1. 数据湖的性能要求
1.1. 安全
- 数据集中存储,要求有严格的权限管控。
1.2. 可扩展
- 数据湖应随需求扩展的能力。
1.3. 吞吐量
- 较高的数据吞吐量。
1.4. 可靠性
- 必须稳定可靠。
1.5. 原始格式存储
- 数据必须是原始数据,不能有任何修饰、加工。
1.6. 支持多数据源、异构数据写入
- 不限制数据类型。
1.7. 支持多种处理和分析框架
- 支持的数据处理和分析架构应该是多样的。
2. 数据湖的设计原则
2.1. 数据和业务分离
- 数据湖的架构设计,不考虑业务,只考虑数据。
业务适配,是数仓应该考虑的,而不是数据湖。
2.2. 存储和计算分离(比较适合云平台)
- Hadoop 中计算的扩容受到存储制约:
- 一般来说,计算容量不够的时候,需要对计算进行扩容;
- Hadoop 中,计算和存储是一起的,DataNode 和 计算节点是复用的,这样计算节点可以直接访问本地的数据;
- 但是这样就会导致一个问题,计算扩容的时候、存储也跟着扩容,存储的 rebalance 会造成存储的资源消耗。
- 总结就是,计算的扩容收到存储制约,无法灵活的扩容和缩容。
- 存储和计算分离对网络要求很高:
- 存储和计算分离,数据是走网络的,这就对网络有很高的要求;
- 集群内网交换机的传输速度要很快才行,不然就会制约性能;
- 云平台天生支持存储和计算分离
- AWS 使用 S3 作为存储,计算是分离的;
- Azure 使用 blob 存储,计算和 blob 无关;
- 阿里云使用 OSS 存储,和计算也没有关系;
- 在云平台上,计算和存储天生就是分离的。
2.3. 支持多种数据处理架构
- lambda 架构;
- Kappa 架构;
- IOTA 架构;
2.4. 管理服务以及工具使用要求
- 数据安全管理;
- 访问权限管理;
- ETL 数据汇入;
- 合适的批处理、流处理工具;
- 前端工具,包括 BI、API 等;
3. Lambda 架构
3.1. Lambda 架构概念
- 分为离线处理和实时处理两种路径;
- 离线处理和实时处理,都会产生中间数据,离线结果根据执行间隔不停的执更新,实时结果不断的用新数据迭代;
- 离线数据和实时数据合并以后,抽取到数据库、缓存系统中,作为服务供用户查询;
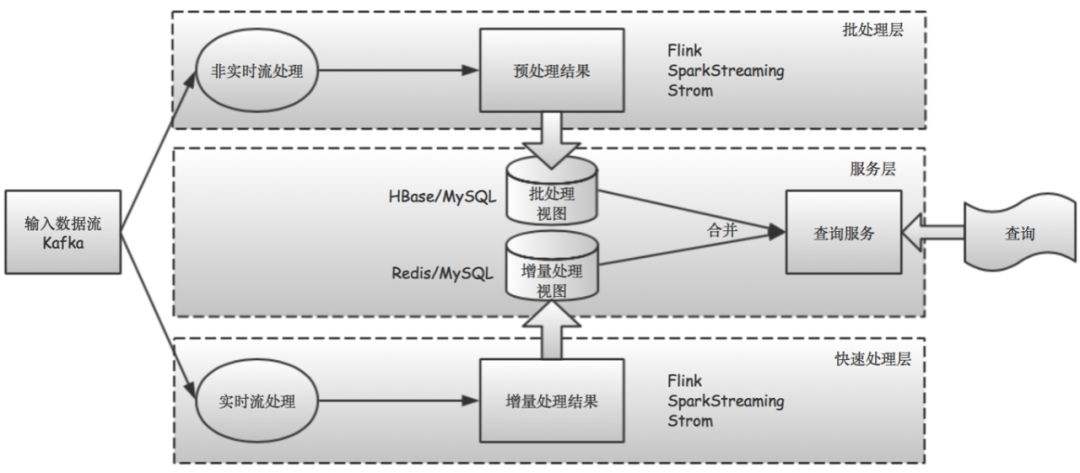
3.2. Batch Layer
- MR、Spark、SparkSQL 等计算引擎;
3.3. Speed Layer
- Storm、Flink、Spark Streaming;
3.4. Serving Layer
- MySQL、Redis、HBASE 等缓存数据库货缓存系统,将两个 view 的合并结果导入供查询;
3.5. Lambda 的优点
- 对于需要全量数据才能计算的结果,90% 的数据计算已经由离线完成,剩下的 10% 是实时计算结果,节省了计算的资源消耗、提升了计算响应速度;
- 实时计算部分成本可控;
- 批处理部分可以利用晚上等空闲时间进行,这样就会把实时计算和离线处理的高峰错开;
3.6. Lambda 的缺陷
- 实时和批处理结果不一致问题:
- 实际生产过程中,多种原因会导致实时处理和批处理时间对不上问题,导致衔接处出现数据遗漏或者数据重复,造成结果不准确;
时间对不上的原因包括:
todo
- 实际生产过程中,多种原因会导致实时处理和批处理时间对不上问题,导致衔接处出现数据遗漏或者数据重复,造成结果不准确;
- 批量计算无法在限定时间内处理完问题:
- 随着数据了越来越多,计算资源如果跟不上就会出现数据处理不完的问题;
- 系统维护问题:
- 实时处理和批处理是两套代码,维护起来会比较麻烦;
- 服务器存储开销大:
- 计算出来的中间数据用于支撑业务,会加大存储压力,不过这个情况渐渐不太重要了。