1. 数据流转过程
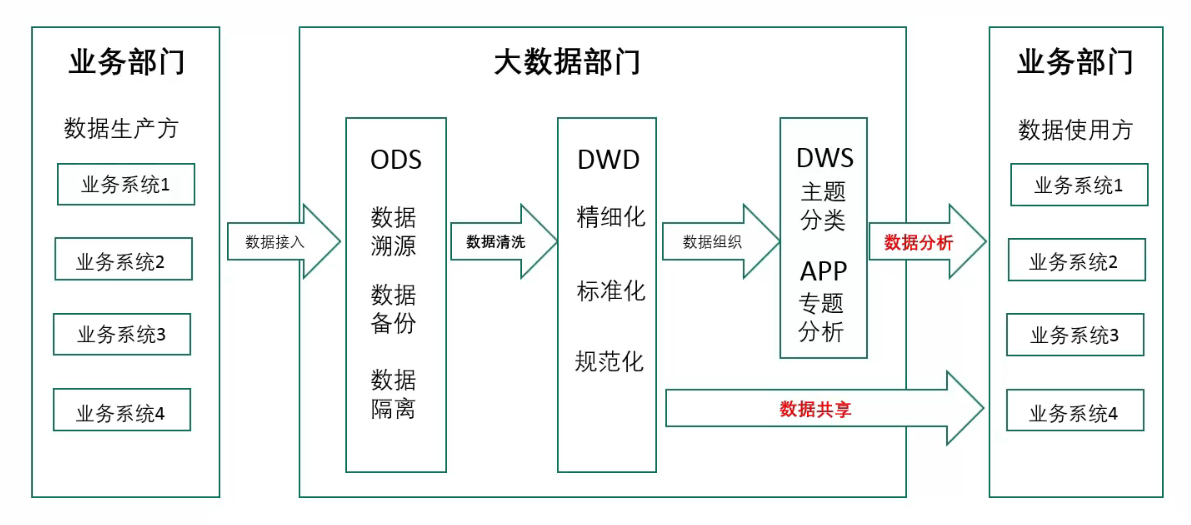
一般意义上,ETL 数据清洗结束后,输出的数据会放到 DWD 层。
2. 源数据的问题
2.1. 数据本身问题
- 数据值录入错误
- 数据缺失
- 数据重复
2.2. 表设计问题
- 建表命名不规范
- 数据不规范
- 字段属性错误
- 格式不统一
- 缺少宽表
- 业务数据一般字段较少,但数据分析却需要宽表;
- 字段组合问题
- 业务数据表内的字段只服务于业务,但是数据分析时需要多个表拆分出的部分字段合并成宽表;
- 表之间缺少关联
- 没有面向数据分析的外键设计
- 需要看到数据,才能知道如何制定规则;
- 有些数据,需要跨部门联合检验;
3. 数据清洗的作用
- 确保数据的可用性
- 真实
- 有效
- 规范
- 统一
- 反向提升业务系统
- 及时发现问题,并提交给来源系统做问题定位和整改,进而提升数据的可用性。
4. 数据清洗的目标
4.1. 完整性
单条数据是否存在空值,统计的字段是否完善。
4.2. 全面性
通过比较最大值,最小值,平均值,数据定义等来判断数据是否全面。
4.3. 合法性
数值的类型、内容、大小是否符合我们设定时候的预想。
4.4. 唯一性
数据是否重复记录。
4.5. 权威性
同一个指标出现多个来源的数据,且数值不一样。
5. 数据校验
5.1. 合规性校验:基于规则
- 身份证合规
- 行政区划、年份、月份、日期,需要符合规则
- 手机号合规
- 位数
- 号段
- 事实表多表联合校验
- 邮箱地址合规
- 组织结构代码证合规
- 地址信息合规
- 一致性校验:
- 属性一致性
- 关系一致性
5.2. 值域范围校验
- 一般需要与维度表联合校验
- 比如:
- ID:某订单数据的商品ID为10001,但商品表ID字段值域范围最大是10000,超出了值域范围;
- 性别:性别为 3,不在性别维度表 0(未填写)、1(男)、2(女)值域范围内;
5.3. 数据格式校验
- 比如:
- 概率:概率值应该为 0~1,但实际确实 2、3、4 等;
- 年龄:应该为整数值,并且在0~120之间。
5.4, 空值校验
- 非空字段,比如:年龄、性别
- 可为空字段,比如:爱好
5.5. 准确性校验
- 比如:业务人员一、二级部门归属;
5.6. 完整性校验
- 比如:地址信息缺失街道门牌号
6. 清洗方法
6.1. 数据过滤
- 基于样本数据过滤
- 主要用于处理垃圾数据:
- 比如:垃圾样本库
- 垃圾短信
- 垃圾邮件
- 基于业务规则过滤
- 比如:无效日志
- 网络攻击
- 爬虫
- 比如:无效日志
- 基于逻辑规则过滤
- 不合理值
- 比如:年龄为1000岁;
- 矛盾内容
- 比如:收获地址为美国,取件人号码却是+86开头;
- 不合理值
6.2. 异常值清洗
- 异常值检查方法:
- 统计分析
- 箱线图分析
- 基于模型检测
- 同数据模型不能拟合
- 簇集合: 异常值不属于任何簇
- 回归模型:异常值相对远离预测值
- 同数据模型不能拟合
- 基于距离分析
- 近邻性度量:异常值远离其他对象
- 基于密度分析
- 异常点的局部密度,显著大于大部分近邻
- 基于聚类
- 不强属于任何簇的离群点
- 异常值的处理方法:
- 数据光滑处理
- 丢弃数据
- 视为缺失值
- 中位数修正
- 众数修正
- 均值修正
- 不处理
6.3. 数据去重
- 全业务字段重复
- 一般出现在数据同步过程中,
- 比如同步任务异常、或者 kafka 同步的数据本身就存在重复;
- 需要设定唯一主键,防止出现重复。
- 业务规则重复
- 根绝业务规则判定需要保留的数据
- 比如:一个身份证号对应多个用户ID
6.4. 数据规范化 & 格式统一
- 时间、日期格式统一
- 数值格式统一
- 全角半角显示格式统一
- 大小写格式统一
- 经纬度格式统一
- 设备 Mac 地址格式统一
6.5. 数据填充
- 人工填充
- 特殊填充
- 统计量填充
- 模型预测填充
- 插值法填充
- 哑变量填充
- 热卡填充
- 期望值最大化填充
6.6. 数据置空
- 置空不合规字段:
- 比如:
- 在BI分析时,尽管有部分字段不合规,但字段值置空并不影响数据分析,所以就可以将数据置空
- 比如:
6.7. 数据丢弃
- 丢弃问题数据
- 需要分析对看结果造成的影响大小。
6.8. 数据合并
- 多表合并
- 横向合并
- 纵向合并
- 多字段合并成新表
- 多表合并成宽表
6.9. 数据拆分
- 横向拆分
- 按照也无需求,将表内的不同字段拆分出来与其他表字段合并,或者单独成表;
- 纵向拆分
- 数据量太大的单表,纵向拆分成多个表,以提升SQL性能;
- 按业务拆分
- 根据需求,将不同数据拆分成多个表
- 按功能拆分
- 拆分成训练集、测试集
6.10. 数据关联
- 内连接
- 左右连接
- 全连接
- 外键关联
6.11. 数据切割
- 数据切割,主要是针对时间跨度较长的数据,进行横向的切分。
- 比如:
- 有些公司还会将数据 session 做切割,这个一般是 app 的日志数据,其他业务场景不一定适合。这是因为 app 有进入后台模式,例如用户上午打开 app 用了10分钟,然后 app 切入后台、晚上再打开,这时候 session 还是一个,实际上应该做切割才对。
- 也有公司会记录app进入后台,再度进入前台的记录,这样来做 session 切割。
6.12. 数据映射
- 将GPS经纬度转换为省市区详细地址;
- 业界常见 GPS 快速查询,一般将地理位置知识库使用 geohash 映射,然后将需要比对的 GPS 转换为 geohash 后跟知识库中 geohash 比对,查找出地理位置信息。
- 将 IP 地址也转换为省市区详细地址;
- 业界有很多快速查找库,基本原理都是二分查找,因为 ip 地址可以转换为长整数;
- 典型的如 ip2region 库;
- 将时间转换为年、月、日甚至周、季度等维度信息;
注意:数据映射,一般只映射常见指标、以及明确的企业开发中后续会用到的指标。因为数据量较大,如映射的指标后续用不到,只会平白增加开发、维护成本。
7. ETL 工具
7.1. Kettle
- Kettle是一款国外免费开源的、可视化的、功能强大的ETL工具,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。
- 缺点:
- 打开时速度慢
- 性能较差
- 存在着bug
- 用户的体验不好
7.2. Datastage
- Datastage是一款非常专业的ETL处理工具,为整个 ETL 过程提供了一个图形化的开发环境,它是一套专门对多种操作数据源的数据抽取、转换和维护过程进行简化和自动化,并将其输入数据集或数据仓库的集成工具。
- 缺点:
- 价格比较昂贵,企业版的花费每月需好几万的人民币。
7.3. Informatica
- Informatica与Datastage旗鼓相当,也是一款专业的商业ETL处理工具,依靠图形化的操作界面,无需编程语言便可以完成ETL过程的操作。
- 缺点:
- 虽然价格比Datastage略低,但要部署的话也需要不少的预算。