1. 大数据技术生态
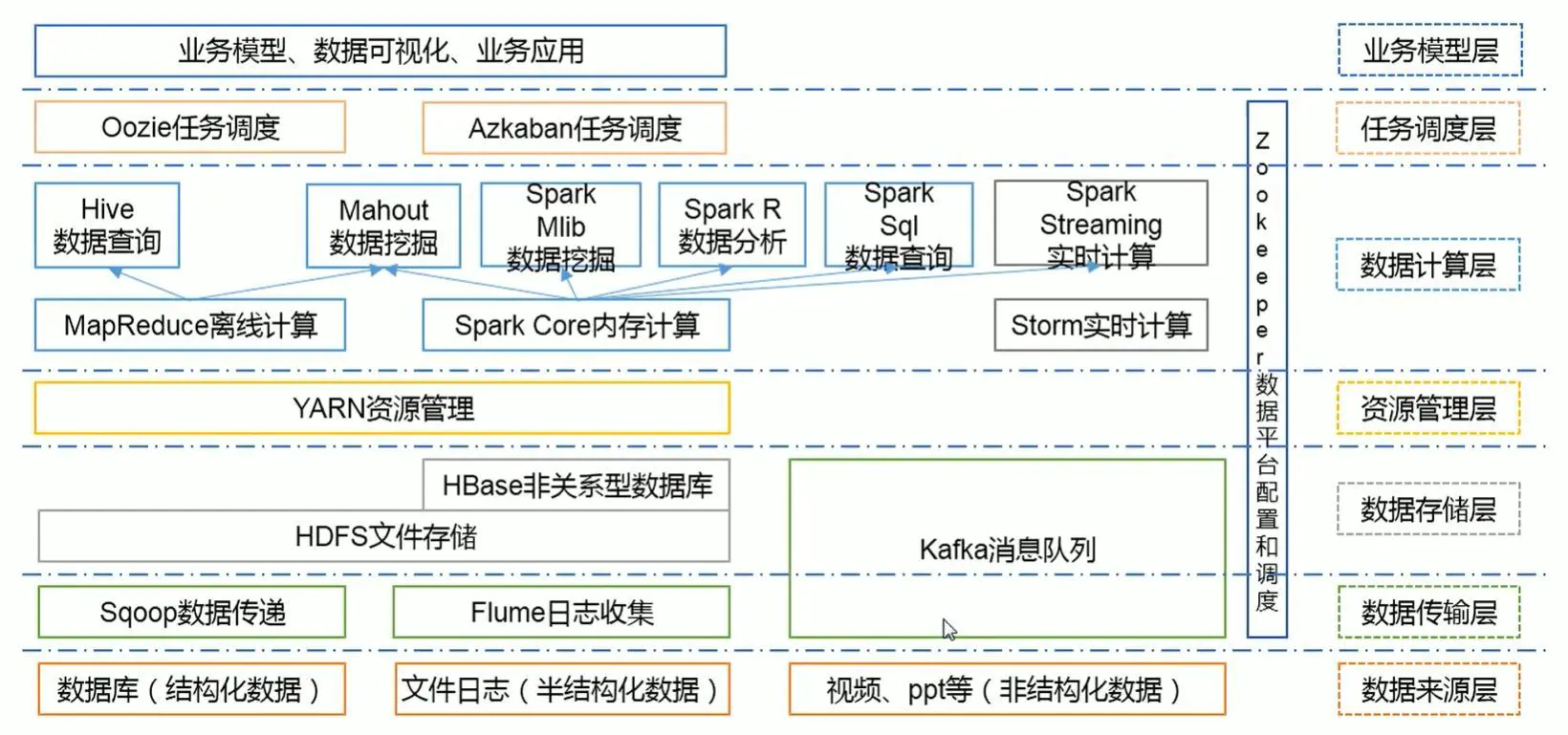
1.1. 大数据技术生态体系图
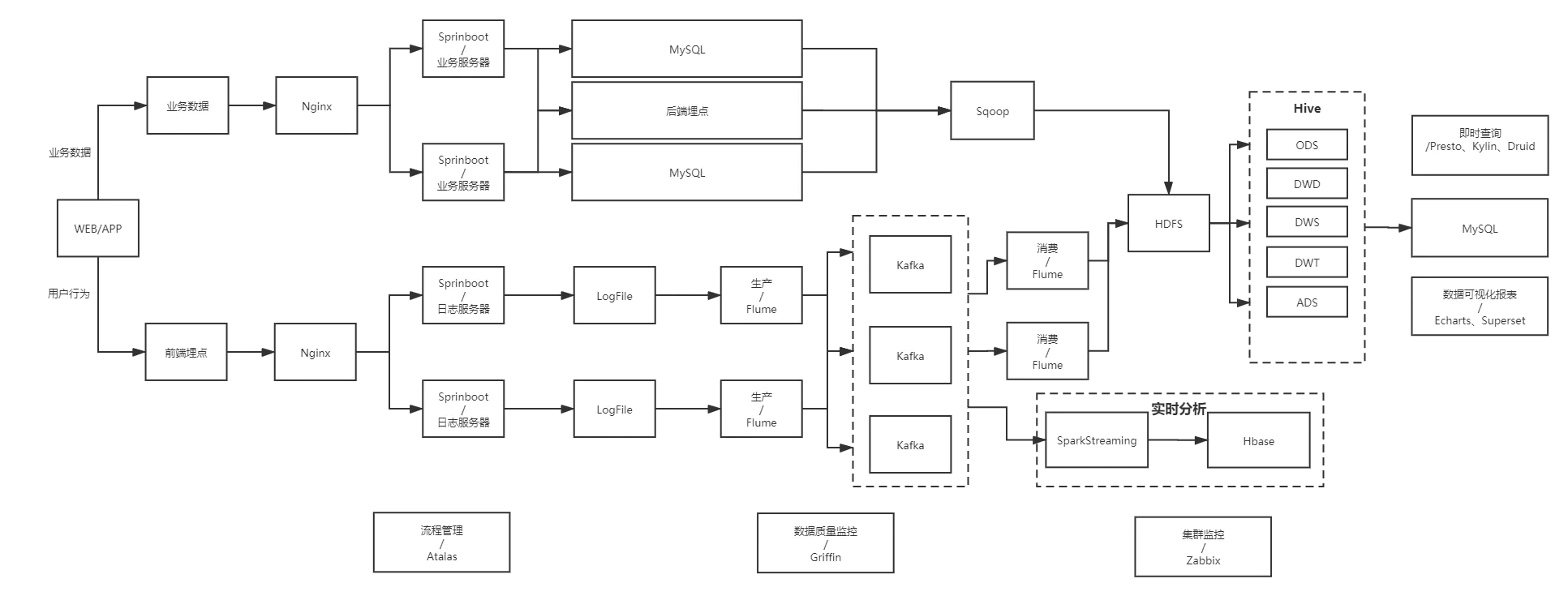
1.2. 数据流程图
1.3. 大数据框架
- Apache
- 使用最广泛的框架;
- 需要专业的运维人员;
- 组件兼容性需要仔细调研(Hive v2.3+);
- 尽量不要选新框架,容易出问题,最好选择最新框架半年前左右的稳定版本;
- Apache 常用版本对应情况
- JAVA: 1.8
- Hadoop: 3.1.3
- Hive: 3.1.2
- Flume: 1.9.0
- Zookeeper: 3.5.7
- Kafka: 2.4.1
- DataX: 3.0
- MaxWell: 1.29.2
- CDH
- 收费较贵;
1.4. 服务器
- 物理机
- 品牌:戴尔;
- 内存:128G;
- 内核:20 核 物理 CPU,40 线程(一般 1 核 CPU 对应 2 线程);
- 机械硬盘:8T HDD 机械硬盘;
- 固态硬盘:2T SSD 固态硬盘;
- 价格: 4W 左右;
- 寿命: 5 年左右;
- 云主机
- 阿里云、腾讯云,5W / 年;
需要根据 业务场景、集群规模 综合考虑。
1.5. 数据存储
- MySQL
- 存储业务数据;
- 存储数据分析的结果数据;
- HDFS
- 与 Hive 配套,存储海量数据;
- HBase
- 存储快速查表数据;
- Redis
- 缓存;
- MongoDB
- 爬虫数据存储;
1.6. 数据采集传输
- 用户行为数据:
- Flume,读取日志文件;
- Kafka,削峰;
- Logstash,Flume 替代品,专门处理日志(ELK);
- 业务数据(处理 MySQL):
- Sqoop,老外写的,轻量简洁,但功能单一,基本被替代了;
- DataX,Sqoop 的替代品,阿里出品的处理 MySQL 的工具,拥有很多插件,功能强大;
- MaxWell,实时监控 MySQL binlog,一旦发现 MySQL 有增删改查操作立刻同步到 Kafka;
- Canal,阿里开发的工具,功能与 MaxWell 类似。
1.7. 数据计算
- 实时计算:处理非实时问题,比如用于统计日活、周活、月活等;
- Hive(SQL):基于 MapReduce,做数据查询;
- Mahaout: 数据挖掘;
- Tez:基于内存,计算速度快;
- Spark Core:基于内存,计算速度快,掉电很麻烦;
- Spark Mlib:数据挖掘
- Spark R:数据分析
- Spark SQL:数据查询
- 实时计算:处理实时数据,比如天猫双十一实时数据计算;
- Spark Streaming:准实时 计算,实际采用批处理;
- Flink:TODO
- Storm:实时计算,正在被抛弃;
- 数据处理
- 批处理,触发式单次执行,比如电商交易订单;
- 流处理,流式不间断执行,比如自动驾驶数据;
1.8. 数据查询
- Presto
- 快速查询
- 支持 Redis、Kafka、MySQL
- 与 Apache 框架配合使用,安装包使用较方便;
- Druid
- 实时处理、批处理、流处理
- Impala
- Presto 替代品,速度快叫 Presto 速度更快,但是多数据源支持范围较 Presto 更窄;
- 与 CDH 框架配合,CDH 默认集成 Impala;
- Apache 安装 Impala 极为困难
- Kylin
- 多维度数据处理;
1.9. 数据可视化
- Echarts
- 百度开发的平台,需要 JavaScript 支持;
- Superset
- 免费
- QuickBI
- TODO
- DataV
- TODO
1.10. 任务调度
- DolphinScheduler
- Azkaban
- Oozie
1.11. 集群监控
- Zabbix
1.12. 元数据管理
- Atlas
1.13. 数据质量监控
- Griffin
- Shell
- Python
1.14. 数据平台和配置
- ZooKeeper
- Yarn
2. 技术选型考虑因素
2.1. 数据量大小 \ 集群规模
- 万级 \ 十万级:MySQL;
- 百万级 \ 千万级:;
- 亿级 \ 十亿级 \ 百亿级:HDFS;
2.2. 数据类型
- 数据库(结构化数据)
- 文件日志(半结构化数据)
- 视频、文本、图片文件等(非结构化数据)
2.3. 业务需求
- 用户行为数据:日志文件;
- 业务数据:MySQL;
2.4. 行业内经验
- 同行业(竞争对手)参考;
2.5. 技术成熟度
- 尽可能使用较稳定版本的技术;
2.6. 开发维护成本
- 开发难度 & 维护难度,需要作出长远规划、做好动态平衡;
2.7. 预算
- 费用预算应结合业务实际需求,不盲目求新求大;
3. 集群规模参考值
3.1. 日数据量:
- 日活 100万,每人 100 条日志,共计 100万 X 100 = 1 亿条;
3.2. 日存储量:
- 每条日志 1K 大小,每天:1亿条 / 1024 / 1024 = 100G;
3.3. 半年不扩容:
- 100G/天 X 180天 = 18T;
3.4. 保存 3 副本:
- 18 t x 3 = 54T;
3.5. 预留 Buff:
- 预留 20% ~ 30% Buff = 54T / 0.7 = 77T;
3.6. 服务器需求
- 8T * 10 台标准服务器(20核 / 128G / 8T HDD / 2T SSD);
注意:此方案未考虑 数仓分层 和 数据压缩 !
4. 服务器规划注意事项
- ResourceManager 和 NameNode 不能放在同一台服务器;
- ResourceManager 需要做高可用;
- ZooKeeper,安装台数为 奇数,最少 3 台;
- Kafka,与 ZooKeeper 安装在一起,Kafka 与 ZooKeeper 有大量的数据通信;
- Flume,与 Kafka 安装在一起,Flume 采集完的数据需要快速写入 Kafka;
- 如果有专门的额日志服务器,一般单独部署 Flume 到日志服务器;