Hive
Hive 存储标签表
- 适用场景:
- 存储数据相关标签表、人群计算表的表结构设计;
- Hive 数仓:
- 建立用户画像,首先需要建立数据仓库。
- Hive 是基于 Hadoop 的数据仓库工具,依赖于 HDFS 存储数据,提供的 SQL 语言可以查询存储在 HDFS 中的数据。
- 开发时一般使用 Hive 作为数据仓库,存储标签和用户特征库等相关数据。
- Hive 宽表 ETL 花费时间较长
- 如果将用户标签开发成一张大的宽表,在这张宽表下放几十种类型标签,那么每天该画像宽表的 ETL 作业将会花费很长时间,而且不便于向这张宽表中新增标签类型。
- 要解决这种 ETL 花费时间较长的问题,可以从以下几个方面着手:
- 将数据分区存储,分别执行作业;
- 标签脚本性能调优;
- 基于一些标签共同的数据来源开发中间表。
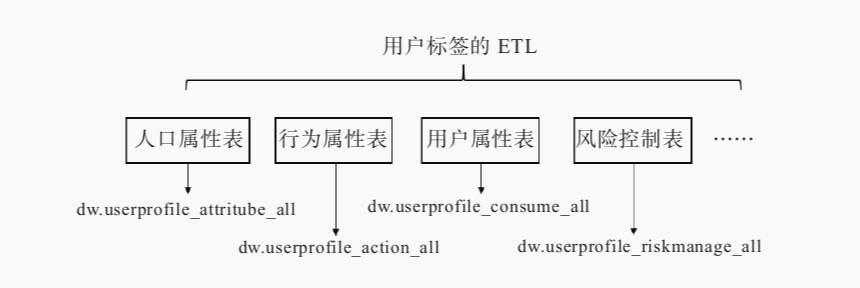
- 分区存储:
- 人口属性表:dw.userprofile_attritube_all;
- 行为属性表:dw.userprofile_action_all;
- 用户消费表:dw.userprofile_consume_all;
- 风险控制表:dw.userprofile_riskmanage_all;
-
社交属性表:dw.userprofile_social_all
-
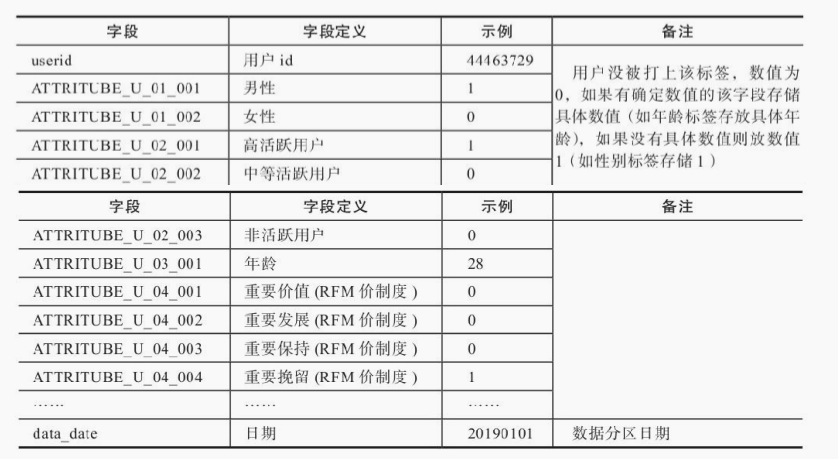
人口属性宽表示例:
- partition 分区提高查询效率:
-实现:
- 为了提高数据的插入和查询效率,在 Hive 中可以使用分区表的方式,将数据存储在不同的目录中。
- 在 Hive 使用 select 查询时一般会扫描整个表中所有数据,将会花费很多时间扫描不是当前要查询的数据,为了扫描表中关心的一部分数据,在建表时引入了 partition 的概念。
- 在查询时,可以通过 Hive 的分区机制来控制一次遍历的数据量。
- 缺点:
- 用户的每个标签都插入到相应的分区下面,但是对一个用户来说,打在他身上的全部标签存储在不同的分区下面。
- 缺点:
Hive 标签汇聚
- 为了方便分析和查询,需要将用户身上的标签做聚合处理;
- 标签汇聚后,一个每个用户身上的全量标签汇聚到一个字段中;
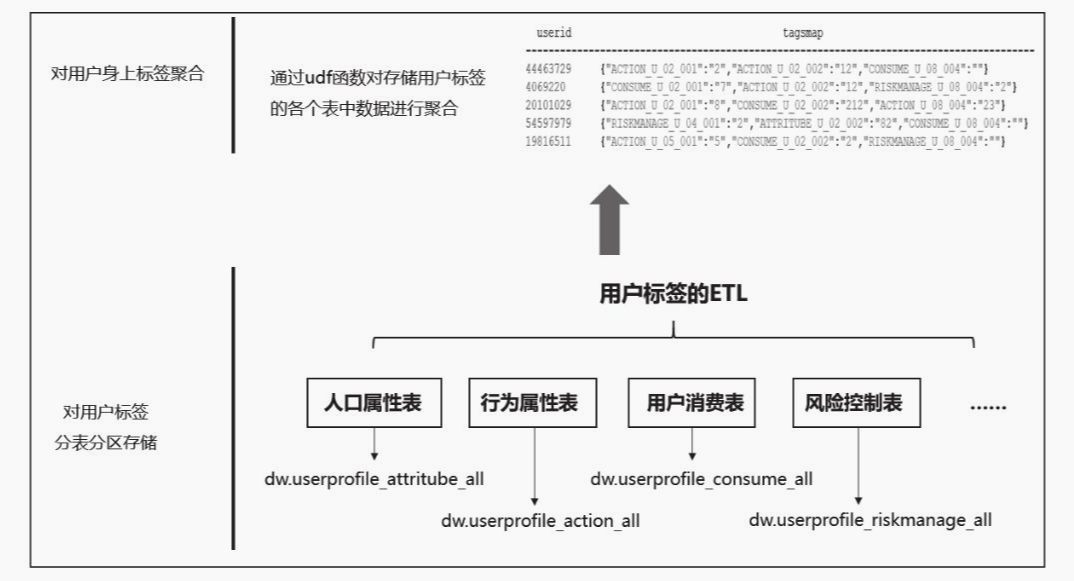
- 标签汇聚表结构设计:
- 标签字段 userlabels 格式为
map<string,string>;
CREATE TABLE `dw.userprofile_userlabel_map_all` ( `userid` string COMMENT 'userid', `userlabels` map<string,string> COMMENT 'tagsmap', ) COMMENT 'userid 用户标签汇聚' PARTITIONED BY ( `data_date` string COMMENT '数据日期') - 标签字段 userlabels 格式为
- 汇聚过程(UDF 函数)
- 将用户身上的标签汇聚成 json 字符串,将按分区存储的标签进行汇聚;
insert overwrite table dw.userprofile_userlabel_map_all partition(data_date= "data_date") select userid, cast_to_json(concat_ws(',',collect_set(concat(labelid,':',labelweight)))) as userlabels from “用户各维度的标签表” where data_date= " data_date " group by userid
- 将用户身上的标签汇聚成 json 字符串,将按分区存储的标签进行汇聚;
-
汇聚后用户标签的存储格式:

- 将用户身上的标签进行聚合便于查询和计算。
- 例如,在画像产品中,输入用户id后通过直接查询该表,解析标签id和对应的标签权重后,即可在前端展示该用户的相关信息;
Hive 拉链表 实现 ID-Mapping
- 适用场景:
- ID-Mapping;
- 用户在未登录 App 的状态下,在 App 站内访问、搜索相关内容时,记录的是设备 id(即cookieid)相关的行为数据。
- 用户在登录 App 后,访问、收藏、下单等相关的行为记录的是账号 id(即userid)相关行为数据。
- 虽然是同一个用户,但其在登录和未登录设备时、记录的行为数据之间是未打通的。
- 通过 ID-MApping 打通 userid 和 cookieid 的对应关系,可以在用户登录、未登录设备时都能捕获其行为轨迹。
- ID-Mapping;
- 实现方式:hive 拉链表
- 通过 Hive 的 ETL 工作完成 ID-Mapping 的数据清洗工作;
- 缓慢变化维是在维表设计中常见的一种方式,维度并不是不变的,随时间也会发生缓慢变化。
- 如用户的手机号、邮箱等信息可能会随用户的状态变化而改变,再如商品的价格也会随时间变化而调整上架的价格。因此在设计用户、商品等维表时会考虑用缓慢变化维来开发。
- 同样,在设计 ID-Mapping 表时,由于一个用户可以在多个设备上登录,一个设备也能被多个用户登录,所以考虑用缓慢变化维表来记录这种不同时间点的状态变化。
MySQL
- MySQL 优点:
- 对于量级较小的数据,MySQL 具有更快的读写速度,查找延迟低;
- 范围查询优势明显, 可以实现复杂的查询;
- MySQL 缺点:
- 随着数据的增多, 插入性能递减;
- 完整存储所有数据, 不适合稀疏表。
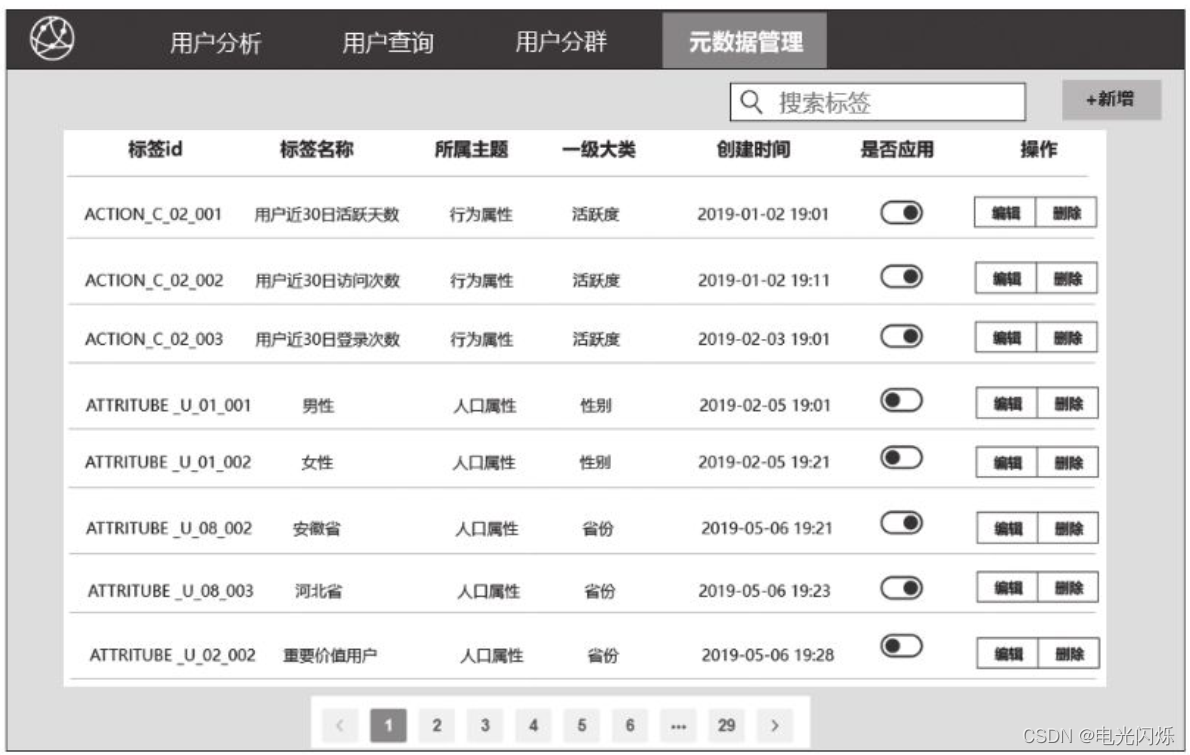
MySQL 存储标签元数据
- 适用场景:
-
存储标签元数据、监控数据;
-
- 工作原理:
- MySQL 作为关系型数据库,在用户画像中可用于元数据管理、监控预警数据、结果集存储等应用中。
- 相比于 Hive 适合于大数据量的批处理作业,对于量级较小的数据,MySQL 具有更快的读写速度。Web 端产品读写 MySQL 数据库会有更快的速度,方便标签的定义、管理。
MySQL 存储 ETL 监控信息
- 适用场景:
- 存储服务层同步监控数据,存储每天对 ETL 结果的监控信息。
- 工作原理:
- 将标签相关数据从Hive数仓向服务层同步的过程中,有出现差错的可能,因此需要记录相关数据在Hive中的数量及同步到 对应服务层后的数量,如果数量不一致则触发告警。
- 在对画像的数据监控中,调度流每跑完相应的模块,就将该模块的监控数据插入MySQL中,当校验任务判断达到触发告警阈值时,发送告警邮件,同时中断后续的调度任务。待开发人员解决问题后,可重启后续调度。
- 从整个画像调度流的关键节点来看,需要监控的环节主要包括对每天标签的产出量、服务层数据同步情况的监控等主要场景。
- 用户标签系统的服务层,一般采用 HBase、Elasticsearch 等作为数据库存储标签数据供线上调用,将标签相关数据从 Hive 数仓向服务层同步的过程中,有出现差错的可能;
- 因此需要使用 MySQL 记录相关数据在 Hive 中的数量,及同步到对应服务层后的数量,如果数量不一致则触发告警。
MySQL 存储标签数据结果集
- 适用场景:
- 存储标签数据结果集;
- 电商、保险、金融等公司的客服部门的日常工作内容之一,是对目标用户群(如已流失用户、高价值用户等)进行主动外呼,以此召回用户来平台进行购买或复购,需要将 Hive 中存储的与用户身份相关的数据同步到客服系统中。
- 实现方式:
-
使用 Sqoop 将 Hive 中的标签数据迁移到 MySQL
# -*- coding: utf-8 -*- import os import MySQLdb import sys def export_data(hive_tab, data_date): sqoop_command = "sqoop export --connect jdbc:mysql://10.xxx.xxx.xxx:3306/mysql_database --username username --password password --table mysql_table --export-dir hdfs://nameservice1/user/hive/warehouse /dw.db/" + hive_tab + "/data_date=" + data_date + " --input-fields-terminated-by '\001'" os.system(sqoop_command) print(sqoop_command) if __name__ == '__main__': export_data("dw.userprofile_userservice_all", '20181201')sqoop export --connect 指定JDBC连接字符串,包括IP 端口 数据库名称 \ --username JDBC连接的用户名\ --passowrd JDBC连接的密码\ --table 表名\ --export-dir 导出的Hive表, 对应的是HDFS地址 \ --input fileds-terminated-by ‘,’ 分隔符号
-
Hbase 存储标签
- 适用场景:
- 存储线上接口实时调用的数据;
- Hbase 优点:
- HBase 是 KV 型数据库, 是不需要提前预设 Schema 的,添加新的标签时候比较方便
- 列式存储
- 标签经常变化不固定
- 标签随业务变化比较大
- 标签经常增加
- 画像的数据量不小, HBase 可以存储海量数据;
- 工作原理:
- HBase 是一个高性能、列存储、可伸缩、实时读写的分布式存储系统,同样运行在 HDFS 之上。
-
与 Hive 不同的是,HBase 能够在数据库上实时运行,而不是跑 MapReduce 任务,适合进行大数据的实时查询。
- row key:
- 用来表示唯一一行记录的主键,HBase 的数据是按照 row key 的字典顺序进行全局排列的。
- Rowkey 设计时需要遵循三大原则:
- 唯一性原则:
- rowkey 需要保证唯一性,不存在重复的情况。
- 在用户画像系统中一般使用 用户 id 作为 rowkey。
- 长度原则:
- rowkey 的长度一般为 10-100 bytes。
- 散列原则:
- rowkey 的散列分布有利于数据均衡分布在每个 RegionServer,可实现负载均衡。
- 唯一性原则:
- columns family:
- 指列簇,HBase 中的每个列都归属于某个列簇。
- 列簇是表的 schema 的一部分,必须在使用表之前定义。
- 划分 columns family 的原则如下:
- 是否具有相似的数据格式;
- 是否具有相似的访问类型。
- 访问 HBase 中的行只有 3种 方式:
- 通过单个 row key 访问;
- 通过 row key 的正则访问;
- 全表扫描。
- 由于 HBase 通过 rowkey 对数据进行检索,而 rowkey 由于长度限制的因素,不能将很多查询条件拼接在 rowkey 中,因此 HBase 无法像关系数据库那样、根据多种条件对数据进行筛选。
- 一般地,HBase 需建立二级索引、来满足根据复杂条件查询数据的需求。
- 一级缓存: BlockCache
- MySQL 的 B+树 并不是把数据直接存放在树中, 而是把数据组成 页(Page) 然后再存入 B+树, MySQL 中最小的数据存储单元是 Page
- HBase 也一样, 其最小的存储单元叫做 Block, Block 会被缓存在 BlockCache 中, 读数据时, 优先从 BlockCache 中读取
- BlockCache 是 RegionServer 级别的
- BlockCache 叫做读缓存, 因为 BlockCache 缓存的数据是读取返回结果给客户端时存入的
- 二级缓存:
- 当查找数据时, 会先查内存, 后查磁盘, 然后汇总返回
- 因为写是写在 Memstore 中, 所以从 Memstore 就能立刻读取最新状态
- Memstore 没有的时候, 扫描 HFile, 通过布隆过滤器优化读性能
- HBase ETL 校验机制
- 同步问题
- 灌入到 hbase 中的数据一般直接应用到线上,反馈到用户那里;
- 所以在 hive 数据同步 hbase 数据的时候,需要做一些校验机制来保障结果的准确性;
- 防止在同步数据的过程中出现问题(比如hive中数据5000万条,同步到 hbase后才1000万条)
- 解决方案一:temp 临时表
- hive 到 hbase 同步数据后,先在 hbase 中建立一个 temp 临时表,然后校验 hbase 的这个临时表和对应 hive 表的数量差异;
- 如果在可接受范围内,则将hbase的该临时表进行重命名为正式表;
- 解决方案二:标志状态位
- hive 到 hbase 同步数据后,直接将数据写入正式表;
- 同时,在 hbase 中建立一张状态表,用于标志状态位;
- 当校验 hbase 的这张正式表和 hive 的数量差异在可接受范围内时,写入对应的状态表中。
- 接口请求时,只读取状态位这张表中,最近日期的那张表;
- 所以如果 hbase 的数据同步异常,不会写入状态表中,也不会影响线上数据的读取;
- 同步问题
Elasticsearch
Elasticsearch 实现标签查询、人群计算、用户群多维透视分析
- 适用场景:
- 存储标签用于用户标签查询、用户人群计算、用户群多维透视分析;
- 工作原理:
- Elasticsearch 是一个开源的分布式全文检索引擎,由于使用倒排索引机制,可以近乎实时地存储、检索数据,而且可扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
- 对于用户标签查询、用户人群计算、用户群多维透视分析这类对响应时间要求较高的场景,也可以考虑选用 Elasticsearch 进行存储。
- Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档,用 json 作为文档格式。
- 在关系型数据库中查询数据时可通过选中数据库、表、行、列来定位所查找的内容,在 Elasticsearch 中通过索引(index)、类型(type)、文档(document)、字段来定位查找内容。
- 一个 Elasticsearch 集群可以包括多个索引(数据库),也就是说其中包含了很多类型(表),这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。
Elasticsearch 存储 HBase 的索引,支持多条件复杂查询。
- 适用场景:
- 采用 Elasticsearch 存储 HBase 的索引信息,以支持复杂的多条件查询功能。
- 工作原理:
- 基于 HBase 的存储方案并没有解决数据的高效检索问题。
- 在实际应用中,经常有根据特定的几个字段进行组合后检索的应用场景,而 HBase 采用 rowkey 作为一级索引,不支持多条件查询;
- 如果要对库里的非 rowkey 进行数据检索和查询,往往需要通过 MapReduce 等分布式框架进行计算,时间延迟上会比较高,难以同时满足用户对于复杂条件查询和高效率响应这两方面的需求。
- 为了既能支持对数据的高效查询,同时也能支持通过条件筛选进行复杂查询,需要在 HBase 上构建二级索引,以满足对应的需要。
- 采用 Elasticsearch 存储 HBase 的索引信息,就可以支持复杂高效的查询功能。主要查询过程包括:
- 在 Elasticsearch 中存放用于检索条件的数据,并将 rowkey 也存储进去;
- 使用 Elasticsearch 的 API 根据组合标签的条件查询出 rowkey 的集合;
- 使用上一步得到的 rowkey 去 HBase 数据库查询对应的结果。
- HBase 数据存储数据的索引放在 Elasticsearch 中,实现了数据和索引的分离。
- 在 Elasticsearch 中 documentid 是文档的唯一标识,在 HBase 中 rowkey 是记录的唯一标识。
- 在工程实践中,两者可同时选用用户在平台上的唯一标识(如 userid 或 deviceid)作为 rowkey 或documentid,进而解决 HBase 和 Elasticsearch 索引关联的问题。
Spark Streaming 流式标签存储
- 适用场景
- 流式标签存储;
- 工作原理
- Spark Streaming 是 Spark Core API 的扩展,支持实时数据流的处理,并且有可扩展、高吞吐量、容错的特点。
-
数据可以从 Kafka、Flume 等多个来源获取,可以使用 map、reduce、window 等多个高级函数对业务逻辑进行处理。最后,处理后的数据被推送到文件系统、数据库等。
- Spark Streaming 接收实时数据流,并将数据分成多个 batch 批次,然后由 Spark 引擎进行处理,批量生成结果流。
- Spark Streaming 提供了一个高层抽象,称为 Discretized Stream 或 Dstream,它表示连续的数据流。
- Dstream 可以通过 Kafka、Flume 等来源的数据流创建,也可以通过在其他 Dstream 上应用高级操作来创建。
- Kafka
- Kafka 的核心功能是作为分布式消息中间件。
- Kafka 集群由多个 Broker server 组成,其中:
- 消息的发送者称为 Producer;
- 消息的消费者称为 Consumer;
- Broker 是消息处理的节点,多个 Broker 组成 Kafka 集群;
- Topic 是数据主题,用来区分不同的业务系统,消费者通过订阅不同的 Topic 来消费不同主题的数据;
- 每个 Topic 又被分为多个 Partition,Partition 是 topic 的分组,每个 Partition 都是一个有序队列;
- offset 用于定位消费者在每个 Partition 中消费的位置。
- Kafka 对外使用 Topic 概念,生产者向 Topic 里写入消息,消费者从 Topic 中读取消息。
- 一个 Topic 由多个 Partition 组成。
- 生产者向 Brokers 指定的 Topic 中写消息,消费者从 Brokers 里面拉取指定的 Topic 消息,然后进行业务处理。
- Spark Streaming 可以通过 Receiver 和 Direct 两种模式来集成 Kafka。
- 在 Receiver 模式下,Spark Streaming 作为 Consumer 拉取 Kafka 中的数据,将获取的数据存储在 Executor 内存中。
- 但可能会因为数据量大而造成内存溢出,所以启用预写日志机制(Write AheadLog)将溢出部分写入到 HDFS 上。
- 在接收数据中,当一个 Receiver 不能及时接收所有的数据时,再开启其他 Receiver 接收。它们必须属于同一个 Consumer Group,这样可以提高 Streaming 程序的吞吐量(如图4-21所示)。
- 整体来说,Receiver模式效率较低,容易丢失数据,在生产环境中使用较少。