Hadoop MapReduce 直接处理数据所面临的问题
- 人员学习成本太高 需要掌握 java 语言
- MapReduce 实现复杂,查询逻辑开发难度太大
- 使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写 MapReduce,减少开发人员的学习成本
- 支持自定义函数(UDF),功能扩展很方便
- 背靠 Hadoop,擅长存储分析海量数据集
- Hive 的最大的魅力在于用户专注于编写 HQL,Hive 将 HQL 转换成为 MapReduce 程序完成对数据的分析。
1.3. Hive 优点
- 操作接口采用类 SQL 语法,避免了写 MapReduce 程序,简单易上手,减少开发人员学习成本;
- 在数据处理方面,Hive 语句最终会生成 MapReduce 任务去计算,常用于离线数据分析,对数据实时性要求不高的场景;
- 在数据存储方面,能够存储很大的数据集(HDFS),并且对数据完整性、格式要求并不严格(要求是结构化的就可以了);
- 在延展性方面,Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数;
1.4. Hive 缺点
- Hive 的 HQL 本身表达能力有限,不能够进行迭代式计算,在数据挖掘方面也不擅长(当需求逻辑特别复杂时还需要借助于 Map Reduce)
- Hive 操作默认基于 MapReduce 引擎,延迟高、不适用于交互式查询,因此智能化程度低,并且基于 SQL 调优困难、粒度较粗。
- 我们也可以手动更改让 Hive 基于 Spark 引擎。
2. Hive 工作原理
2.1. Hive 工作流程
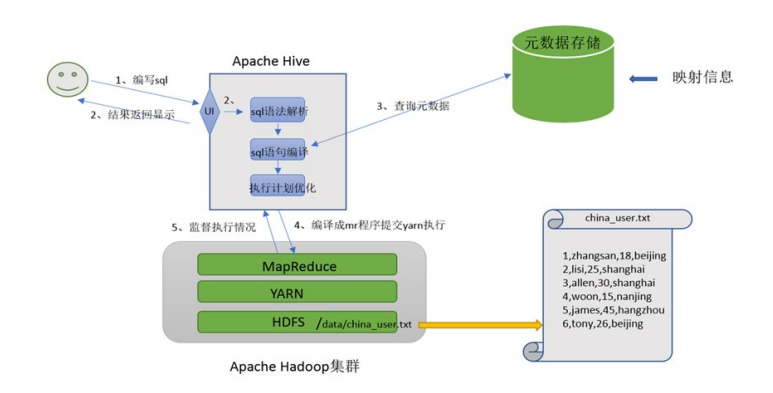
2.2. Hive 将数据文件映射成为一张表
- 在 hive中 能够写 sql 处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚;
- 映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据 metadata)。
- 元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
2.2. Hive 解析 SQL 编译称为 MapReduce
- 用户写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息解读sql背后的含义,制定执行计划。
- 并且把执行计划转换成 MapReduce 程序来具体执行,把执行的结果封装返回给用户。
3. Hive 架构
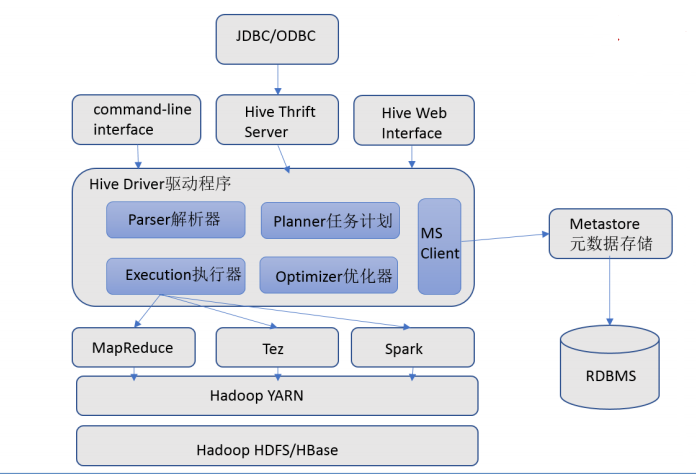
3.1. 用户接口
- 包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许;
- 外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
3.2. 元数据存储 Hive Metadata
- Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Hive Metadata 即 Hive 的元数据,包含用 Hive 创建的 database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如 hive 内置的 Derby、或者第三方如 MySQL 等。
3.4. Driver 驱动程序
- 包括语法解析器、计划编译器、优化器、执行器;
- Driver 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成;
- 生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
3.5. 执行引擎
- Hive 本身并不直接处理数据文件,而是通过执行引擎处理。
- 当下 Hive支持 MapReduce、Tez、Spark 3种执行引擎。
4. Metastore
4.1. Hive Metastore
- Metastore 即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
4.2. metastore 配置方式
- metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
- 区分3种配置方式的关键是弄清楚两个问题:
- Metastore服务是否需要单独配置、单独启动;
- Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
4.3. metastore 远程模式
- 在生产环境中,建议用远程模式来配置Hive Metastore。
- 在这种情况下,其他依赖 hive 的软件都可以通过 Metastore 访问 hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
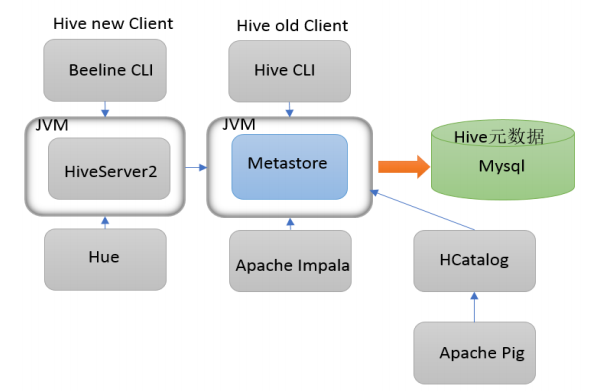
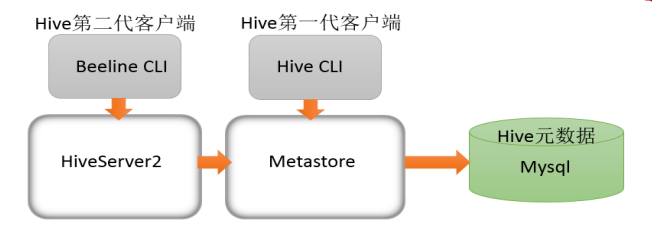
4.4. HiveServer2 服务
- 远程模式下 Hive 命令行工具 beeline 通过 Thrift 连接到单独的 HiveServer2 服务上,这也是官方推荐在生产环境中使用的模式。
-
HiveServer2 支持多客户端的并发和身份认证,旨在为开放 API 客户端如 JDBC、ODBC 提供更好的支持。
- HiveServer2 通过 Metastore 服务读写元数据,在远程模式下,启动 HiveServer2 之前必须先首先启动
metastore服务。
特别注意:远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问的。
- 具体关系如下:
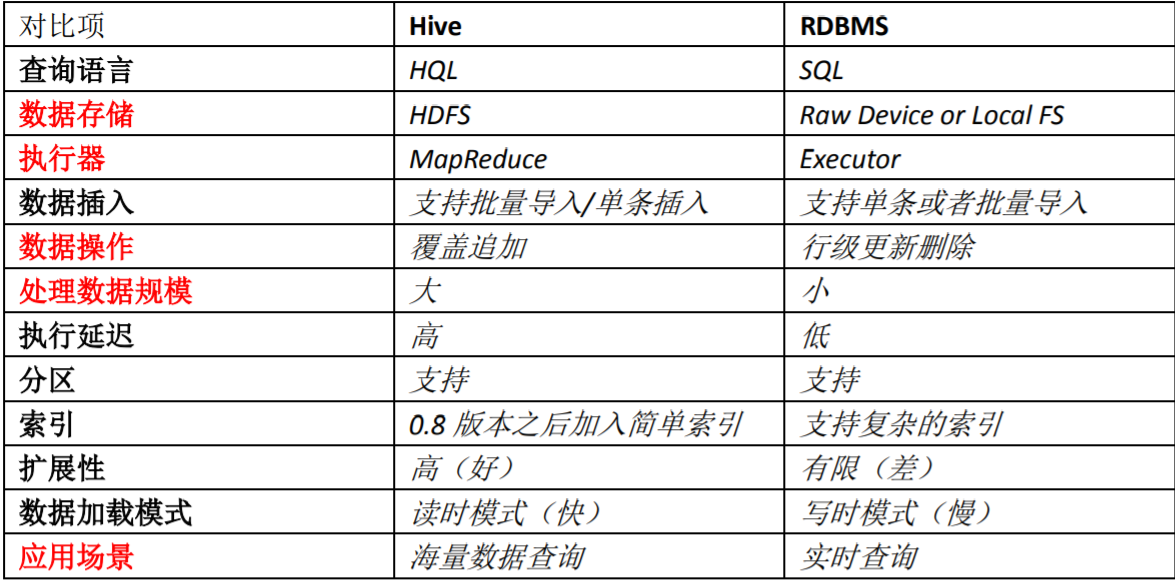
5. Hive 与 MySQL 的区别
- 查询语言不同
- hive 是 hql 语言,mysql 是 sql 语言;
- 数据存储位置不同
- hive 是把数据存储到 hdfs,而 mysql 数据存储在自己的系统中;
- 数据格式
- hive 数据格式可以用户自定义,mysql 有自己的系统定义格式;
- 数据更新
- hive 不支持数据更新,只可以读,不可以写,sql 支持数据的读写;
- 索引
- hive 没有索引,因此查询数据的时候是通过 mapreduce 很暴力的把数据都查询一遍,也造成了 hive 查询数据速度很慢的原因,而 mysql 有索引;
- 延迟性
- hive 没有索引,因此查询数据的时候通过 mapreduce 很暴力 的把数据都查询一遍,也造成了 hive 查询数据速度很慢的原因,而 mysql 有索引;
- 数据规模
- hive 存储的数据量超级大,而 mysql 只是存储一些少量的业务数据;
- 底层执行原理
- hive 底层是用的 mapreduce,而 mysql 是 excutor 执行器;
- 应用场景
- Hive 只适合用来做海量离线数 据统计分析,也就是数据仓库。