1. 环境准备
1.1. 配置主机映射
-
设置服务器的映射关系,在三台服务器依次操作。
vi /etc/hosts172.xxx.xxx.xxx hadoop102 172.xxx.xxx.xxx hadoop104 172.xxx.xxx.xxx hadoop103
1.2. 配置免密登录
-
生成 ssh 秘钥并复制。
cd ~/.ssh/ ssh-keygen -t rsa ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
1.3. 创建文件分发脚本
-
分别在三台机器上安装 rsync
yum install rsync -
在 bin 目录下创建 xsync;
cd /bin vim xsync -
编辑脚本;
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=103; host<105; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done -
修改权限
chmod 777 xsync
1.4. 安装 JDK
- 上传文件
- 上传
jdk-8u162-linux-x64.tar.gz到 hadoop102 服务器/opt/software目录下;
- 上传
-
解压安装
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/module/ mv /opt/module/jdk1.8.0_162/ /usr/local/bin/jdk1.8 - 分发 jdk
xsync /usr/local/bin/jdk1.8/ - 添加环境变量
sudo vi /etc/profile # 在文件末尾添加 PATH 路径 export JAVA_HOME=/usr/local/bin/jdk1.8 export PATH=$PATH:$JAVA_HOME/bin - 分发
/etc/profilexsync /etc/profile - 在三台服务器上,依次启用环境变量
source /etc/profile - 检查 jdk
java -version
2. 安装 Hadoop
2.1. 安装
- 上传文件
- 上传文件
hadoop-3.1.3.tar.gz到 hadoop102 服务器/opt/software目录
- 上传文件
- 解压安装
tar -vxf hadoop-3.1.3.tar.gz -C /opt/module/ mv /opt/module/hadoop-3.1.3/ /usr/local/hadoop-3.1.3 - 分发 hadoop 文件
xsync /usr/local/hadoop-3.1.3/
2.2. 添加环境变量
- 添加环境变量
export HADOOP_HOME=/usr/local/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native - 分发
/etc/profilexsync /etc/profile - 在三台服务器上,依次启用环境变量
source /etc/profile - 检查安装情况
hadoop version - 查看 Hadoop 目录结构
cd $HADOOP_HOME ll drwxr-xr-x 2 root root 4096 May 8 22:04 bin drwxr-xr-x 3 root root 4096 May 8 22:04 etc drwxr-xr-x 2 root root 4096 May 8 22:04 include drwxr-xr-x 3 root root 4096 May 8 22:04 lib drwxr-xr-x 4 root root 4096 May 8 22:04 libexec -rw-r--r-- 1 root root 147145 May 8 22:04 LICENSE.txt -rw-r--r-- 1 root root 21867 May 8 22:04 NOTICE.txt -rw-r--r-- 1 root root 1366 May 8 22:04 README.txt drwxr-xr-x 3 root root 4096 May 8 22:04 sbin drwxr-xr-x 4 root root 4096 May 8 22:04 share
3. 配置 Hadoop 集群
3.1. 集群规划配置

3.2. 修改集群配置文件
- 注意:
- 一定要在
hadoop102上执行以下操作!
- 一定要在
-
进入配置文件目录
cd /usr/local/hadoop-3.1.3/etc/hadoop -
修改
core-site.xmlvi core-site.xml# 在 configuration 中添加 <property> <!--NameNode 主节点--> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <property> <!--临时文件目录--> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp</value> <description>Abase for other temporary directories.</description> </property> -
修改
hadoop-env.shvi hadoop-env.sh # 在 hadoop-env.sh 添加内容 export JAVA_HOME=/usr/local/bin/jdk1.8 -
修改
hdfs-site.xmlvi hdfs-site.xml<!-- 指定Hadoop辅助名称节点主机配置 --> <property> <!--副本数--> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property> <property> <!--SNN 节点位置--> <name>dfs.replication</name> <value>3</value> </property> <property> <!--NameNode 文件路径【默认】--> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value> </property> <property> <!--DataNode 文件路径【默认】--> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value> </property> <property> <!--HDFS 文件权限检查--> <name>dfs.permissions.enabled</name> <value>false</value> </property> -
修改
mapred-env.shvi mapred-env.sh export JAVA_HOME=/usr/local/bin/jdk1.8 -
修改
mapred-site.xmlvim mapred-site.xml<property> <!--运行时执行MapReduce框架工作。可以local[默认]、classic、yarn--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- MR 历史服务器(日志服务)--> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <property> <!--MR 日志服务 web 地址--> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> -
修改
yarn-env.shvi yarn-env.sh export JAVA_HOME=/usr/local/bin/jdk1.8 -
修改
yarn-site.xmlvim yarn-site.xml<property> <!--RM 服务器地址--> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <property> <!--YARN 容器允许管理的物理内存大小--> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <!--YARN 容器允许分配的最小物理内存--> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <!--YARN 容器允许分配的最大物理内存--> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <property> <!--关闭 YARN 对虚拟内存的限制检查--> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <!--关闭 YARN 对物理内存的限制检查--> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <!--任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1--> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> </property> <property> <!--Reduce 获取数据的方式--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <!--配置聚合日志--> <!--日志默认放在本地,配置此项放在 HDFS 上方便直接在 HDFS 上查看--> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <!--日志保留时间 second 7天~--> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <!--日志服务 web 地址--> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs/</value> </property> <property> <!--虚拟内存的限制是否会执行容器--> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> -
创建
slavesvi slaves hadoop102 hadoop103 hadoop104
3.3. 分发文件
-
使用 xsync 分发
xsync /usr/local/hadoop-3.1.3
3.4. 初始化
-
在 hadoop102 上执行初始化命令
hdfs namenode -format
3.5. 启动 HDFS
- 在 hadoop102 上启动 hdfs
start-dfs.sh - 在 hadoop102 上启动 yarn
start-yarn.sh - 检查启动情况
javapsall # 下面的提示标识启动成功 xcall jps -------hadoop102------ 13586 DataNode 13994 Jps 13933 JobHistoryServer 13455 NameNode -------hadoop102------ 13586 DataNode 14009 Jps 13933 JobHistoryServer 13455 NameNode -------hadoop103------ 5040 Jps 4703 NodeManager 4575 ResourceManager -------hadoop104------ 3408 SecondaryNameNode 3443 Jps
3.6. 群启群停
-
群启
start-all.sh -
群停
stop-all.sh
4. Web UI
4.1. 安全组设置
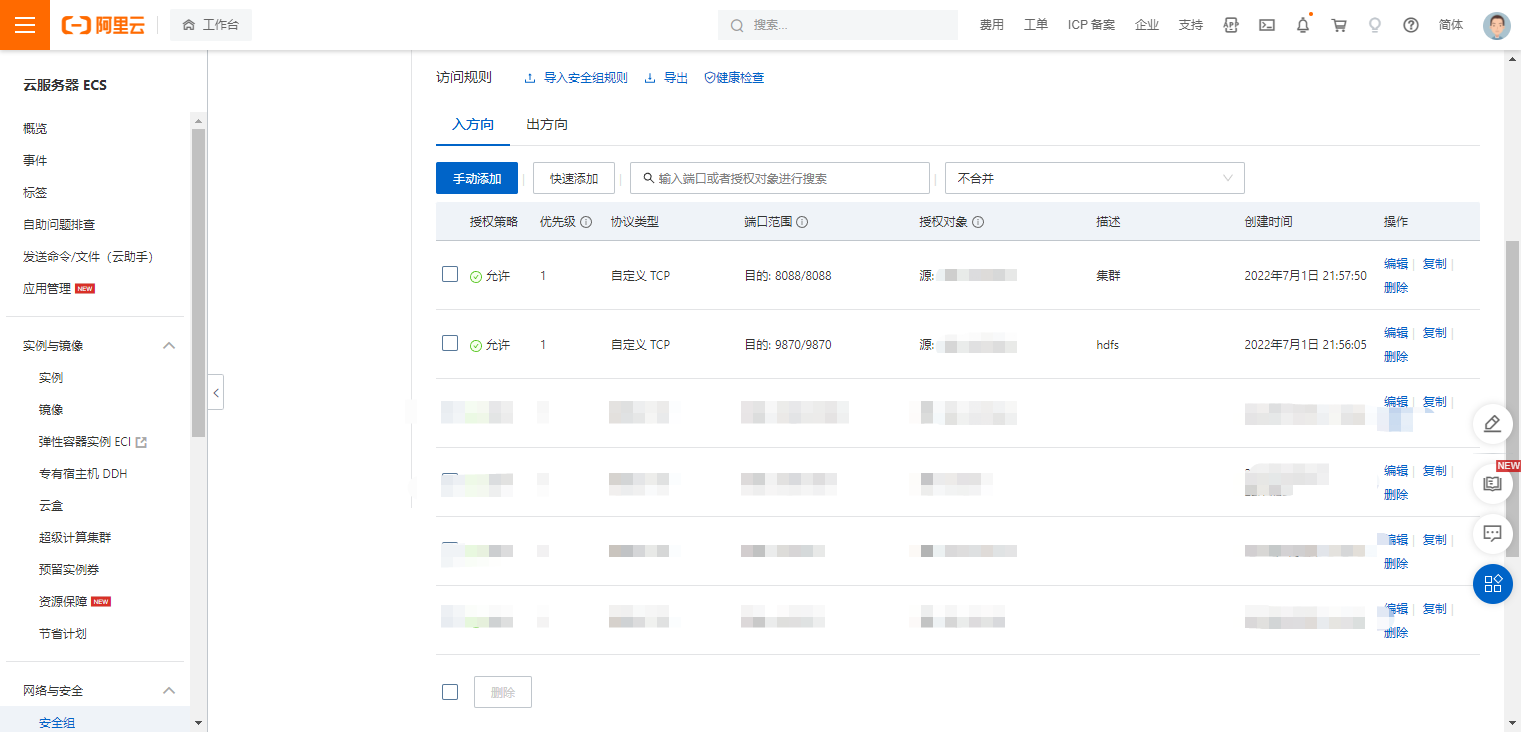
4.2. 访问地址
- hdfs
- http://mater节点IP:9870/
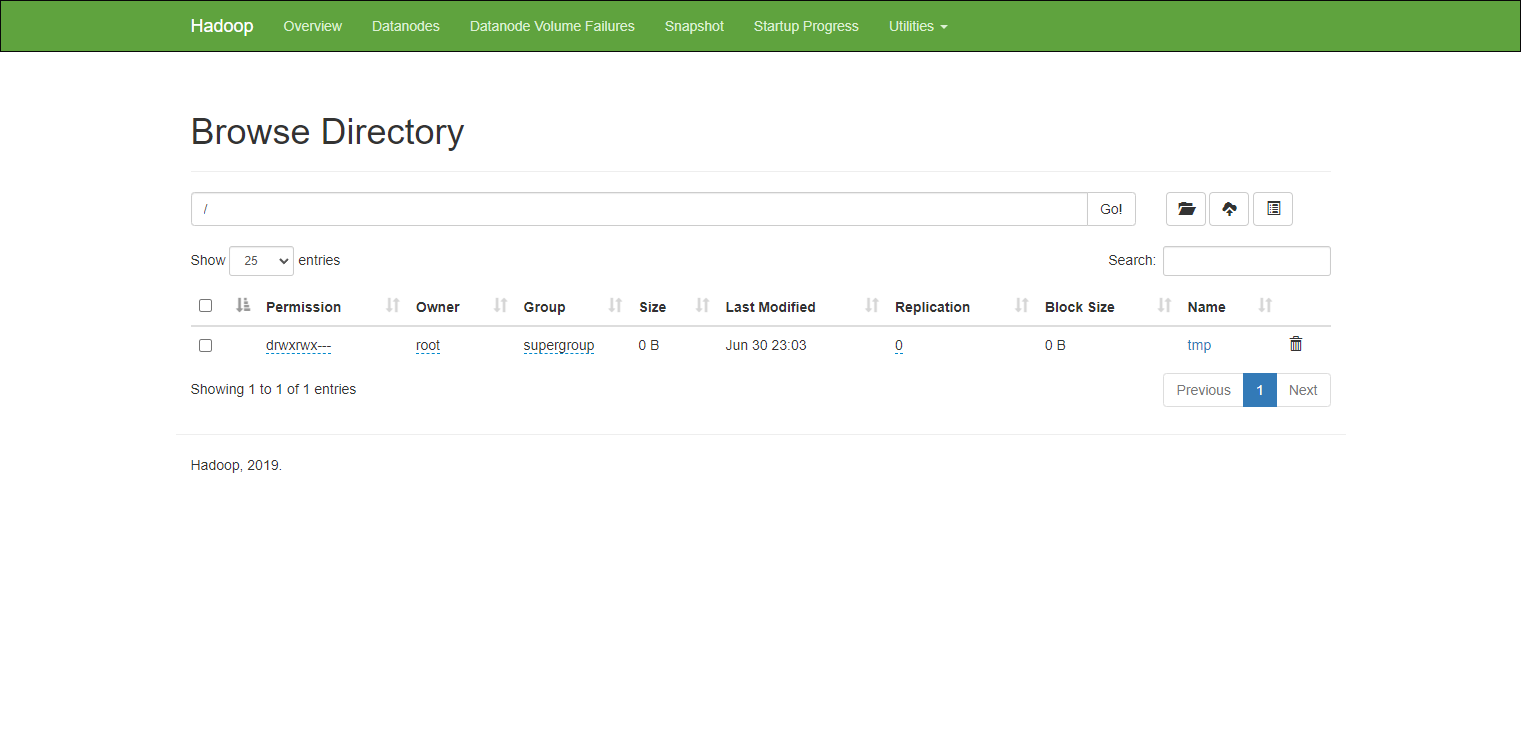
- http://mater节点IP:9870/
- yarn
- http://ResourceManager节点IP:8088/
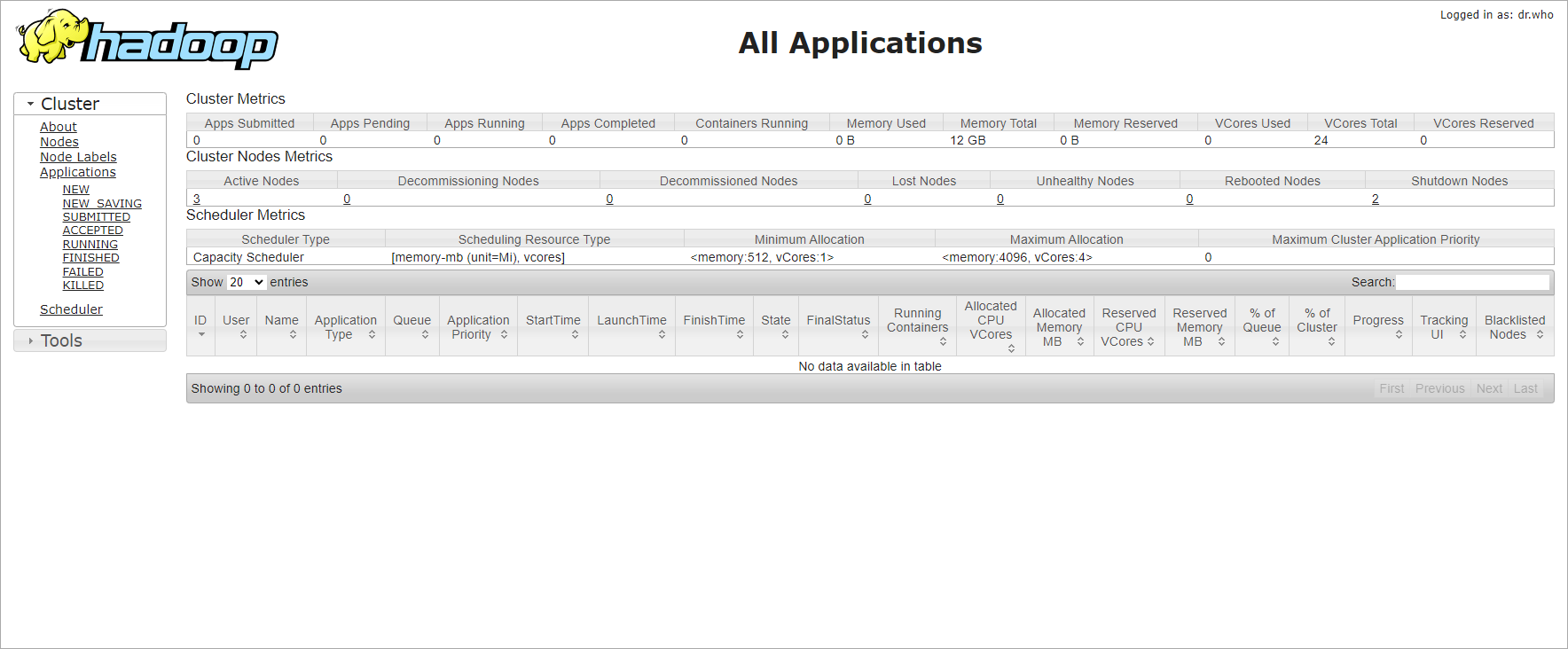
- http://ResourceManager节点IP:8088/