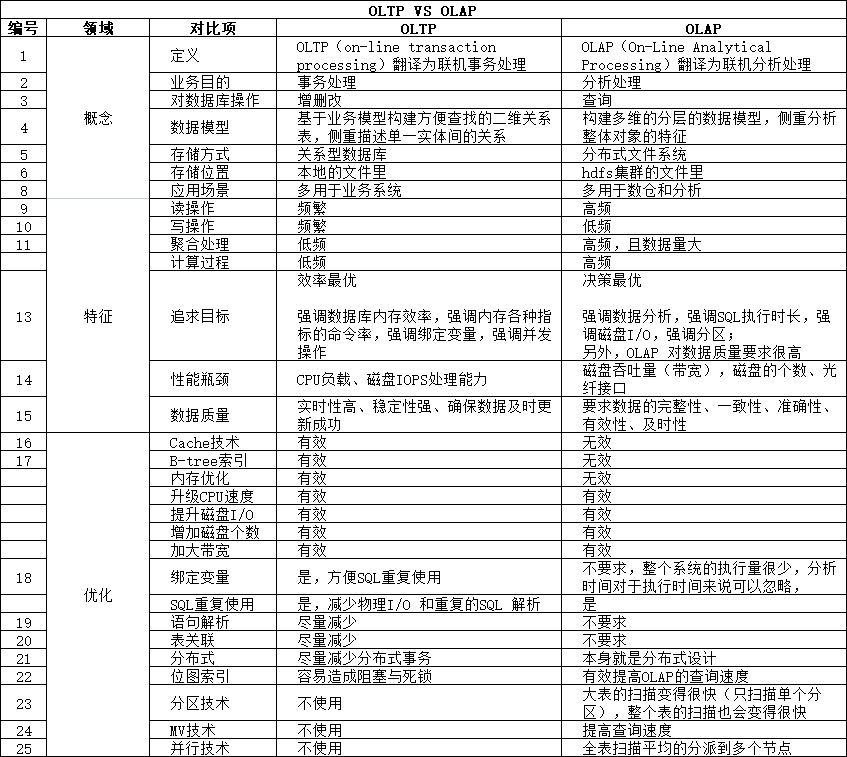
1. 概念
1.1. 定义
-
OLTP
OLTP(on-line transaction processing)翻译为联机事务处理;
-
OLAP
OLAP(On-Line Analytical Processing)翻译为联机分析处理。
1.2. 业务目的
-
OLTP
OLTP是做事务处理;
-
OLAP
OLAP是做分析处理。
1.3. 对数据库操作
-
OLTP
OLTP主要是对数据的增删改;
-
OLAP
OLAP是对数据的查询。
2. 存储模型
2.1. 数据模型
-
OLTP
OLTP 关系型数据库是基于业务模型构建方便查找的二维关系表,侧重描述单一实体间的关系;
-
OLAP
OLAP 构建多维的分层的数据模型,侧重分析整体对象的特征。
2.2. 存储方式
-
OLTP
OLTP 型数据库的典型代表是关系型数据库(mysql),它的数据存储在服务器本地的文件里;
-
OLAP
OLAP 型数据库的典型代表是分布式文件系统(hive),它的数据存储在hdfs集群的文件里。
2.3. 存储要求
关系型数据库中一行数据必须存在一个关系表中,是一个元组,分量必须要符合类型要求的,还通常有一个键来标记唯一性(行粒度索引,为了高效查找)。
分布文件系统中的数据存储的要求简单很多(数据分块,为了批量写入),一次写多次读取;数据要么数值、要么字符,就是我们常说的维度和指标。
3. 应用场景
3.1. OLTP 多用于业务系统
OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。
3.2. OLAP 多用于数仓和分析
当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。
因为OLTP所产生的业务数据分散在不同的业务系统中,而OLAP往往需要将不同的业务数据集中到一起进行统一综合的分析,这时候就需要根据业务分析需求做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。所以我们常说OLTP是数据库的应用,OLAP是数据仓库的应用,下面用一张图来简要对比。

3. 追求目标
3.1. OLTP 追求效率最优
OLTP 系统追求的效率最优解,强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作。OLTP 迫切要求数据在端到端的流通速度越快,耗时越短、则用户在更短的时间中达成交易并创造生产性的数据,同时也为企业创造出更大的单位时间价值。
OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
3.2. OLAP 追求决策最优
OLAP分析决策主要追求的决策最优解,决策的周期期一般都大于1天,对时间的效率要求并不高,对数据的质量要求很高。OLAP 系统则强调数据分析,强调SQL执行时长,强调磁盘I/O,强调分区等。
另外,OLAP 对数据质量要求很高,低质量的数据会产生低质量的业务认知,低质量的业务认知会产生低效或错误的决策,低效或错误的决策将给业务带来很大的损害。高质量的数据才能使决策者减少失误并得到符合预期的决策效果。
高质量的数据要求数据本身的体量要足够大足够表达业务,同时也要求数据的完整性、一致性、准确性、有效性、及时性。对大数据的清洗处理是一个本身就很耗时的ETL过程,压缩时间周期的成本很高也很难。基于OLAP的系统要求数据稳健的推动决策,重在数据质量。
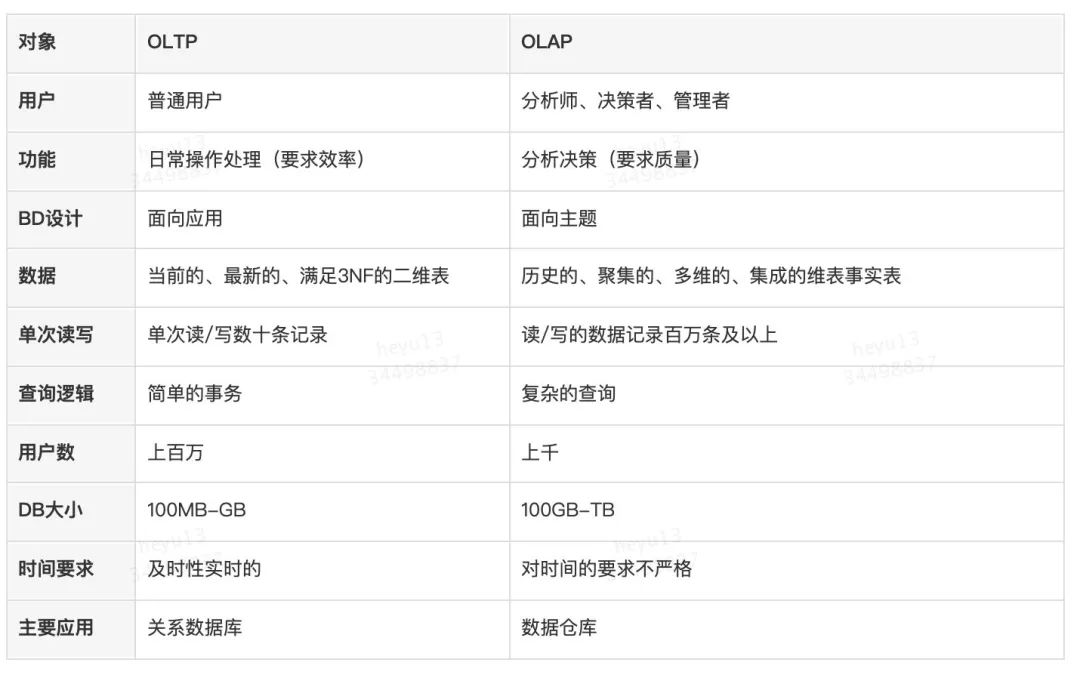
4. 优化策略
4.1. OLTP 优化策略
- 减少单个语句的逻辑读,或者是减少它们的执行次数;
- 尽量避免计算过程,建设计算型的函数,如自定义函数、decode等的频繁使用,
- 尽可能使用变量绑定技术来达到SQL 重用,减少物理I/O 和重复的SQL 解析;
在高可用的OLTP环境中,数据库使用越简单的功能越好。
4.2. OLAP 优化策略
- 增加CPU 处理速度;
- 提升磁盘I/O 速度;
- 增加磁盘的个数;
- 加大带宽;
- 分区技术;
- 并行技术;
- 使用位图索引;
- MV技术;
5. ROLAP & MOLAP
5.1. ROLAP
以ROLAP为代表的有传统关系型数据库、MPP分布式数据库以及基于Hadoop的Spark/Impala,特点是能同时连接明细数据和汇总数据,实时根据用户提出的需求对数据进行计算后返回给用户,所以用户使用相对比较灵活,可以随意选择维度组合来进行实时计算。
正因为采用的实时计算技术,所以ROLAP的缺点也比较明显——当计算的数据量达到一定级别或并发数达到一定级别的时候,一定会出现性能问题。
-
关系型数据库
传统关系型数据库为代表的如Teradata、Oracle等,由于传统架构可扩展性较差,所以对硬件的要求非常高,当计算的数据量达到千万,亿级别时,数据库的计算就会出现延时,使得用户不能及时得到响应,更别提高并发了。
-
MPP分布式数据库
MPP分布式数据库(GreenPlum/GBase/Vertica)则解决了一部分可扩展性问题,对硬件设备的要求也稍稍下降了(还是有一定的硬件要求),在支持的数据体量(GB,TB级别)上有了很大的提升。当集群有几百、上千节点时,会出现性能瓶颈(增加再多节点,性能提升也不会很明显),扩容成本同样不菲。
-
基于Hadoop的Spark/Impala
基于Hadoop的Spark/Impala,则对部署硬件的要求很低(常见服务器即可,只是其主要依靠内存计算来缩短响应时间,所以对内存要求较高),在节点扩容上成本上相对较低,但当计算量达到一定级别或并发达到一定级别后,无法秒级响应,且容易出现内存溢出等问题。
5.2. MOLAP
以MOLAP分析为代表的有Cognos,SSAS,Kylin等,设计理念是预先将客户的需求计算好以结果的形式存下来(比如一张表分为10个维度,5个度量,那客户提出的需求会有2的10次方种可能,然后将这么多种可能提前计算好存储下来)。
当客户提出需求后,找到对应结果返回即可,特点是当命中需求后返回非常快(所以MOLAP非常适合常见固定的分析场景),同等资源下支持的数据体量更大,支持的并发更多,不足则是当表的维度越多,越复杂,其所需的磁盘存储空间则越大,构建cube也需要一定的时间。
Apache Kylin 基于hadoop框架,Cube以分片的形式存储在不同节点上,Cube大小不受服务器配置限制,所以具备很好的可扩展性和对服务器要求很低,在扩容成本上就非常低廉。另外为了控制整体Cube的大小,Kylin给客户提供了建模的能力,即用户可以根据自身需要,对模型种的维度以及维度组合进行预先的构建,把一些不需要的维度和组合筛选掉,从而达到降低维度的目的,减少磁盘空间的占用。
6. 对比图