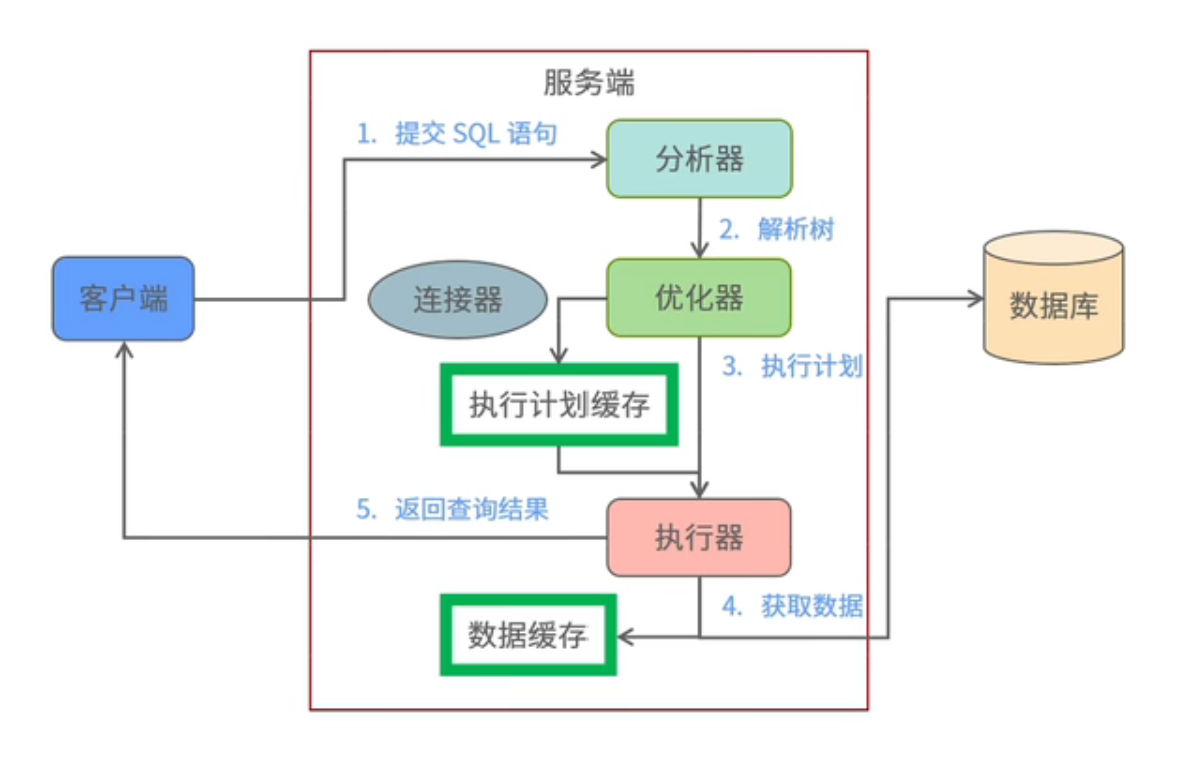
执行过程流程图
连接器:客户端访问服务器
- 客户端需要通过连接器访问 MySQL Server,连接器主要负责身份认证和权限鉴别的工作。也就是负责用户登录数据库的相关认证操作。
- 例如:校验账户密码,权限等。在用户名密码合法的前提下,会在权限表中查询用户对应的权限,并且将该权限分配给用户。
-
在连接完成以后可以查看连接状态,通过命令行“show processlist”生成下图的查询结果。其中“Command”列返回的内容中,“Sleep”表示MySQL相同中对应一个空闲连接。而“Query”表示正在查询的连接。
- MySQL将连接器中的连接分为长连接和短连接:
- 长连接是指连接成功后,客户端请求一直使用是同一个连接。
- 短连接是指每次执行完SQL请求的操作之后会断开连接,如果再有SQL请求会重新建立连接。由于短连接会反复创建连接消耗相同资源,因此多数情况下会选择长连接。但是为了保持长连接,会占用系统内存,而这些被占用的内存知道连接断开以后才会释放。这里提出了两个解决方案: 定期断开长连接,每隔一段时间或者执行一个占用内存的大查询以后断开连接,从而释放内存,当查询的时候再重新创建连接。
- MySQL 5.7 或者更高的版本,通过执行 mysql_reset_connection 来重新初始化连接。此过程不会重新建立连接,但是会释放占用的内存,将连接恢复到刚刚创立连接的状态。
提交 SQL 语句
- 客户端先发送查询语句给服务器
检查缓存
- 服务器检查缓存,如果存在则返回。
- 缓存的查询在sql解析之前进行。
- 缓存的查找通过一个 对大小写敏感的哈希表实现,即直接比对sql字符串。因此只要有一个字节不同,都不会匹配中。
分析器:解析 SQL
- Mysql 没有命中查询缓存,那么就会进入分析器;
- 分析器主要是用来分析 SQL 语句是来干嘛的,这里就是把sql做解析,变成一个解析树;
-
解析时会做mysql语法规则验证。
-
分析器主要分为以下两步:
- 词法分析:
- 一条SQL语句有多个字符串组成,首先要提取关键字;
- 比如:select,提出查询的表,提出字段名,提出查询条件等等。
- 语法分析:
- 根据词法分析的结果,语法分析主要就是判断你输入的SQL语句是否正确,检查关键字错误、关键字顺序、引号匹配是否符合 MYSQL 语法;
- 如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒。
- 注意:
- 词法分析程序将整个查询语句分解成各类标志,语法分析根据定义的系统语言将“各类标志”转为对MySQL有意义的组合。
- 最后系统生成一个语法树(AST),语法树便是优化器依赖的数据结构。
- 词法分析:
- 预处理
- 和元数据关联校验,检查数据表和列是否存在,解析名字和别名。
优化器:生成真正的执行计划
- mysql 会生成多种计划:
- 系统会分别计算一个预测成本值,然后选一个成本最小的计划。
- 计算信息来自于表的页面个数、索引分布、长度、个数、数据行长度。
- 因为多种原因,可能不会选择到最优的计划。
- 优化方法包括静态优化和动态优化。
- 静态优化和动态优化的区别:
- 静态优化类似“编译期优化”,只和语句结构有关,和具体值无关
- 动态优化是在运行中去优化的,需要依赖索引行数、where取值,执行次数可能比静态优化要多。
mysql 的优化类型
- join 顺序
- 关联表(join)的顺序可能会变
- join 连接
- outer join 可能会变成内连接
- 优化条件表达式
- 例如:5=5 AND a>5 被简化成 a>5
- 优化 MAX\MIN
- 如果是MAX(索引),那么直接拿 B+ 树的第一条或者最后一条即可
- 计算常数
- 当发现某个查询或者表达式的结果、是可以提前计算出来的时候,就会优化成常数
- 索引覆盖
- 如果只要返回索引列,就不会走到最底层去。
- 子查询优化
- 提前终止查询
- 例如:LIMIT
- 等值传播:
- join 中可能把左表的 where 拿给右表一起用
- 排序:
- 例如:where xx in(1,2,3,4,5,6)这个条件,并不是简单遍历判断,会先排序、然后用二分去判断是否存在。
数据和索引的统计信息
- 统计信息是存储引擎去计算的,不同的存储引擎有不同的统计信息
- 服务器层生成查询计划时,会向存储引擎获取这些信息。
MYSQL对关联查询的执行
- join 查询的本质其实是读取临时表做关联
- 例如:
a inner join b on a.id=b.id where a.xx=y- 系统遍历 a 的每一行(此时 a 表本质上是 select * from a where a.xx=y)
- 在哪一行中 a 的 id 被定下来, 那么就会去获取一个临时表,临时表为(select * from b where a.id = id)
- 接着用这个临时表和a那一行拼接,输出多行。
- 然后再用这里的结果作为临时表,给更上层的关联去用(嵌套查询的含义)
- 如果是 left join,则就是临时表如果为空,则给 a 那一行拼接一个null。
- 例如:
关联查询优化器
- join 实际执行的顺序会关系到性能
- 例如:
- a\b\c 三个表关联,可能先让 a 和 b 关联得到的临时表里的记录只有10条;
- 如果让a和c先关联,会有10000条, 那么后面的效率就会截然不同
- EXPLAIN EXTENDED 可以展示关联的顺序
- STRAIGHT_JOIN可以手动指定关联顺序
- mysql 自己会评估搜索一个最优的顺序,但如果 join 表太多,则无法搜完所有结果(O(n!)), 那时候就会采用贪心。
- 是否使用贪心算法的边界值可以根据
optimizer_seartch_depth去指定。
排序优化
- 如果排序的量小,就用内存快速排序;如果排序的量大,就用文件排序
- mysql有2种取排序数据的方式:
- 两次传输排序: 先取要排序的字段加行序号,按照字段排序好之后,再根据行索引一条条取读
- 优点: 排序时占用内存小。
- 缺点: 排序之后读的过程会很慢,根据行序号取读不是很方便
- 单次传输排序: 直接把行读出来(行里只有需要用的列,不一定是整行) ,然后排序
- 优点: 把全部行读出来相当于顺序IO,读取速度快
- 缺点: 可能会很大导致需要文件排序
- 关联查询order by的注意事项
- 如果order by的列 都 来自关联的 第一张 表,则直接第一张表join的时候就排序了。
- 全部join完再排序,就算用了limit,也是全部join+排序后,再limit。
- 两次传输排序: 先取要排序的字段加行序号,按照字段排序好之后,再根据行索引一条条取读
执行器:根据执行计划,调用存储引擎的API来执行查询
- 当分析器生成查询计划,并且经过优化器以后,就到了执行器。
- 执行器会选择执行计划开始执行,但在执行之前会校验请求用户是否拥有查询的权限,
- 如果没有权限,就会返回错误信息
- 否则将会去调用 MySQL 引擎层的接口
- 执行对应的SQL语句并且返回结果。
返回结果
- 将结果返回给客户端