1. 集群配置
1.1. 获取 root 权限
su
# 输入密码
1.2. 修改主机名
- hadoop-1
hostnamectl set-hostname hadoop-1 - hadoop-2
hostnamectl set-hostname hadoop-2 - hadoop-3
hostnamectl set-hostname hadoop-3
1.3. 修改网卡配置
cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
PROXY_METHOD="nc"
BROWSER_ONLY="nc"
BOOTPROTO="static"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.254
DNS1=192.168.1.254 # 注意:这里不配置会导致虚拟机上不了网
# 启动生效
systemctl restart network
1.4. 主机名与IP映射
vi /etc/hosts
192.168.1.101 master
192.168.1.102 slave1
192.168.1.103 slave2
1.5. 配置SSH免密登录
此处只在 master 上配置免密登录 slave
#进入用户目录
cd /home/用户名
#生成密钥,回车即可
ssh-keygen -t rsa
#到.ssh目录下
cd /root/.ssh/
#将id_rsa.pub添加到authorized_keys目录
cp id_rsa.pub authorized_keys
ssh-copy-id -i slave1
ssh-copy-id -i slave2
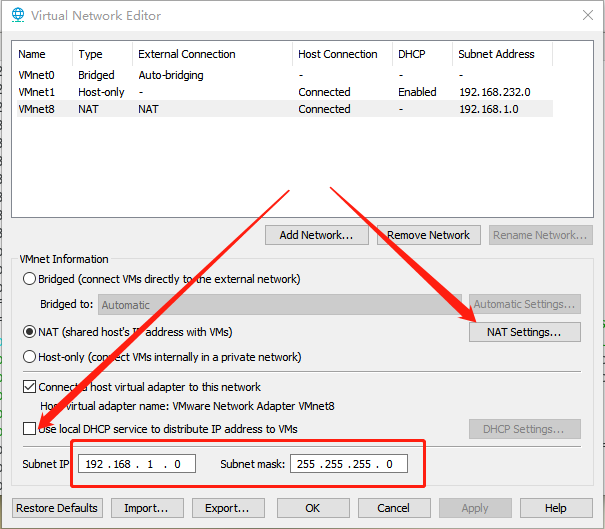
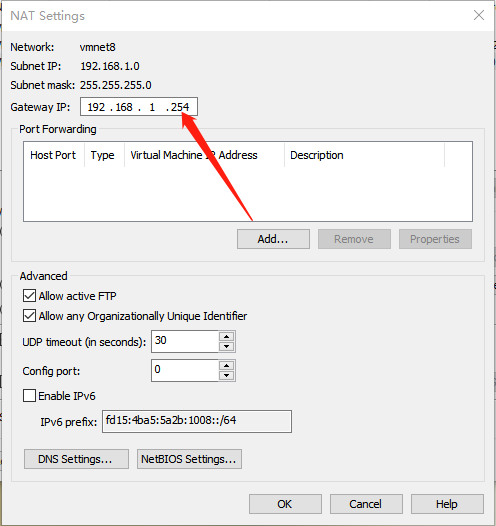
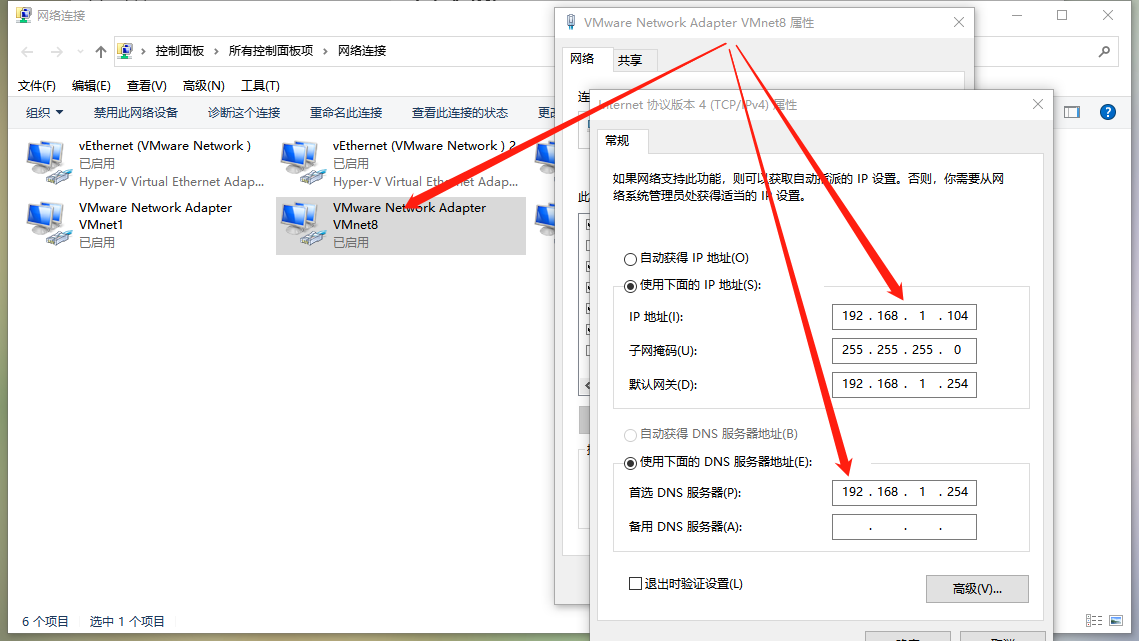
1.6. NAT配置
2. 安装 Hadoop
2.1. 配置 jdk
- 删除原生 java,注意 master 和 slave 机器都要删掉
- 查找jdk 安装位置
rpm -qa | grep java javapackages-tools-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 tzdata-java-2020a-1.el7.noarch java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 python-javapackages-3.4.1-11.el7.noarch java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 -
删除
rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps tzdata-java-2020a-1.el7.noarch rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch rpm -e --nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 - 检查有没有删除
java -version bash: java: command not found...
- 查找jdk 安装位置
-
在 home 目录下,解压缩 jdk-8u162-linux-x64.tar.gz 文件,并保存到
jdk1.8.0文件目录下。tar -zxvf jdk-8u162-linux-x64.tar.gz jdk1.8.0 - 配置环境变量
export JAVA_HOME=/home/用户名/jdk1.8.0 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin - 环境变量生效
source .bashrc - 检查安装情况
java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode) - 复制文件到子节点
scp -r /home/用户名/jdk1.8.0 用户名@slave1:/home/用户名/ scp -r /home/用户名/jdk1.8.0 用户名@slave2:/home/用户名/
2.2. 安装配置Hadoop
-
在 home 目录下,解压缩 Hadoop 压缩文件。
tar -zxvf hadoop-3.1.3.tar.gz -
配置环境变量
vim .bashrcexport HADOOP_HOME=/home/用户/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
2.3. 修改hadoop配置文件
- 修改 .bashrc 中的 YARN 和 HDFS 配置
vim .bashrcexport HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=rootcd hadoop-3.1.3/etc/hadoop/ -
修改 core-site.xml
vim core-site.xml# 在 configuration 中添加 <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/pandong/hadoop-3.1.3/tmp</value> <description>Abase for other temporary directories.</description> </property> - 修改 hadoop-env.sh
vim hadoop-env.sh# 在 hadoop-env.sh 添加内容 export JAVA_HOME=/home/用户名/jdk1.8.0 -
修改 hdfs-site.xml
vim hdfs-site.xml<property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/用户名/hadoop-3.1.3/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/用户名/hadoop-3.1.3/tmp/dfs/data</value> </property> -
修改 mapred-site.xml
vim mapred-site.xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> -
修改 yarn-site.xml
vim yarn-site.xml<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
workers
vim workersslave1 slave2
2.4. 复制文件到子节点
```aidl
scp -r /home/用户名/hadoop-3.1.3 用户名@slave1:/home/用户名/
scp -r /home/用户名/hadoop-3.1.3 用户名@slave2:/home/用户名/
```
```aidl
scp -r .bashrc 用户@slave1:/home/用户/
scp -r .bashrc 用户@slave2:/home/用户/
```
2.5. 格式化
-
关闭enforce
vi /etc/selinux/config -
切换 root 权限
su -
修改SELINUX
SELINUX=disabled -
退出 root,格式化
hdfs namenode -format
2.6. 启动hadoop
-
运行全部
start-all.shWARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER. Starting namenodes on [master] Last login: Mon Mar 7 08:10:16 PST 2022 on pts/0 Starting datanodes Last login: Mon Mar 7 08:10:36 PST 2022 on pts/0 Starting secondary namenodes [master] Last login: Mon Mar 7 08:10:39 PST 2022 on pts/0 2022-03-07 08:10:55,169 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting resourcemanager Last login: Mon Mar 7 08:10:46 PST 2022 on pts/0 Starting nodemanagers Last login: Mon Mar 7 08:10:57 PST 2022 on pts/0 -
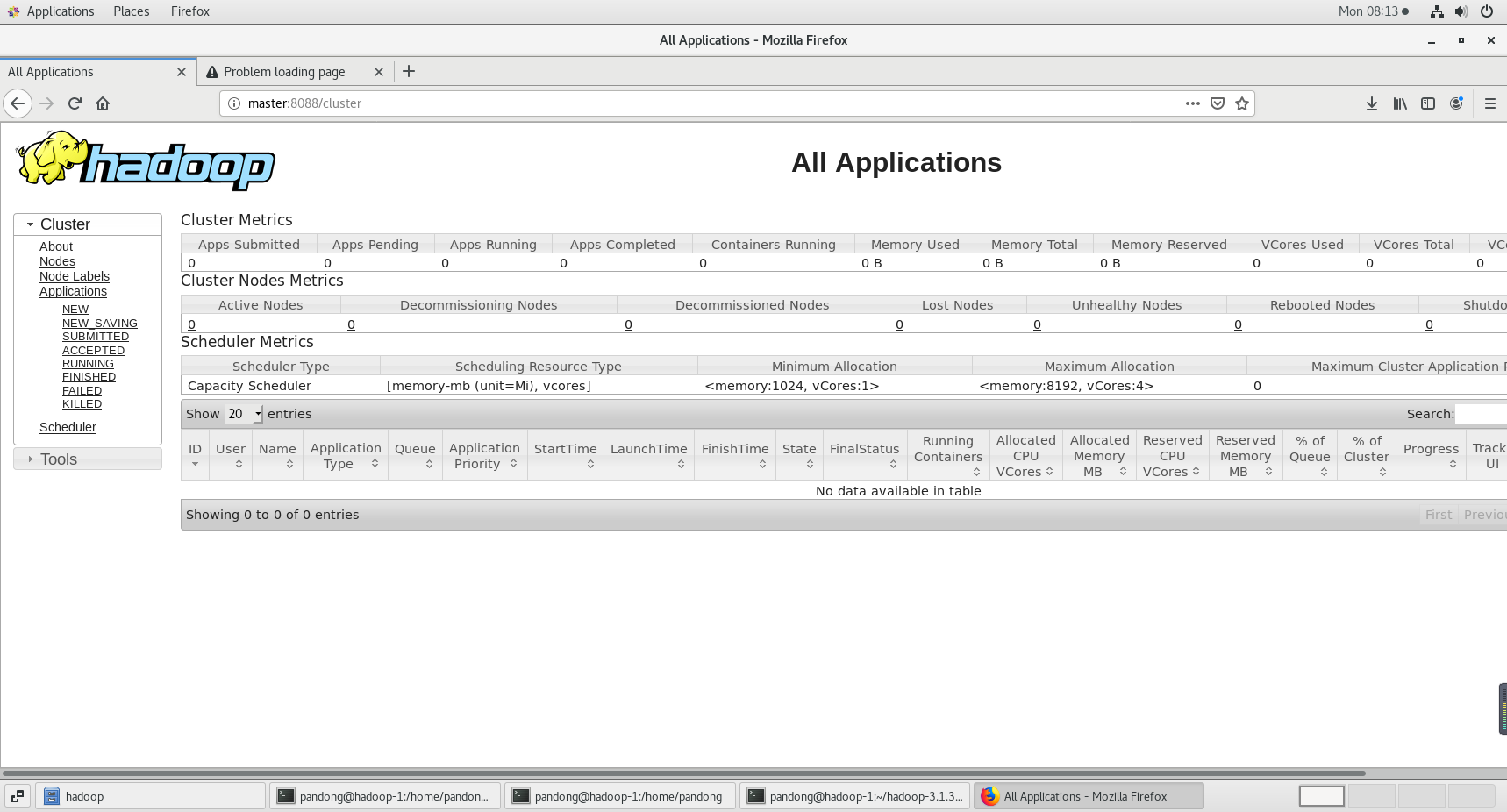
mapreduce:http://master:8088/cluster
-
NameNode and Datanode: http://master:9870
-
关闭全部
stop-all.sh