1. 企业对数据湖的需求
1.1. 过往的数据管理
- 数据库:数据的存储和查询;
- 数仓:数据的集中存储和分析;
- 消息队列:数据的转移通道;
- 流式计算:高效的数据加工和分析;
- 缓存系统:数据的快速加载。
1.2. 数仓主要解决数据孤岛问题
- 数据孤岛,不同业务、不同部门、不同来源、不同标准的数据,分散在各个地方;
- 数仓通过ETL、数据管道等,将分散的数据统一存储到数仓中,可以部分解决数据孤岛问题;
1.3. 数仓无法适应快速增长的非结构化数据分析需求
- 数据增长速度太快,导致数仓逐渐力不从心;
- 数仓建模是非常严格的,次开发数仓应用流程都很长,无法适应数据快速分析、快速处理的要求;
- 非结构化数据的价值越来越高,但是数仓并不适合分析非结构化数据;
- 数仓建模是非常严禁的,更适合处理结构化数据;
数仓的开发,是以需求为导向的,一旦设计好以后就不好在修改。
1.4. 企业需要保留海量的原始数据
- 过往企业存储数据,大都是存储的精简数据;
- 但是随着企业发展和技术进步,越来越多的企业需要存储海量的原始数据;
1.5. 企业需求的总结
- 数据的集中存储,成本可控、维护简单;
- 可以存储任意格式的数据(半结构化、非结构化);
- 能够支持大多数的分析框架;
2. 数据湖的概念理解
大数据技术的发展,是数据湖能够落地的前提下。
2.1. 数据湖包含的功能
- 大规模存储:
- 集中存储;
- 保留原始数据;
- 支持任意格式;
- 支持海量数据分析;
2.2. 数据湖的定义
一种支持任意格式数据、并能保留原始数据内容的、大规模数据存储系统架构,并且支持海量数据的分析处理。
2.3. 数据湖的特点
- 不限数据格式,均可流入;
- 集中存储,任意访问;
- 高性能分析能力;
- 存储原始数据;
3. 数据湖架构图
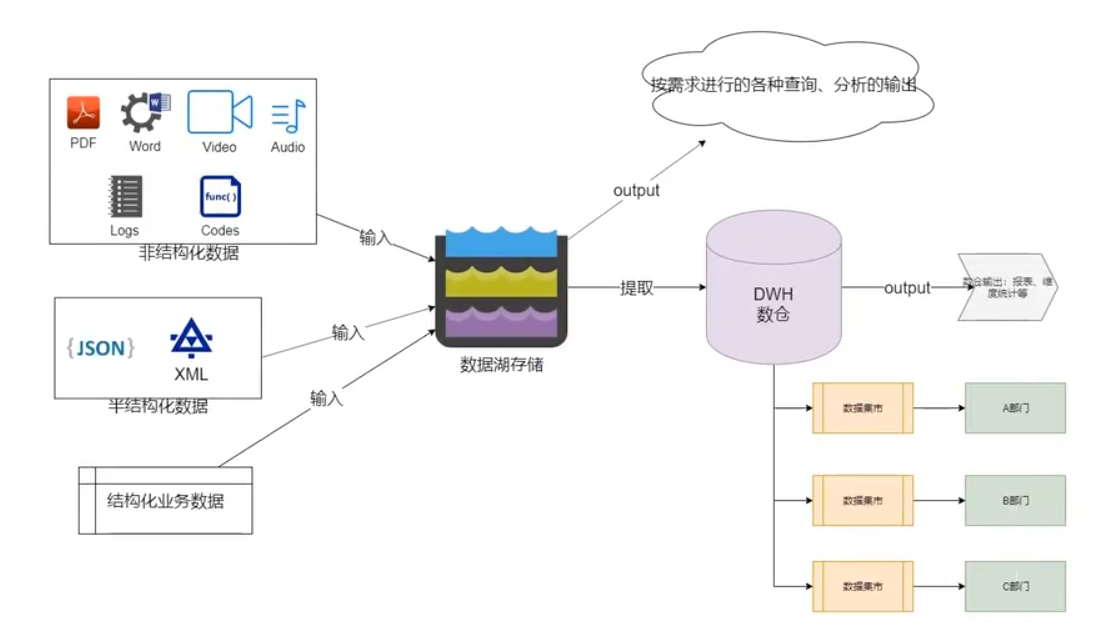
4. 写时模式 & 读时模式
5.1. 写时模式
- 数据在写入之前,就需要定义好 schema,按照 schema 定义写入;
- 数据库、数仓、数据集市,都是写时模式,需要先建表、再写入数据;
- 写时模式下,数据写入后修改 schema 成本是很高的。
4.2. 读时模式
- 数据在写入的时候,不要定义 schema,在需要的时候使用 schema 定义它;
- 读时模式下,数据模型定义很灵活;
- 同一套数据可以根据业务、使用不同的 schema,以满足不同的上层业务的高效分析需求;
5. 数据湖 VS 数仓 VS 数据集市
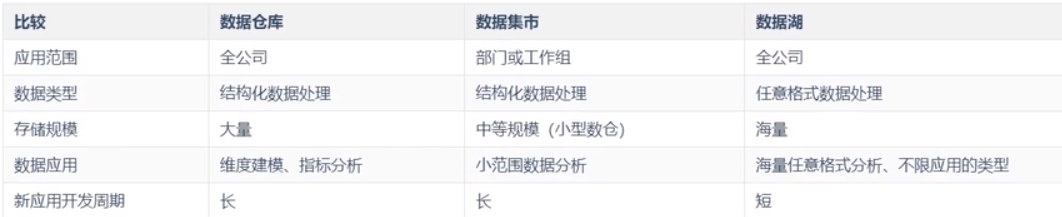
- 数据格式
- 数仓:结构化数据;
- 数据湖:任何格式数据均可。
- 模式区别
- 数仓:写时模式;
- 数据湖:读时模式;
- 典型例子如 SparksSQL。
- 使用思维
- 数仓:先有需求、再准备数据;
- 先有报表需求,然后设计 schema,之后 ETL 导入数据;
- 数据湖:先有数据,再按需利用;
- 数据先存储,需要的时候再设计 schema,再根据业务使用数据;
- 数仓:先有需求、再准备数据;
6. 数据湖的优势
6.1. 读时模式:可以更轻松的收集数据
- 不需要提前设计 schema;
- 对数据写入没有限制,数据收集很方便。
6.2. 异构存储:不需要关心数据结构
- 存储数据无限制;
- 任意格式都能存储。
6.3. 集中存储:集中存储方便任意访问
- 多个业务单元的人员,可以使用全部的数据;
- 省去了数据的聚合汇总。
6.4. 分析能力:能发现更多而数据价值
- 数仓:只能存储精简数据,而不是原始数据,这样会损失原始数据中的大量信息,只能回答定义好的问题,无法发掘更多数据价值。
- 数据湖:允许使用各种工具,对数据进行多样化、多维度的分析,从而容发掘更多的数据价值。
6.5. 更好的扩展性和开发敏捷性
- 数据湖使用分布式文件系统存储数据,具有很高的扩展能力;
- 开源技术降低了存储成本;
- 数据湖的数据结构不严格,具有很高的灵活性,从而有助于敏捷开发。
7. 数据湖的实施方案
数据湖是一种系统架构设计思想,既不是数据库、也不是技术框架。
7.1. 基于 Hadoop 的数据湖实施方案
- 常见的企业应用:
- 使用 HDFS 作为存储层,存储各类原始数据,包括架构华、非结构化、半结构化的数据;
- 使用 Spark、SparkSQL、MR 等计算框架作为分析引擎,对原始数据进行分析、抽取、计算、利用;
- 使用 Flume、Storm 等实时分析 HDFS 的数据;
7.2. 商业产品
- AWS S3
- Zaloni