文档
- elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位,对应 RDB 中的一条记录,比如一条日志、一部电影、一篇文章;
- 文档在保存到 elasticsearch 前会被序列化成 json 格式,json 对象有字段组成(字段类型包括:字符串 / 数值 / 布尔 / 日期 / 二进制 / 范围类型);
- 每个文档都有一个 unique ID,这个 ID 可以自己指定也可以有 elasticsearch 自动生成;
元数据
- 在Elasticsearch下,一个文档除了有数据之外,它还包含了元数据(Metadata);
- 每创建一条数据时,都会对元数据进行写入等操作,元数据定义了每个添加的doc的处理方式;类似于数据库的表结构数据;
- 有些元数据是在创建mapping的时候就会设置;
- 文档有三个必须的元数据元素:
- _index,文档在哪存放
- _type,文档表示的对象类别
- _id,文档唯一标识
- 注意:elasticsearch 中这三个元数据加在一起,构成了文档在 Elasticsearch 中的唯一标识;
索引 index
- 一个索引是拥有相似特征的文档的集合;
- index V.S. shard
- index,体现逻辑空间概念,每个所以都有自己的 mapping 定义;
- shard,体现了物理空间概念,索引中的数据分散在 shard 上;
- 索引的 mapping V.S. settings
- mapping 定义文档字段的类型;
- settings 定义不同的数据分布;
- 索引库是多个 type 的集合;
- 对文档进行 CRUD 时需要使用索引名称;
- mysql:一个应用对应一个数据库,一对一;
- ES:一个应用可以对多个具有相似特征的对象构建索引,如用户索引、订单索引等,一对多;
- 类型 type
- 相当于 RDB 的表;
- 一个类型是索引的一个逻辑上的额分区;
- ES 5.x 一个索引中可以创建多个 type;
- ES 6.x 兼容之前的一个索引对多个 type,但是不能创建多个 type;
- ES 7.x 一个索引不能创建多个 type,只能创建一个 type;
- 字段 field
- 相当于 RDB 数据表中的字段;
- 对同一个文档,根据不同属性(字段)进行分类;
- 映射 mapping
- 对应 RDB 的表结构定义;
- mapping 定义了映射关系;
- mapping 定义每个 type 中有哪些 field 字段、字段名称、是否分词、是否索引、是否存储等;
- 文档 document
- 文档是一个被索引的信息单元;
- 文档以 json 格式表示;
- 一个 index / type 里面可以存储任意多的文档;
- 接近实时 NRT
- 从开始索引一个文档,到文档被搜索到,延时通常在 1s 以内;
- 集群 cluster
- 多个节点组织在一起,共同持有整个数据,提供索引和搜索功能;
- 一个集群有一个唯一的名字标识,一个节点只能通过指定某个集群的名字,加入这个集群;
节点
- 概念
- 一个节点就是一个 elasticsearch 实例,本质是一个 Java 进程;
- 一台机器上可以运行多个 elasticsearch 进程,生产环境一般建议一台服务器上只运行一个 elasticsearch 实例;
- 每个节点在启动之后,都会被分配一个 UID,保存在 data 目录之下;
- 节点类型
- master-eligible nodes & master node;
- data node;
- coordinate node;
- hot & warm node;
- machine learnning node;
- trible node;
- 节点 & 集群
- 一个集群可以拥有任意多个节点;
- 每个节点都有自己的名称,一个节点可以通过配置节点名称的方式,加入一个集群;
-
任意一个节点启动以后,都会创建并加入一个叫做 elasticsearch 的集群中;
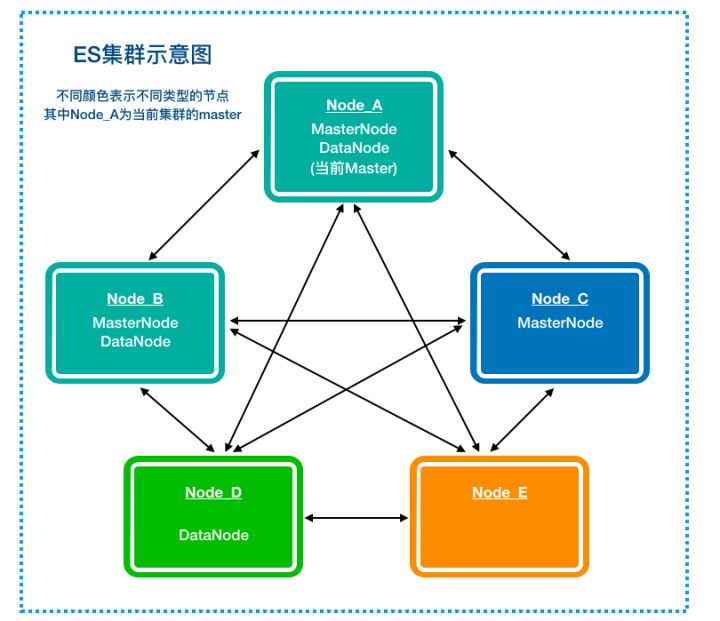
- master-eligible nodes & master node
- master-eligible,表示有资格参加选举成为 master node;
- 每个节点启动后默认就是 master-eligibel node,有资格参加选举成为 master-node;
- 集群中的第一个节点启动后,会默认选举自己作为 master node;
- 集群中每个节点都保存了集群状态信息;
- 只有 master node 才能修改集群的状态信息(cluster state),如创建或删除索引,跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点;
- 集群状态(cluster state),维护了一个集群中必要的状态信息,包括所有的节点信息、所有的索引和相关的 mapping 与 setting 信息,以及分片的路由信息;
- 集群中如果任意节点都能修改信息,则会导致数据不一致性;
- data node
- 用于保存数据的节点成为 data 节点;
- 一个节点可以是 master/master-eligible 节点,也可以是 data 节点,也可以同时为 master/master-eligible 和 data 节点;
- 节点配置
- 开发环境中,一个节点最好只承担一种角色;
- 职责明确、管理方便;
- 不同角色的节点,配置不同的硬件,达到性能最优;【TODO】
- 通过节点参数配置节点角色,如 node.master = true、node.data=fales;
分片
- 分片类型
- 主分片(primary shard) & 分片副本(replica shard);
- 主分片(primary shard)
- 主分片,解决数据水平扩展问题,通过主分片可以将数据分散到集群内的所有节点;
- 主分片数量在索引创建时指定,后续不允许修改,除非 reindex;
- 副本(replica shard)
- 副本,解决的是数据的高可用问题;
- 副本是主分片的拷贝;
- 副本数量可以动态调整;
- 增加副本,在一定程度可以提高服务的可用性,提高数据读取吞吐量;
- 分片设定
- 如果分片数设置过小,会导致后续无法增加节点,进而无法进行水平扩展;
- 吐过分片数设置过大,会导致数据重新分配,耗费大量时间,同时会影响排名、打分等数据的统计;
- 默认情况下,elasticsearch 中的每个索引会被分成 5 个主分片和 1 个复制,如果集群中有 2 个节点,那么集群将会有 5 个主分片、5 个复制分片,每个索引共 10 个分片;