两类索引
- MySQL 中的索引按照物理存储方式,可以分为聚簇索引和非聚簇索引:
- 日常所说的主键索引,其实就是聚簇索引(Clustered Index);
- 主键索引之外,其他的都称之为非主键索引,
- 非主键索引也被称为二级索引(Secondary Index),或者叫作辅助索引。
- 对于主键索引和非主键索引,使用的数据结构都是 B+Tree,唯一的区别在于叶子结点中存储的内容不同:
- 主键索引的叶子节点,存储的是一行完整的数据;
- 非主键索引的叶子节点,存储的则是主键值,叶子结点不包含行记录的全部数据;
MySQL 回表问题
- 当我们需要 SQL 查询的时候:
- 如果是通过主键索引来查询数据
- 例如:
select * from user where id=02,那么此时只需要搜索主键索引的 B+Tree 就可以找到数据;
- 例如:
- 如果是通过非主键索引来查询数据
- 例如:
select * from user where username='小王',那么此时需要 先搜索 username 这一列索引的 B+Tree,搜索完成后得到主键的值,然后再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
- 例如:
- 对于第二种查询方式而言,一共搜索了两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。
- 如果是通过主键索引来查询数据
- 两种查询方式差异:
- 通过非主键索引查询要扫描两棵 B+Tree,而通过主键索引查询只需要扫描一棵 B+Tree;
- 所以,如果条件允许,还是建议在查询中优先选择通过主键索引进行搜索。
- 例如:
-
对于
student表,其中包含字段id设置主键索引、name设置普通索引、age(无索引),并向数据库中插入4条数据:(“小赵”, 10)(“小王”, 11)(“小李”, 12)(“小陈”, 13)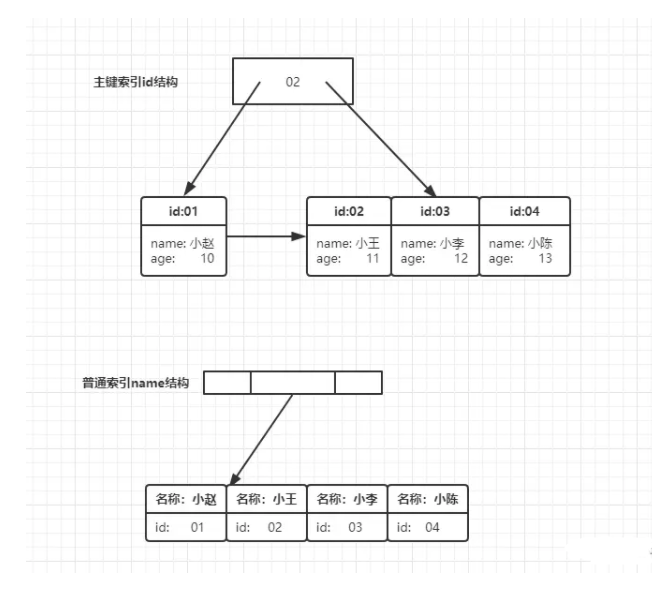
-
分析发现:
- 在叶子节点中主键索引存储了整行数据;
- 而非主键索引中存储的值为主键 id;
-
- 执行如下 sql
SELECT age FROM student WHERE name = '小李',流程为:- 在 name 索引树上找到名称为小李的节点 id 为 03;
- 从 id 索引树上找到 id 为 03 的节点,并获取所有数据;
- 从数据中获取字段名为 age 的值返回 12;
- 在流程中,从非主键索引树搜索回到主键索引树搜索的过程,就是回表。
索引覆盖
- 回表问题:
- 在前面的查询中,因为查询结果只存在主键索引树中,必须回表才能查询到结果;
- 因为需要两次查询,整个过程性能低下、耗费资源、浪费时间。
- 那么如何优化这个过程呢?这就需要使用覆盖索引。
- 索引覆盖:
- 就是把单列的 非主键索引 修改为 多字段 的联合索引;
- 这样在一棵索引数上,就找到了想要的数据,不需要去主键索引树上、再检索一遍;
- 这个现象,称之为 索引覆盖。
- 索引覆盖避免了回表:
- 索引覆盖从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
使用联合索引实现索引覆盖
- 前面介绍了覆盖索引,但具体如何实现呢?这就要使用到 联合索引。
- 示例:
- 对于之前已经建立的表
student,业务需求是根据名称获取学生的年龄,并且该搜索场景非常频繁; - 这时就要:
- 先删除掉之前以字段
name建立的普通索引; - 再以
name和age两个字段建立联合索引;
- 先删除掉之前以字段
-
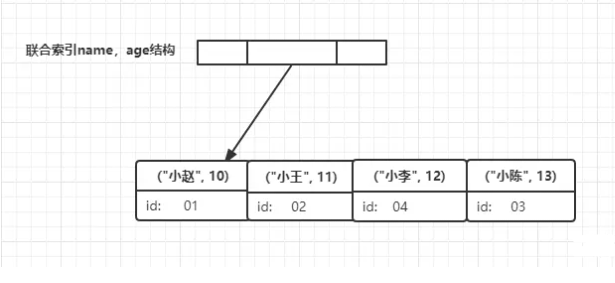
此时,sql 命令与建立后的索引树结构如下:
- 对于之前已经建立的表
- 执行如下sql:
select age from student where name = '小李',执行流程为:- 在
name,age联合索引树上找到名称为小李的节点; - 此时,节点索引(非主键索引)里包含信息 age 直接返回 12;
- 在
- 如何确定数据库成功使用了覆盖索引呢?
-
当发起一个索引覆盖查询时,在
explain的extra列可以看到using index的信息,这就表明成功使用了覆盖索引。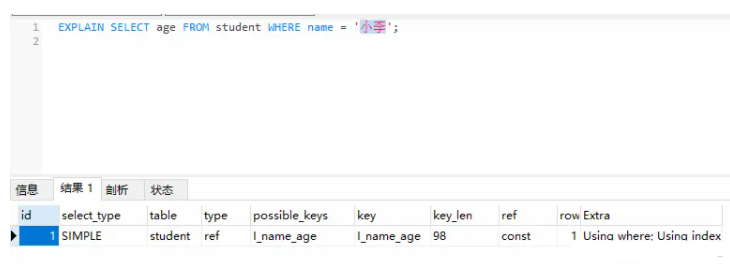
-
-
联合索引,实现了覆盖索引,避免了回表现象的产生,从而减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是性能优化的一种手段。
- 哪些场景需要覆盖索引
- 全表 count 查询
- 列查询回表优化
- 分页查询