1. ID Mapping 的概念
1.1. 定义
- ID Mapping,就如同它的名字一样,咱们要做的就是将一系列的ID 关联起来,
- 一些列的ID 可能是用户在不同平台上的标识,也可能是用户在不同设施上的标识,也可能是用户在不同状态下的标识;
- ID Mapping 就是将这一系列的ID 关联起来,尽可能地将用户的数据买通,从而提供更加全面精确的剖析。
1.2. ID Mapping 的价值
- ID Mapping 要做的核心工作,就是 多端数据 的识别和 多源数据 的打通;
- ID mapping 的建立,有助于帮助营销人员获得渠道有效性的反馈,进而可以帮助营销人员进行更加精准的投放,在获得用户画像反馈之后,也能进一步提升用户体验。
1.3. One ID
- ID Mapping 的最终产出是 One ID:
- 也就是说我们为这些 Mapping 上的 ID ⽣成⼀个新的 ID,这个ID 就是One ID,也就是说当我们的One ID 成之后我们就可以使这个 One ID 来打通所有的业务系统。
2. 常见的 ID 标识
2.1. 设备 ID
- Android
- 1.10.5 之前版本,默认应用 UUID(例如:550e8400-e29b-41d4-a716-446655440000),App 卸载重装 UUID 会变,为了保障设施 ID 不变,能够通过配置应用 AndroidId(例如:774d56d682e549c3);
- 1.10.5 及之后的版本 SDK 默认应用 AndroidId 作为设施 ID,如果 AndroidId 获取不到则获取随机的 UUID。
- iOS
- 1.10.18 及之后版本,如果 App 引入了 AdSupport 库,SDK 默认应用 IDFA 作为匿名 ID。
- 1.10.18 之前版本,能够优先应用 IDFV(例如:1E2DFA10-236A-47UD-6641-AB1FC4E6483F),如果 IDFV 获取失败,则应用随机的 UUID(例如:550e8400-e29b-41d4-a716-446655440000),个别状况下都可能获取到 IDFV。
- 如果应用 IDFV 或 UUID ,当用户卸载重装 App 时设施 ID 会变。也能够通过配置应用 IDFA(例如:1E2DFA89-496A-47FD-9941-DF1FC4E6484A),如果开启 IDFA ,能够优先获取 IDFA,如果获取失败再尝试获取 IDFV。
- 应用 IDFA 能防止用户在重装 App 后设施 ID 发生变化的状况,须要留神的是IDFA 也是能够被重置的
2.2. 登录 ID
- 登录 ID 通常是业务数据库里的主键或其它惟一标识,登录 ID 相对来说更准确更长久。
- 然而,用户在应用时不肯注册或者登录,而这个时候是没有登录 ID 的。
2.3. 平台 ID
- JavaScript
- cookie_id
- 默认状况下应用 cookie_id(例如:15ffdb0a3f898-02045d1cb7be78-31126a5d-250125-15ffdb0a3fa40a),cookie_id 存贮在浏览器的 cookie 中,仍然有被重置的危险
- 这里还有一个问题,就是 cookie 只能隶属于同一个域名,也就是说你拜访邮箱的 cookie ,与百度广的 cookie 并不是同一个,所以在网站与网站也要做 ID Mapping ,这就是为什么你在百度上搜寻了“养生”,到购物网站上就会给你举荐“枸杞”。
- cookie_id
- 微信小程序
- UUID,
- 默认状况下应用 UUID(例如:1558509239724-9278730-00c1875d5f63f8-41373096),然而删除小程序,UUID 会变。
- openid,
- 为了保障设施 ID 不变,倡议获取并应用 openid(例如:oWDMZ0WHqfsjIz7A9B2XNQOWmN3E)。 如果抉择应用 openid 的话,请留神【操作暂存】,因为获取 openid 是一个异步的操作,然而冷启动事件等会先产生,这时候这个冷启动事件的 distinct_id 就不对了。所以咱们会把先产生的操作,暂存起来,等获取到 openid 等后调用 sa.init() 后才会发送数据。 openid 的获取和操作暂存的办法。
- UUID,
2.4. 其他类型 ID
- 账号信息
- 微信账号
- QQ 号
- 邮箱
- 手机号
- deviceid
- app 日志采集埋点开发人员自己定义一种逻辑id,可能取自android、imei、openudid 等,是逻辑上的 id
- MAC(Media Access Control)
- MAC位址,为网卡的标识,唯一标识网络设备。
- IMEI(International Mobile Equipment Identity)
- 通常说的手机序列号、手机“串号”,在移动电话网络中识别每一部独立的手机等行动通讯装置;
- 序列号共有15位数字,前6位(TAC)是型号核准号码,代表手机类型。接着2位(FAC)是最后装配号,代表产地。后6位(SNR)是串号,代表生产顺序号。最后1位(SP)一般为0,是检验码,备用。
- IMSI(International Mobile SubscriberIdentification Number)
- 储存在SIM卡中,区别移动用户的有效信息;其总长度不超过15位,同样使用0~9的数字。其中:
- MCC 是移动用户所属国家代号,占3位数字,中国的MCC规定为460;
- MNC 是移动网号码,最多由两位数字组成,用于识别移动用户所归属的移动通信网;
- MSIN 是移动用户识别码,用以识别某一移动通信网中的移动用户。
- 储存在SIM卡中,区别移动用户的有效信息;其总长度不超过15位,同样使用0~9的数字。其中:
-
Android ID是系统随机生成的设备ID 为一串64位的编码(十六进制的字符串),通过它可以知道设备的寿命(在设备恢复出厂设置或刷机后,该值可能会改变)。
- UDID (Unique Device Identifier)
- 苹果IOS设备的唯一识别码,它由40个字符的字母和数字组成,为了保护用户隐私苹果已经禁止读取这个标识了。
-
UUID(Universally Unique IDentifier),是基于iOS设备上面某个单个的应用程序,只要用户没有完全删除应用程序,则这个 UUID 在用户使用该应用程序的时候一直保持不变。如果用户删除了这个应用程序,然后再重新安装,那么这个 UUID 已经发生了改变。缺点是用户删除了你开发的程序后,基本上无法获取关联之前的数据。
- OpenUDID
- 不是苹果官方的,是一个替代 UDID 的第三发解决方案, 缺点是如果你完全删除全部带有OpenUDID SDK 包的App(比如恢复系统等),那么OpenUDID 会重新生成,而且和之前的值会不同。
- IDFA (广告标示符)
- 苹果禁用UDID后想出了折中办法,就是提供另外一套和硬件无关的标识符,用于给商家监测广告效果,这就是IDFA。
- 用户可以在手机设置里改变这串字符,会导致商家没有办法长期跟踪用户行为。
3. ID Mapping 的难点
3.1. 各个平台和各个设备ID无法直接关联
- 要想关联需要找到关联对象,⽤SQL 举例就是如果要想把 A 和 C 关联起来,必须找到可以同时和它们可以关联起来的B,⽽我们的用户 ID 非常多,所以要想关联起来需要梳理清楚关联关系,且还得写大量的关联代码。
-
3.2. ID 过期问题
- 有些数据可能属于同一个,但在某个阶段上、这些数据之间没有任何联系,那么这类的数据可能会被打上两个不同的标识,也就是说需要在某时刻同时获得这些信息,但是这是非常困难的。
3.3. 异常数据
-
借用朋友设备;
-
记录设备数据格式错误,有脏数据;
-
风控场景:刷号等行为;
4. ID Mapping 的实现
4.1. 物理层 Mapping
- 这是最单纯基本的层面,也就是如何精准地记录和标识一个用户,例如利用硬件设备码生成一个统一的设备码,利用一些强账号来标识用户等等。
-
这个层面上主要的技术难度,在于ID的稳定性、唯一性和持久性。
- 账号对应:
- 按账号优先级的方案实现简单,将系统中所有账号体系的 ID 设定优先级,按照优先级顺序作为用户的唯一标识。
-
美团账号 ID mapping 示例:
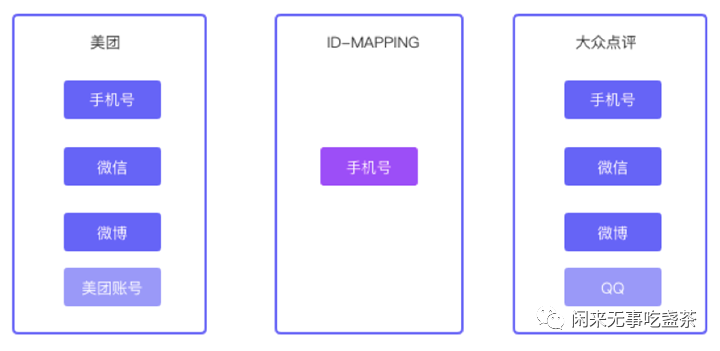
- 缺点:用户多对多等场景下,识别正确率比较低。
4.2. 借助图计算
- 图计算是将数据转为“点集合”,将数据之间的关系转化为“线集合”,通过最短路径规划、频繁子集等算法,形成 id映射字典。
具体步骤:
- 步骤一:根据日志获取 ID 号,获取每一行日志中的全部的 ID 号;
- 数据格式:
Array( Tuple(1, Set("0006")), Tuple(2, Set("0007")), Tuple(3, Set("0006", "0008")), ... Tuple(1000, Set("1000")), )
- 数据格式:
- 步骤二:修改数据格式
- 修改后的数据格式:
0006 1 0007 2 0006 3 0008 3 ... 1000 1000
- 修改后的数据格式:
- 步骤三:分组
- 分组后的数据格式:
0006, {1, 3} 0007, {2} 0008, {3} ... 1000, {1000}
- 分组后的数据格式:
- 步骤四:生成用户关系表
one_id_0001 0006, 0008 one_id_0002 0007 ... one_id_1000 1000 - 步骤五:获取之前的用户标签,合并结果表
0006(user_id_0006) (上海市, 1)(今日头条, 1) 0007(user_id_0007) (北京市, 2)(梨视频, 2)(西瓜视频, 2) 0008(user_id_0008) (上海市, 3)(奔驰用户, 3) ... 1000(user_id_1000) (深圳市, 1000)(抖音, 1000) - 步骤六:合并结果表
one_id_0001 (user_id_0006, user_id_0008) (((上海市, 1)(今日头条, 1)),((上海市, 3)(奔驰用户, 3))) one_id_0002 (user_id_0007, ) (北京市, 2)(梨视频, 2)(西瓜视频, 2) ... one_id_1000 (user_id_1000, ) (深圳市, 1000)(抖音, 1000)
5. ID Mapping 设计经验
5.1. 基于用户兴趣做相似用户的合并
-
如果说物理层面 mapping,主要还在判断标识一个用户的 ID 是否正确,那么层面三致力于把行为相似的用户给合并起来。
-
例如:某一个用户的设备多次连接同一个Wi-Fi网关,但是每次链接都会随机更换ID,那么相当于这个用户的数据“分裂”在多个不同ID下。那么如何把这些ID合并成同一个用户呢?
-
除了上述做法之外,还可以开发了相似用户合并技术。基于用户的上网时间偏好、网址访问偏好、点击行为偏好、浏览行为偏好、APP偏好和社交账号偏好等,为每个用户提取了上千个特征之后,进行相似用户的聚类。
-
聚类中选择类中心附近的用户,再加上一些辅助准则判定,就可以把用户合并起来。
5.2. 基于用户行为做迭代滚动 Mapping
- 由于原始数据存在噪音,同一个用户的多份数据、多种ID之间是“多对多”的关系,那么哪些ID是可信的却无法判断。
- 为此,可以设计置信度传播的机器学习图模型,来帮助确定哪些身份ID是可信的。
- 具体来说,这个算法的过程是给每一个ID,以及两个ID,如IMEI和邮箱之间的pair关系都有一个预设的置信度。
- 所有的ID根据两两关联构成了一张图,那么每个ID的置信度根据这张网的结构传播给相关联的ID,同时也从其他ID那边接收置信度,而pair关系的置信度不变。
- 当算法迭代收敛时,高置信度的ID就是可信的。同一个子图内的ID就标识了同一个用户。用类似的算法,我们也可以评价每个数据源的质量等。
5.3. 解决 ID 过期问题
-
对于僵尸用户,或者长期不用的用户,保存数据没有意义,浪费资源而且数据长期不更新后可能数据不准确。
-
可以对每个ID加入活跃度参数,一方面代表用户的活跃程度,一方面可以对ID的存储做控制。
-
用户行为数据:代表了用户的活跃度,数据入表活跃度设置为0
-
ID Mapping历史数据:按周更新,代表上周用户的数据,迭代计算时,活跃度+1
-
全量用户信息数据:代表全量用户,数据引入时,设置活跃度参数为一个合理值