1. ETL 定义
ETL,是数据抽取(Extractor)、清洗转换(Transform)、数据加载(Load)的过程,是构建数据仓库的重要环节之一。
ETL,负责将分布、异构的数据源中的数据,如关系数据、平面数据、文件等取到临时中间层,进行清洗、转换、集成,最后加载到数据仓库或数据集市,成为联机分析处理、数据挖掘的基础。
ETL 的目的,是将其中分散、零乱、标准不统一的数据,整合到一起,为企业的决策提供分析依据。ETL 是 BI 项目的重要环节,一般要花掉整个 BI 项目的三分之一的时间精力,ETL 设计的好坏直接关系到 BI 项目的成败。
其中,ETL三个部分中:
- Extractor,是从不同的数据源抽取到 ODS(operational data store),这部分尽可能的选用高效的抽取方法,以提升 ETL 的性能;
- Transform,数据清洗和转换,最耗费时间,一般这部分工作占了整个 ETL 的三分之二。
- Load,清洗完的数据一般直接写入数仓 DW(data warehouse)中。
2. Extractor
在数据抽取环节,需要做大量的数据调研工作。比如:要搞清楚数据是从几个业务系统来的,各个业务系统的数据库服务器是什么样的,连接方式如何选择;有多少手工数据,手工数据如何获取;是否存在非结构化数据,非结构化数据如何处理。
这里需要注意的是,数据抽取的方式是多种多样的,对于关系型数据库可以通过 ODBC 和 JDBC,对于文件型数据可以通过同步工具等上传。
另外,在这步抽取环节,其实就可以做一部分的清洗过滤和转换工作。比如:数据库中的无效数据、缺失数据、重复数据、异常数据等要处理;不同的数据格式需要统一;半结构化数据、非结构化数据,有的如日志要进行信息提取并汇聚成结构化数据保存,有的如音视频除了提取信息,也要保留原始数据。
还有数据抽取的方式、策略,也需根据业务需求进行设计,是全量提取、还是增量提取,是实时同步、还是半实时同步、还是离线同步,需要结合业务需求进行针对性的设计。
3. Transform
数据的清洗转换,是 ETL 最重要的工作内容。数据清洗转换的核心目标,是确保数据的可用性。而要确保可用性,则需要做到数据的真实、有效、规范、统一。 同时,一个好的 ETL 系统,也可以反向提升业务系统。及时发现问题,并提交给来源系统做问题定位和整改,进而提升数据的可用性。
3.1. 数据清洗
业务系统→ODS的过程,过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
3.2. 数据转换
ODS→DS的过程,主要进行不同维度的数据转换、数据颗粒度的转换,以及一些业务规则的计算。
-
不同维度数据转换
将不同业务系统的相同类型的数据进行统一,例如编码转化:不同供应商在不同业务系统的编码不同;字段转换;度量单位的转换等。
-
数据颗粒度的转换 业务系统存储着颗粒度较细的数据,而数据仓库的数据时用来分析的,不需要颗粒度很细的数据,所以会将业务系统数据按照数据仓库的颗粒度进行转换。
-
业务规则的计算 企业有不同的数据指标以及业务规则,此时需要将这些数据指标计算好后存储在数据仓库中,供数据分析使用。
3.3. 校验规则 & 数据标准化
- 在数据清洗转换前,需要制定一套系统、全面、规范的数据校验规则,以及一套完整、统一的输出数据的标准化规范;
- 校验规则包括合规性校验、值域范围校验、数据格式较严、空值校验、准确性校验、完整性校验等,同时针对不同问题对应的处理策略;
- 在明确了数据的校验规则之后,在进行过滤、去重、格式转换、数据置空、丢弃、赋值等操作。
3.4. 具体内容
- 数据采样:
- 通过随机、加权、分层、下采样四种方式对数据源进行抽取
- 数据拆分:
- 将数据进行横向或者纵向的拆分
- 数据过滤:
- 按照用户需求,通过写SQL语句,对数据按照过滤表达式进行筛选
- 数据合并:
- 将两张表按行或列的方式进行合并
- 数据关联:
- 通过内连接、左右连接、全连接的方式对两个表格进行关联
- 空值处理、去除重复值、聚合等。
4. Load
- 将清洗和转换好的数据,直接加载到数据库对应表中;
- 全量更新:
- 如果是全量方式则采用覆盖的方式,
- 增量更新:
- 如果是增量则选择追加的方式。
5. ETL 工具
5.1. sqoop
- sqoop 的缺点:
- 由于mysql的表结构变更,引起的数据抽取失败。(目前添加监控,自动更改还需要开发)
- 抽取速度有待提高,对于大表,指定多个map,可能会导致数据重复,需要单独做处理。
- 不支持 mongoDB
- 启动的速度比较慢
5.2. DataX
-
DataX 简介
DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
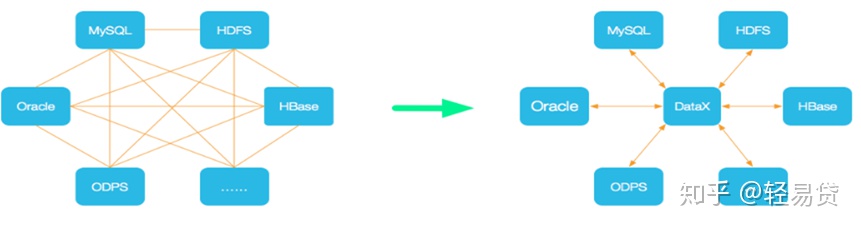
-
DataX框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
-
DataX 与 sqoop 的对比:
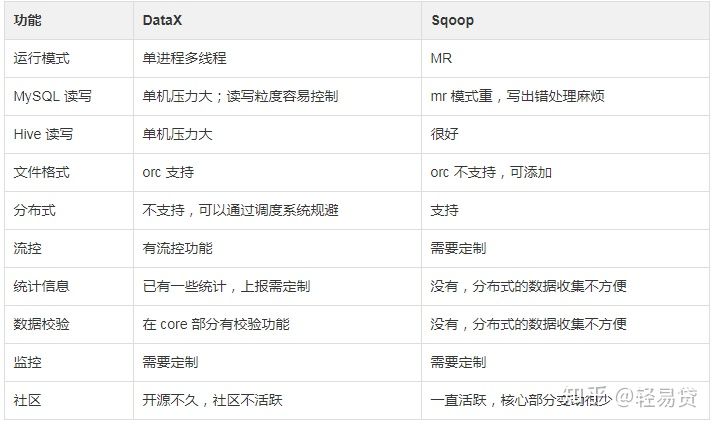
-
DataX 的问题:
- 目前公司表中基本上没有自增主键,对于数据量大的表(目前数据量还有待测试),抽取速度慢(6千万的表7116rec/s,两千万的速度在7902rec/s,1千万的表在19307rec/s 左右),如果有自增主键或者整型的索引字段,速度是56716rec/s ,使用uuid生成的主键,会存在主键切分不均匀现象(可以修改源码);
- 目前开源版本只支持单机模式,需要依赖调度系统(在每个节点上部署客户端);
- 不支持自动创建表和分区,写入的hdfs路径必须存在(可以后期修改源代码,或者使用脚本生成);
- 生成配置文件比较繁琐(每张表需要生成一张配置文件,可以使用代码生成)。
5.3. Airflow
-
Airflow是什么
airflow 是一个编排、调度和监控 workflow 的平台,由 Airbnb 开源,现在在 Apache Software Foundation 孵化。airflow 将workflow编排为由tasks组成的DAGs(有向无环图),调度器在一组workers上按照指定的依赖关系执行tasks。同时,airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且airflow提供了监控和报警系统。
-
Airflow 的基础概念
-
DAGs:
即有向无环图(Directed Acyclic Graph),将所有需要运行的 tasks 按照依赖关系组织起来,描述的是所有tasks执行的顺序。
-
Operators:
airflow 内置了很多 operators,如 BashOperator 执行一个 bash 命令,PythonOperator 调用任意的 Python 函数,EmailOperator 用于发送邮件,HTTPOperator 用于发送HTTP请求, SqlOperator 用于执行SQL命令.
同时,用户可以自定义Operator,这给用户提供了极大的便利性。可以理解为用户需要的一个操作,是Airflow提供的类。
-
Tasks:
Task 是 Operator的一个实例
-
Task Instance:
由于Task会被重复调度,每次task的运行就是不同的task instance了。Task instance 有自己的状态,包括”running”, “success”, “failed”, “skipped”, “up for retry”等。
-
Task Relationships:
DAGs中的不同Tasks之间可以有依赖关系
-
-
Airflow与同类产品的对比:
