1. Hadoop 核心组件
- HDFS:解决海量存储;
- YARN:解决资源调度;
- MapReduce:解决海量数据计算。
Hadoop 集群 = HDFS 集群 + Yarn 集群
-
HDFS 集群 & Yarn 集群,物理上在一起,逻辑上相分离。
- 物理上在一起:程序部署在同一台机器上。
- 逻辑上相分离:两个集群之间没有依赖,互不影响。
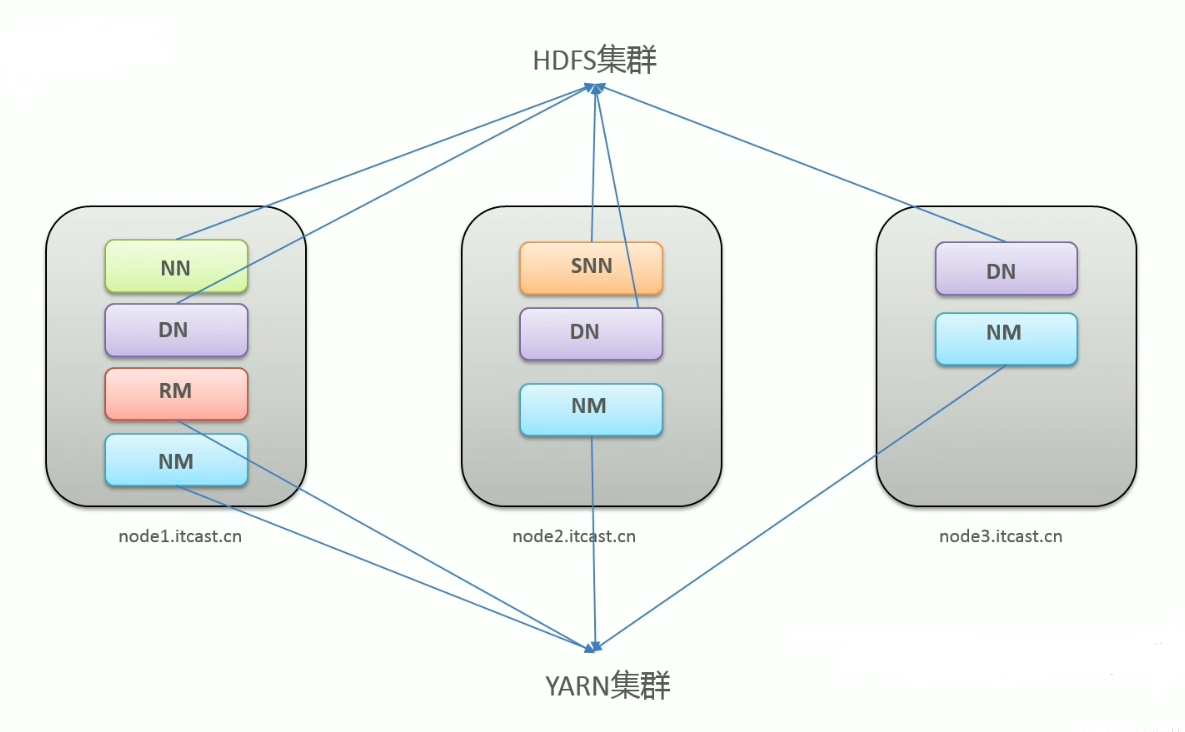
- MapReduce 是第一代计算引擎,是代码层面的组件,不存在集群之说。
没有 MapReduce 集群之说。
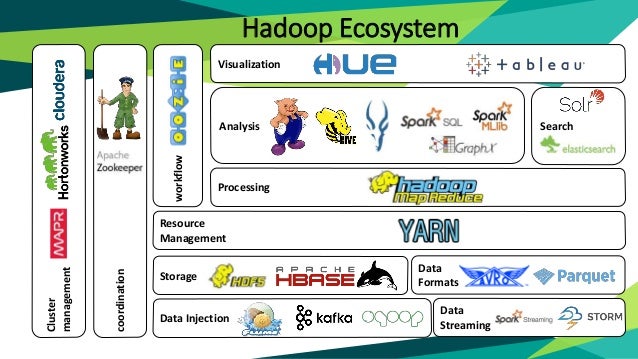
2. Hadoop 生态圈
3. Hadoop 特点
- 成本低廉:允许部署在廉价的通用机器上,不再要求单机性能
- 横向扩容:方便进行横向的扩容,集群方便扩展至上千节点
- 效率高:在集群内通过并行计算,大大提升计算效率
- 可靠性:副本机制(备份冗余)、重试机制、推测机制
- 通用性:与业务分离,各个行业都能很好的应用;
- 易用性:易学易懂、简单易用;
4. 版本变迁
- 1.x:MapReduce + HDFS
- 2.x:MapReduce + HDFS + Yarn
- 3.x:着重强调性能优化
- EC 纠删码
- 多 NameNode
- 任务本地优化
- 内存参数自动推断