Spark 简介
-
Spark 是一种通用、快速可扩展的大数据分析引擎;
-
Spark 解决了 MapReduce 读写磁盘速度过慢的问题;
-
Spark 框架下,不需要考虑数据倾斜问题,系统会自动优化;
- Spark 可以处理 MapReduce 离线批处理、Impala 交互式分析、Storm 流失处理、机器学习、图计算;
- 离线批处理:SparkCore
- 交互式分析:SparkSQL、SparkStreaming、StructuredStreaming
- 机器学习:MLlib
- 图计算:GraphX
- Saprk 可以计入的数据包括:
- HDFS
- JSON
- CSV
- Parquet
- RDBMS
- ES
- Redis
- Kafka
Spark 特点
快速
- Spark 是面向内存的大数据处理引擎,这使得 Spark 能够为多个不同数据源的数据,提供近乎实时的处理性能,适用于需要多次操作特定数据集的应用场景。
简洁易用
- Spark 不仅计算性能突出,在易用性方面也是其他同类产品难以比拟的。
- 一方面,Spark 支持 Scala、Java、Python、R 等多种语言,用户开发 Spark 程序十分方便;
- 另一方面,Spark是基于 Scala 语言开发的,由于 Scala 是一种面向对象的、函数式的静态编程语言,其强大的类型推断、模式匹配、隐式转换等功能、结合丰富的描述能力,使得 Spark 应用程序代码非常简洁。
- Spark 的易用性还体现在,其针对数据处理提供了丰富的操作。
- ,Spark提供了80多个针对数据处理的基本操作,如map、flatMap、reduceByKey、filter、cache、collect、textFile等,这使得用户基于Spark进行应用程序开发非常简洁高效。
-
此外,MapReduce自身并没有交互模式,需要借助Hive和Pig等附加模块。Spark则提供了一种命令行交互模式,即Spark Sheep,使得用户可以获取到查询和其他操作的即时反馈。
- 需要注意的是,在Spark的实际项目开发中多用Scala语言,约占70%;其次是Java,约占20%;而Python约占10%。通常使用方便、简洁的工具,其内部往往封装了更为复杂的机理,因此Scala与Java等语言比较起来,学习难度要大一些。
通用
- Spark 框架包含了多个紧密集成的组件,位于底层的 Spark Core 实现了 Spark 的作业调度、内存管理、容错、与存储系统交互等基本功能,并针对弹性分布式数据集提供了丰富的操作。
- 在 Spark Core 的基础上,Spark 提供了一系列面向不同应用需求的组件,主要有Spark SQL、Spark Streaming、MLlib、GraphX。
Spark软件栈
- Spark 核心组件以 jar 包的形式提供给用户,在使用这些组件无需进行复杂烦琐的学习、部署、维护和测试等一系列工作,用户只要搭建好Spark平台便可以直接使用这些组件,从而节省了大量的系统开发与运维成本。
- 将这些组件放在一起,就构成了一个Spark软件栈。基于这个软件栈,Spark提出并实现了大数据处理的一种理念——“一栈式解决方案(one stack to rule them all)”,即Spark可同时对大数据进行批处理、流式处理和交互式查询。借助于这一软件栈用户可以简单而低耗地把各种处理流程综合在一起,充分体现了Spark的通用性。
Spark SQL
- Spark SQL 是 Spark 用来操作结构化数据的组件。
- 通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 HQL 来查询数据。
- Spark SQL 支持多种数据源类型,例如 Hive表、Parquet 以及 JSON 等。
- Spark SQL 不仅为 Spark 提供了一个 SQL 接口,还支持开发者将 SQL 语句融入到 Spark 应用程序开发过程中,无论是使用 Python、Java 还是 Scala,用户可以在单个的应用中同时进行 SQL 查询和复杂的数据分析。
Spark Streaming
- 众多应用领域对实时数据的流式计算有着强烈的需求,例如网络环境中的网页服务器日志或是由用户提交的状态更新组成的消息队列等,这些都是实时数据流。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。由于这些 API 与 Spark Core 中的基本操作相对应,因此开发者在熟知 Spark 核心概念与编程方法之后,编写 Spark Streaming 应用程序会更加得心应手。
- 从底层设计来看,Spark Streaming 支持与 Spark Core 同级别的容错性、吞吐量以及可伸缩性。
MLlib
- MLlib 是 Spark 提供的一个机器学习算法库,其中包含了多种经典、常见的机器学习算法,主要有分类、回归、聚类、协同过滤等。
- MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化基础算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
GraphX
- GraphX 是 Spark 面向图计算提供的框架与算法库。
- GraphX 中提出了弹性分布式属性图的概念,并在此基础上实现了图视图与表视图的有机结合与统一;
- 同时,针对图数据处理提供了丰富的操作,例如取子图操作 subgraph、顶点属性操作 mapVertices、边属性操作mapEdges 等。
- GraphX 还实现了与 Pregel 的结合,可以直接使用一些常用图算法,如 PageRank、三角形计数等。
Spark 运行模式
- Spark 支持多种运行模式:本地local运行模式、分布式运行模式。
- local mode 下,最好设置 2 个 CPU Core,此时可以同时运行 2 个 Task 任务,相当于并行计算;
- 集群模式 cluster mode:
- 管理者:
- MR:AppMaster
- Spark:Driver Program
- Flink:JobManager
- 任务执行者:
- MR:Map Task、Reduce Task
- Spark:Executor
- Flink:TaskManager
- 管理者:
- Spark 集群的底层资源可以借助于外部的框架进行管理,目前 Spark 对 Mesos 和 Yarn 提供了相对稳定的支持。在实际生产环境中,中小规模的 Spark 集群通常可满足一般企业绝大多数的业务需求,而在搭建此类集群时推荐采用 Standalone 模式(不采用外部的资源管理框架),该模式使得 Spark 集群更加轻量级。
Spark on Yarn模式
在这一模式下,Spark作为一个提交程序的客户端将Spark任务提交到Yarn上,然后通过Yarn来调度和管理Spark任务执行过程中所需的资源。在搭建此模式的Spark集群过程中,需要先搭建Yarn集群,然后将Spark作为Hadoop中的一个组件纳入到Yarn的调度管理下,这样将更有利于系统资源的共享。
Spark on Mesoes模式
Spark和资源管理框架Mesos相结合的运行模式。Apache Mesos与Yarn类似,能够将CPU、内存、存储等资源从计算机的物理硬件中抽象地隔离出来,搭建了一个高容错、弹性配置的分布式系统。Mesos同样也采用Master/Slave架构,并支持粗粒度模式和细粒度模式两种调度模式。
Spark Standalone模式
该模式是不借助于第三方资源管理框架的完全分布式模式。Spark使用自己的Master进程对应用程序运行过程中所需的资源进行调度和管理。对于中小规模的Spark集群首选Standalone模式。
SparkCore:RDD 弹性分布式数据集
- Spark 处理数据时,将数据封装到 RDD 中,RDD 里会有很多 Partition 分区,每个分区数据被一个 Task 处理;
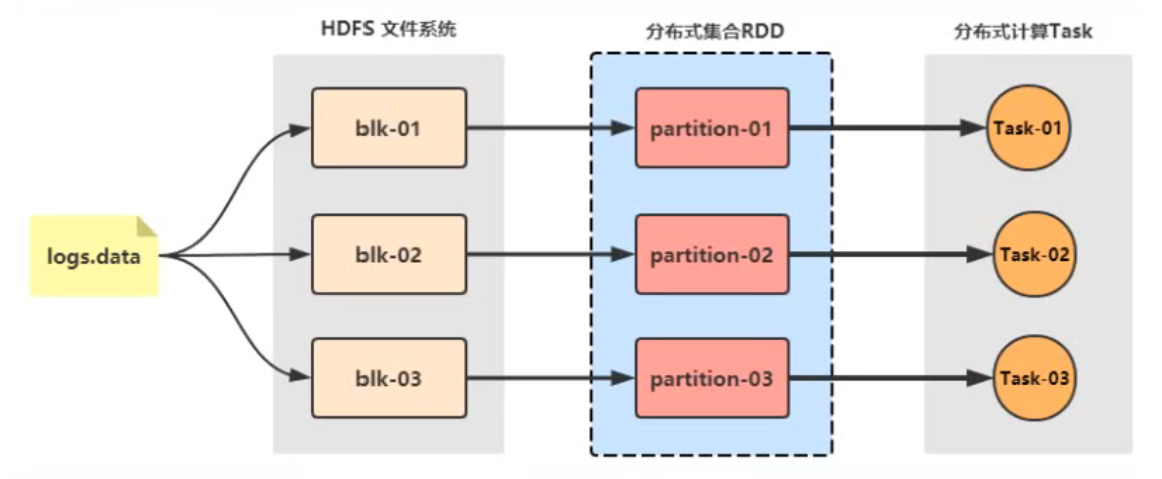
- Saprk 和 Flink 的 task 是以线程方式运行的,而 MapReduce 是进程方式运行,线程运行速度快于进程,这是 Spark 速度更快的原因之一;