1、字体反爬原理
- 在CSS3之前,Web开发者必须使用用户计算机上已有的字体。但是在CSS3时代,开发者可以使用@font-face为网页指定字体,开发者可以将心仪的字体文件放在Web服务器上,并在Css样式中使用它。用户使用浏览器访问Web应用时,对应的字体会被浏览器下载到用户的计算上。
- CSS的作用是修饰HTML,所以在页面渲染的时候不会改变HTML文档内容。由于字体的加载和映射工作是由CSS完成的,所以即使我们借助Splash、Selenium和Pypeeteer工具也无法获得对应的文字内容。字体反爬正式利用了这个特点,将自定义字体应用到网页中重要的数据上,使得爬虫程序无法获得正确的数据。
2、 某点评网站字体反爬介绍
-
打开网站某店铺页面,邮件检查店铺评论数、地址,发现想要查找的数据变成了下面这个样子:
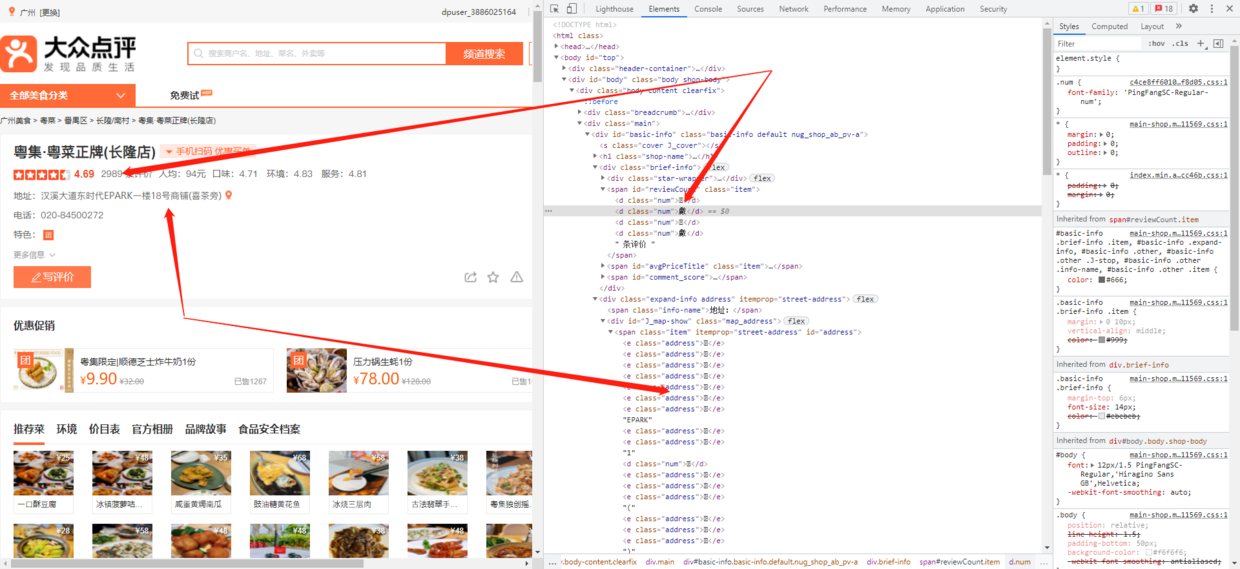
- 像这种情况就是字体反爬,对于这类点评网站来说,评分、评论数、金额、店换号码、店铺地址、特色菜品、用户评分、用户评论、用户消费金额 等等这些都属于核心资产,都在加密的范围内;
-
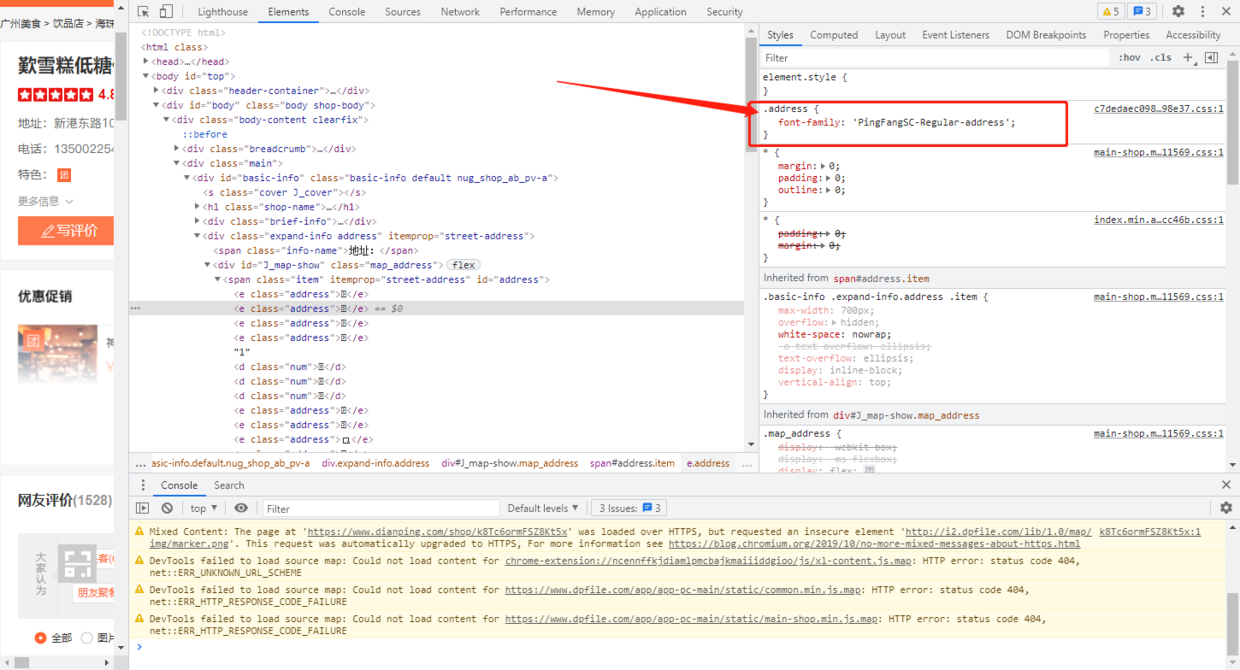
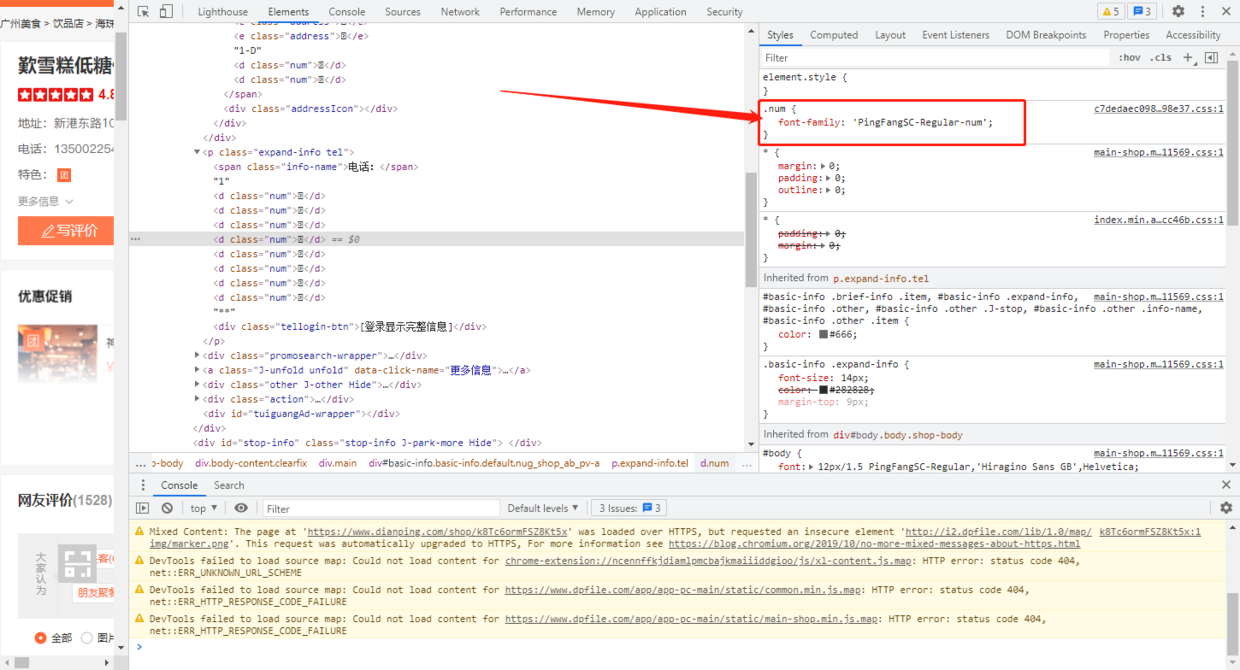
我们查看右侧的 style,发现 地址 对应 style 中 .adress 下 font-family 值为 PingFangSC-Regular-address,而 电话号码 对应的 style 中 .num 下 font-family 值为 PingFangSC-Regular-num,由此我们也可以推断,不同的网页内容,加载的字体文件是动态变化的;
-
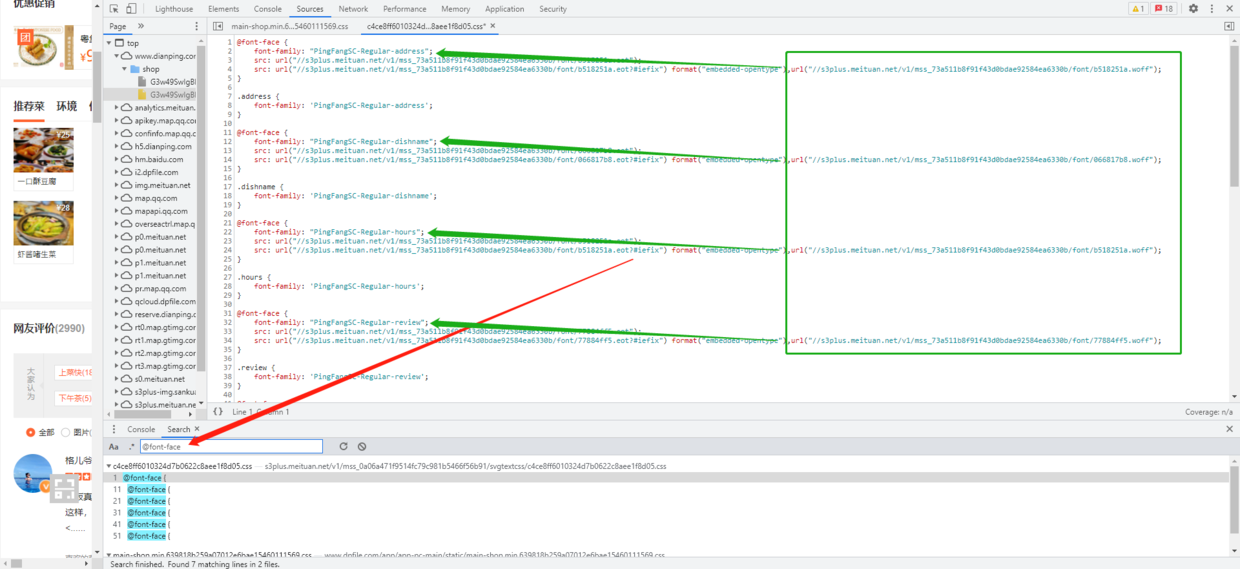
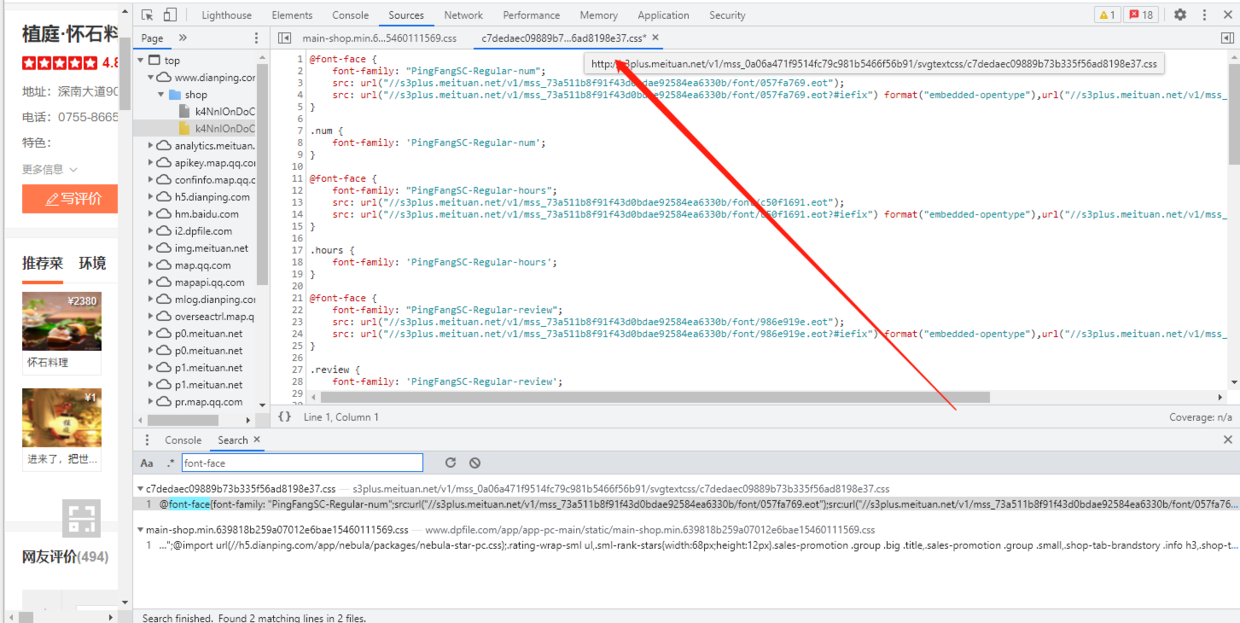
那具体什么内容,对应什么字体文件呢?我们打开 全局 search,搜索 @font-face,找到下面的 .css 文件,打开以后通过分析发现, address、dishname、hours、review、num、shopdesc,分别对应了不同的 .woff 文件,这里的 .woff 文件就是字体存放的地方;
-
除了通过全局搜索的方式获取字体文件的 url 地址,也可以鼠标放在 .css 文件名上面,就能看到 .css 文件的 url;
-
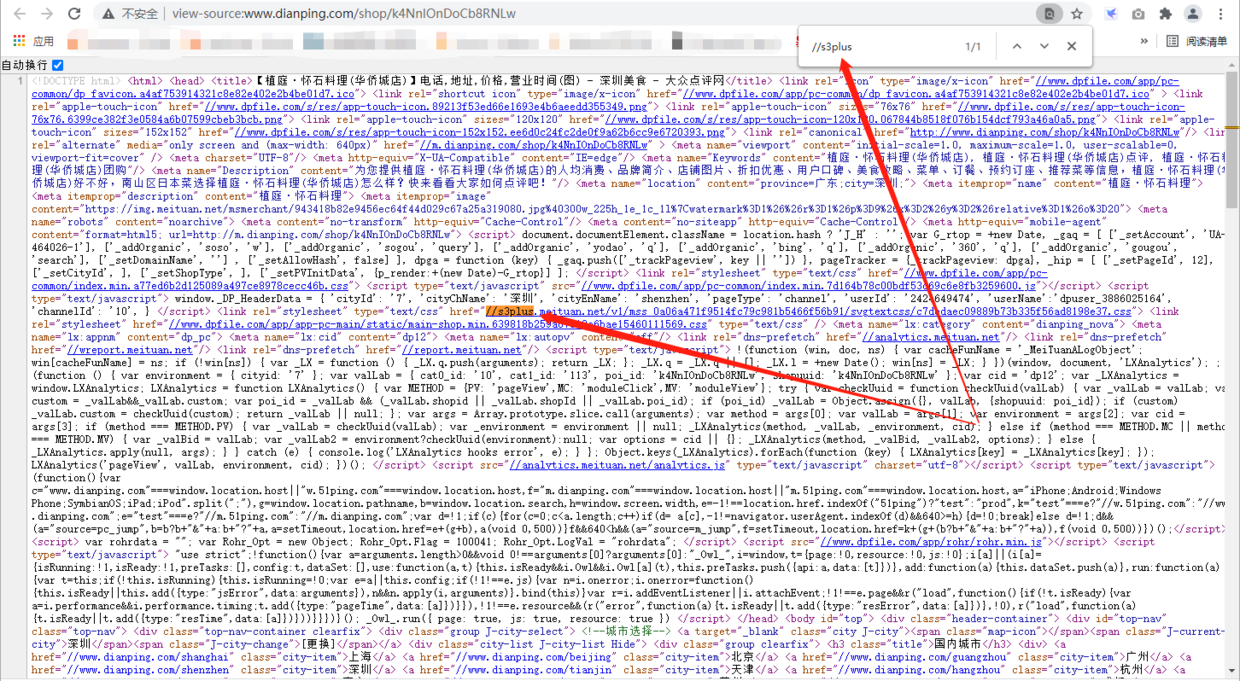
在实际爬虫开发的时候一般访问网页后,在网页源代码中获取 .css 文件的 url,具体可以通过正则表达式的方式匹配提取;
3、反反爬策略
-
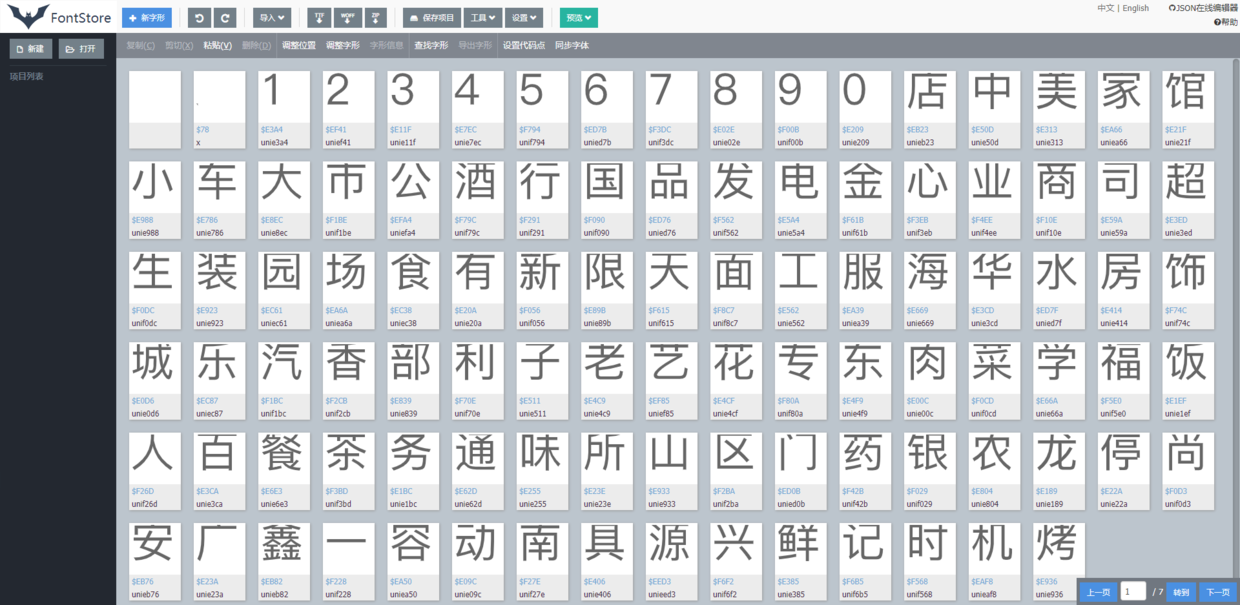
我们这里以 review 的 woff 文件为例子,访问并下载该 woff 文件,之后将下载的文件拖入 https://font.qqe2.com/ ,得到下图:
-
此时我们发现,每个字符都对应了一个编码,这里的编码代表什么意思呢?我们打开调试面板,在 Network 中查找 review 相关的 response,通过分析我们发现,返货的数据中 <svgmtsi class="review"> ;</svgmtsi> 对应实际的汉字 味,查找字体文件我们发现,e255 和字体编码 unie255 相对应;
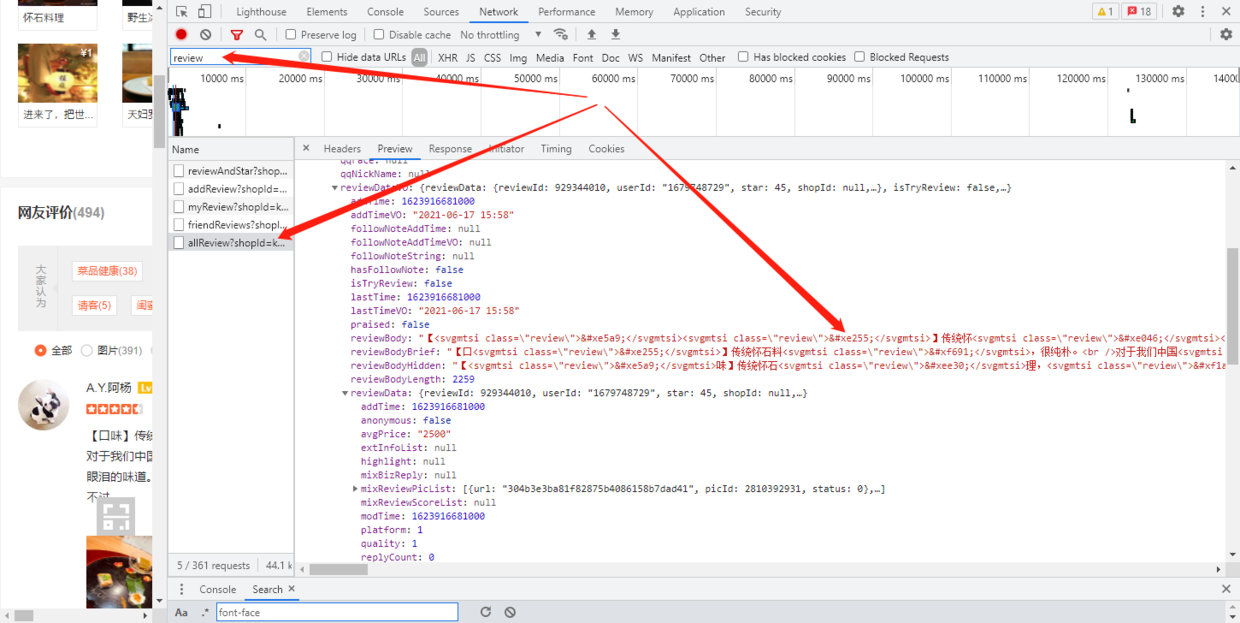
-
至此,我们就已经完成了字体反爬的破解工作。
4、代码实现
-
核心步骤包括:
- 访问网页,获取页面源代码;
- 正则匹配查找 .css 文件的 url;
- 查找 .woff 文件并下载保存;
- TTFont 模块读取 woff 文件,转换成 xml 保存;
- 读取 xml 文件创建映射表;
- 发起请求获取 review 等数据;
- 通过映射表,替换被加密的数据;
-
代码: – 略:参考:https://github.com/downdawn/dzdp/tree/595fbcab21f7e342c51c521c102e8e08ecb6d64f。